KT 에이블스쿨
1.KT 에이블스쿨-1. Git과 Github

드디어 에이블스쿨 첫 수업! 첫 수업으로는 Git에 대해 배웠다 강사님은 생활코딩의 이고잉 강사님이셨다:) 1. git와 github git이란 분산 버전 관리 시스템으로, 파일의 변경사항을 확인하고 협업할때 사용자들 간에 파일에 대한 작업을 조율하는데 사용한다 깃을
2.KT 에이블스쿨 - 2. Numpy와 Pandas
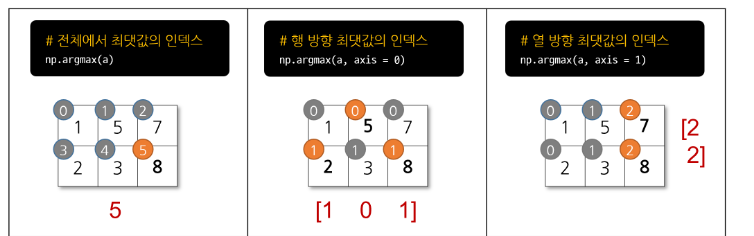
2번째로는 파이썬 문법을 간략히와 가장 중요한 라이브러리인 numpy와 pandas를 학습하는 시간을 가졌다.파이썬 문법은 알기 때문에 넘어가고 Numpy와 pandas를 사용만 했지 정확히 공부한적은 없어서 정리하고자 한다.라이브러리 불러오는 방법axis : 배열의
3.KT 에이블스쿨 - 3. 데이터 처리
columns 속성 변경 : 모든 열 이름 변경 \- 예시 ) tips.columns='열 이름1','열 이름2' (단, 이 경우 열 개수가 모두 맞게 조정해야함) rename 메소드 : 지정한 열 이름 변경 \- tip.rename({열 이름 : 새 열 이름})
4.KT 에이블스쿨 - 4. 시계열 데이터 처리
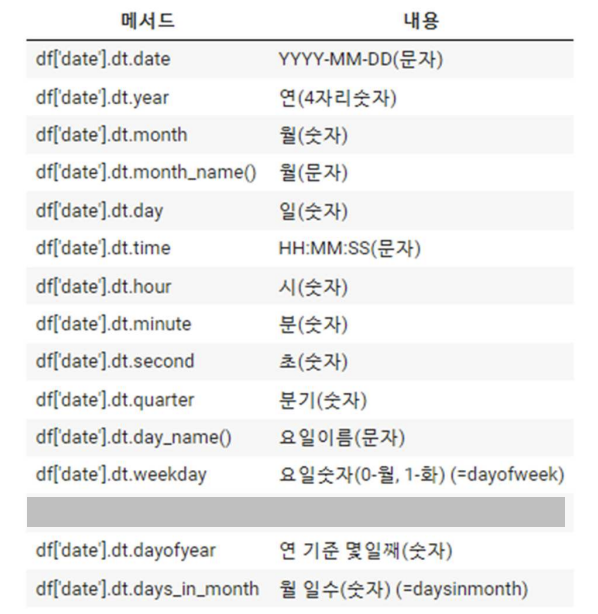
행과 행에 시간의 순서가 있고행과 행의 시간 간격이 동일한 데이터.shift()시계열 데이터에서 시간의 흐름 전후로 정보를 이동시킬때 이용df.shift(7).rolling.mean()시간의 흐름에 따라 일정 기간 동안 평균을 이동하면서 구하기df.rolling(3,m
5.KT 에이블스쿨 - 5. 데이터분석 방법론과 시각화

1. CRIPS-DM (비즈니스 문제해결 방법론) 1.1 Business Understanding - 가설 수립 문제를 정의하고 요인을 파악하기 위해서 가설을 수립 귀무 가설 : 기존 연구 결과로 이어져 내려오는 정설 대립 가설 : 기존의 입장을 넘어서기 위하 새로운
6.KT 에이블스쿨 - 6. 단변량 분석 - 숫자형과 범주
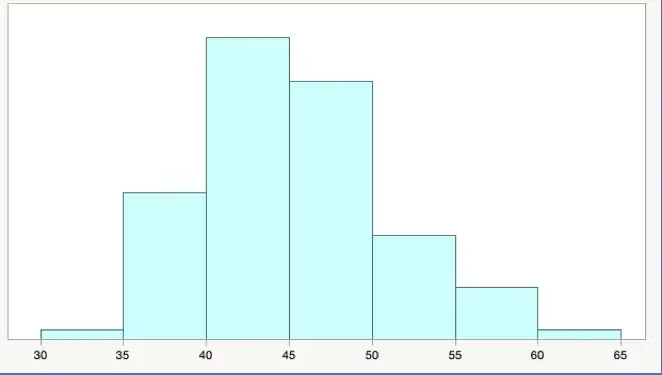
하나의 변수만을 분석하는 방법하나의 변수에 대한 불포, 중심 경향성, 변산성 등을 분석하여 해당 변수의 특성을 파악하는 것을 단변량 분석이라고 함숫자형 변수를 정리하는 것은 크게 두가지가 있다1\. 숫자로 요약하기 : 정보의 대푯값 -> 기초통계량2\. 구간 나누고 빈
7.KT 에이블스쿨 - 7. 가설 검정
모집단 : 우리가 알고 싶은 대상 전체 영역(데이터)표본 : 그 대상의 일부 데이터우리는 일부분으로 전체를 추정하고자 한다모집단에 대한 가설 수립가설은 보통 X와Y의 관계 표현X에 따라 Y가 차이가 있다X와 Y는 관계가 있다표본을 가지고 가설이 진짜 그러한지 검증예시
8.KT 에이블스쿨 - 8. 이변량 분석 : 숫자와 숫자 & 평균추정과 신뢰 구간
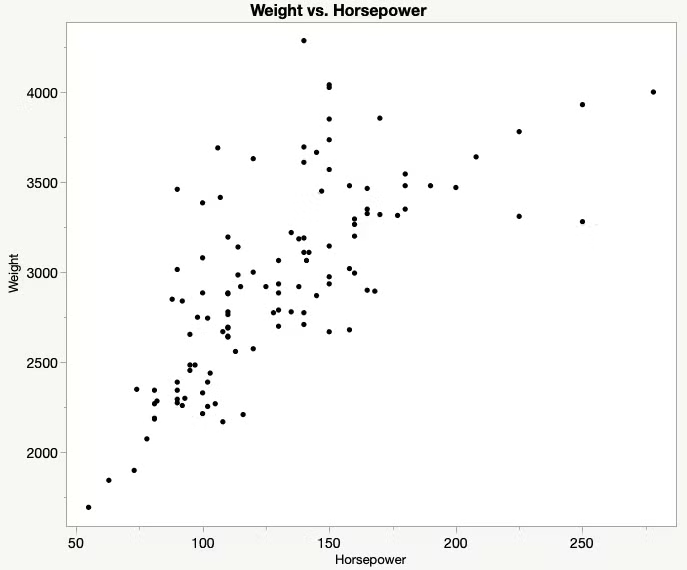
두 개의 변수 간의 관계를 분석하는 통계적 방법두 변수가 어떻게 서로 연관되어 있는지, 상관관계나 의존성을 확인하는데 사용목적하나의 변수가 다른 변수에 미치는 영향을 평가하는 것이를 통해 변수 간의 상관 관계나 원인 - 결과 관계를 탐구할 수 있음그대로 점을 찍어서 그
9.KT 에이블스쿨 - 9. 이변량 분석(범주&숫자, 범주&범주, 숫자&범주)
평균 비교 : barplot범주가 2개 : 두 평균의 차이 비교범주가 3개 이상 : 전체 평균과 각 범주의 평균 비교sns.barplot() : 평균비교신뢰구간(오차범위)평균값이 얼마나 믿을만한가?좁을수록 믿을만하다데이터가 많을수록, 편차가 적을수록 신뢰구간은 좁아짐두
10.KT 에이블스쿨 - 10. 머신러닝
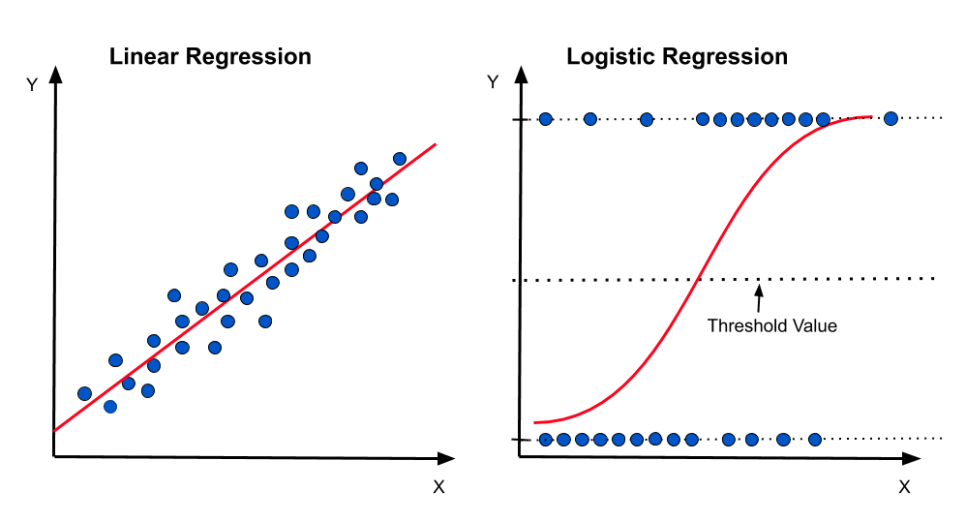
1. 결측치 확인 및 제거 결측치 확인 방법 : data.isna().sum() 평균값으로 채우기 : 평균값 먼저 구하고 data.fillna(평균값 변수,inplac=True) 앞뒤 값으로 채우기 이 방법은 시계열 데이터에 자주 사용됨 data['변수이름']
11.KT 에이블스쿨 - 11. 딥러닝

1. 모델과 모델링 Model 데이터로부터 패턴을 찾아, 수학식으로 정리해 놓은 것 * 모델링 * 가능한 한 오차가 적은 모델을 만드는 과정 모델의 목적 샘플을 가지고 전체를 추정 최적의 모델 가능한 한 오차가 가장 작은 모델 2. 딥러닝 머신러닝의