1. 단변량이란?
- 하나의 변수만을 분석하는 방법
- 하나의 변수에 대한 불포, 중심 경향성, 변산성 등을 분석하여 해당 변수의 특성을 파악하는 것을 단변량 분석이라고 함
2. 단변량 분석 - 숫자형
숫자형 변수를 정리하는 것은 크게 두가지가 있다
1. 숫자로 요약하기 : 정보의 대푯값 -> 기초통계량
2. 구간 나누고 빈도수 계산 -> 도수분포표
2.1 숫자로 요약하기(기초 통계량)
- 평균 (data.mean())
- 산술평균
- 기하평균
- 조화평균
- 중앙값 (data.median())
- 자료상에서 가운데에 위치한 값
- 최빈값(data.mode())
- 자료상에서 가장 빈번한 값
- 사분위수
- 데이터를 오름차순으로 정렬한 전체를 4등분 하고, 각 경계에 해당되는 값(25%,50%,75%)을 나타냄
대표값을 사용할때 주의할 점!
대푯값이 모든 데이터를 대변하기에는 어렵다
기초통계량
- 숫자 몇 개로 분포를 요약 (df.describe())
- count : 데이터 개수
- 사분위수
- 25%: 1사분위수
- 50%: 2사분위수
- 75%: 3사분위수
2.2 구간을 나누고 빈도수 계산(도수분포표)
- 숫자형 변수 시각화
- 기초 통계량 -> 사분위수 (box plot)
- 도수분포표 -> histogram, density plot(KDE)
2.2.1 히스토그램(histogram)
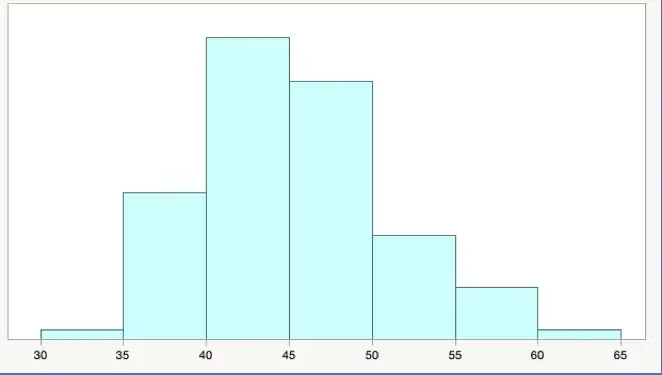
- plt.hist(변수명, bins=빈도수)
- edgecolor: bar의 윤곽선을 색으로 표시
- 히스토그램을 그릴때! bins를 적절히 조절
2.2.2 밀도함수그래프 (Density Plot/KDE Plot)
-
히스토그램의 단점
- 구간(bin)의 너비에 따라 모양이 달라짐
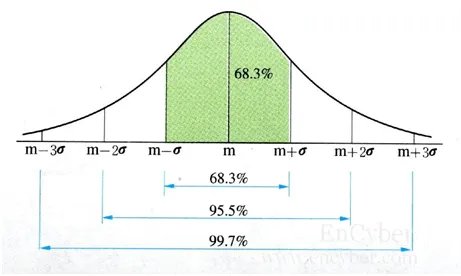
밀도함수 그래프
- 구간의 너비를 정하지 않아도 됨
- 데이터의 밀도 추정 (Kener Density Estimation)
- 밀도 함수 그래프 아래 면적은 1
- 면적으로 간간에 대한 확률 추정
- sns.kdeplot(data='변수명')
2.2.3 Box Plot
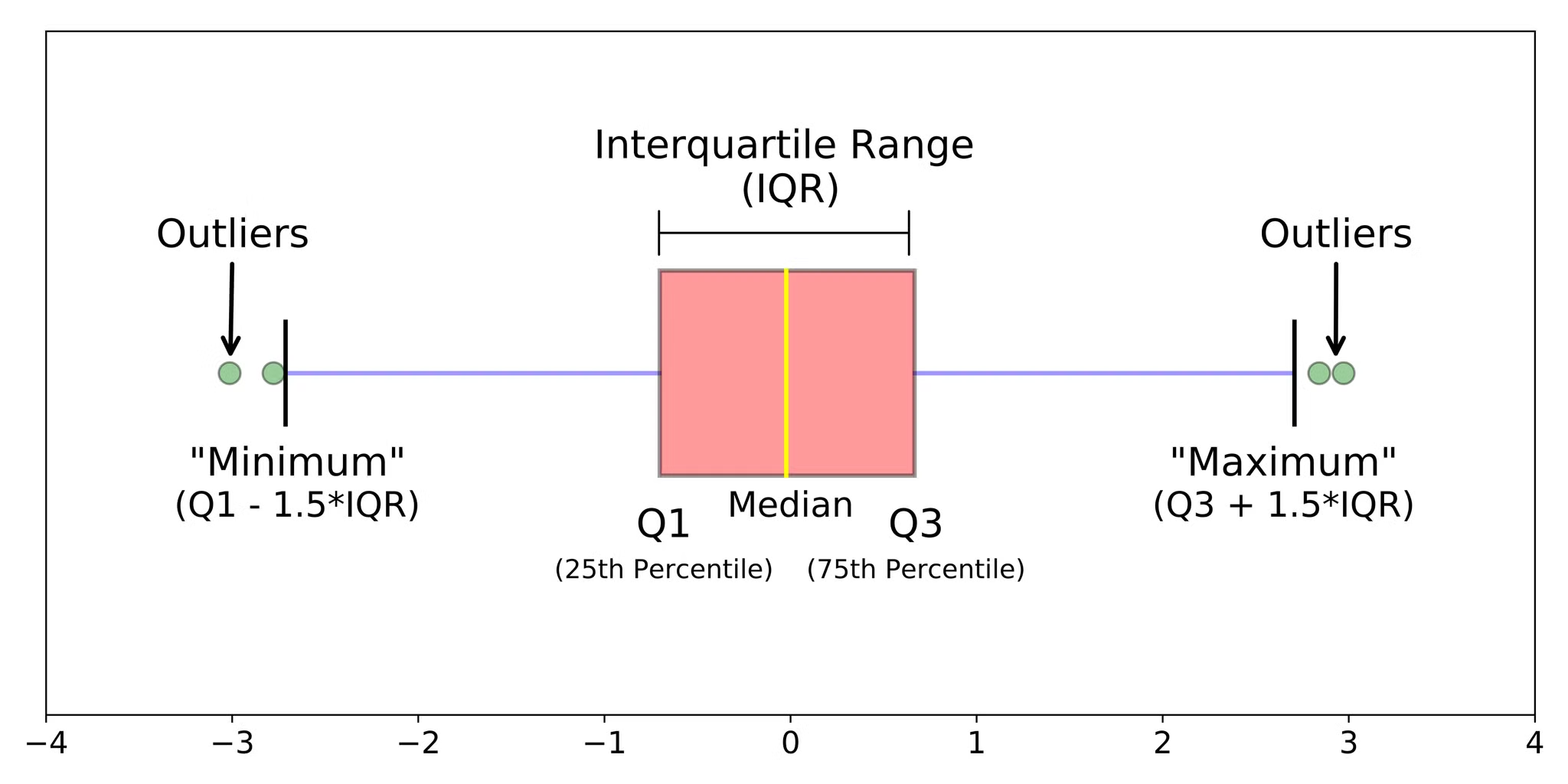
- plt.boxplot()
- 사전에 반드시 결측값 제거 (sns.boxplot은 알아서 제거해줌)
- vert 옵션 : 횡(False),종(True, 기본값)
- Actual Whisker Length : 1.5*IQR 범위 이내 최소, 최대값으로 결정
- Potential Whisker Length : 1.5*IQR 범위, 잠재적 수염의 길이 범위
3. 단변량 분석 - 범주형
범주형 변수 정리방법
- 범주형 개수를 세면 됨(범주별 빈도수, 범주별 비율)
- 범주형 빈도수 : data['변수'].value_counts()
- 범주형 비율 : data[변수'].value_counts(normalize=True)
- 범주형 변수 시각화(bar plot)
- sns.countplot
- 알아서 범주별 빈도수가 계산
- bar plot으로 그려짐
- plt.bar의 경우 직접 범주별 빈도수를 계산하고 그 결과를 입력해야함
- sns.countplot

안녕하세요