🧐 Centrality algorithms
네트워크에서 개별 노드의 중요도를 결정하는데 사용하는 알고리즘
1. Page Rank
PageRank 알고리즘은 연결된 관계의 수와 소스 노드의 중요성에 기초하여, 그래프 내에서 노드의 중요도를 측정한다.
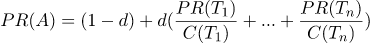
PR(A) : 'A’라는 웹페이지의 페이지 랭크(PageRank)
T1, T2, … Tn : 그 페이지를 가리키는 다른 페이지들. PR(T1)는 'T1'이라는 페이지의 페이지 랭크.
d(Damping Factor) 어떤 마구잡이로 웹서핑을 하는 사람이 그 페이지에 만족을 못하고 다른 페이지로 가는 링크를 클릭할 확률. 실험을 통해 0과 1 사이의 어떤 값으로 정해지는데, 보통 '0.85'
C(T1) : 'T1'이라는 페이지가 가지고 있는 링크의 총 갯수
PR(A)는 A라는 페이지를 가리키고 있는 다른 페이지의 PageRank가 높을수록 더 높다.
단순히 A 페이지 링크를 가지고 있는 다른 페이지의 PageRank가 높아야만 하는 것은 아니고, 그 페이지에 링크된 페이지가 너무 많으면 그 페이지가 PR(A)에 기여하는 비중은 낮아진다.
2. Betweenness Centrality

Betweenness Centrality는 노드가 그래프의 정보 흐름에 미치는 영향의 정도를 감지하는 방법이다. 즉, 특정 노드가 다른 노드들 사이의 관계에서 얼마나 중요한 지를 나타낸다.
이 알고리즘은 너비 우선 탐색(BFS, Breadth-First Search)을 사용하여 연결된 그래프의 모든 노드 쌍 사이의 최단 경로를 계산한다. 각 노드는 그 노드를 통과하는 최단 경로의 수에 따라 점수를 받는다. 따라서 최단 경로에 가장 자주있는 노드는 더 높은 점수를 갖는다.
🙉 Practice in Neo4j!
1) 데이터 생성
- 서로 연결된 8개의 페이지를 나타내는 그래프를 추가
- 각 관계에는 중요성을 나타내는 weight라는 속성이 있다.
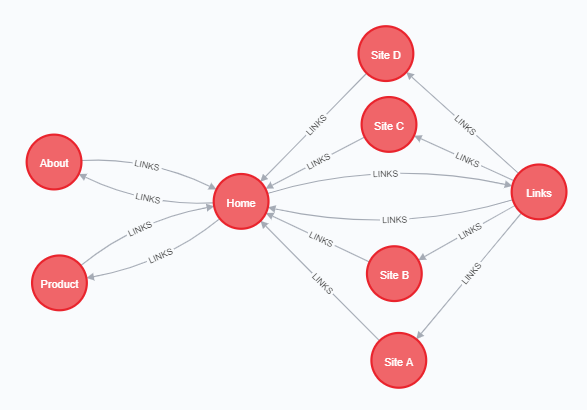
CREATE
(home:Page {name:'Home'}),
(about:Page {name:'About'}),
(product:Page {name:'Product'}),
(links:Page {name:'Links'}),
(a:Page {name:'Site A'}),
(b:Page {name:'Site B'}),
(c:Page {name:'Site C'}),
(d:Page {name:'Site D'}),
(home)-[:LINKS {weight: 0.2}]->(about),
(home)-[:LINKS {weight: 0.2}]->(links),
(home)-[:LINKS {weight: 0.6}]->(product),
(about)-[:LINKS {weight: 1.0}]->(home),
(product)-[:LINKS {weight: 1.0}]->(home),
(a)-[:LINKS {weight: 1.0}]->(home),
(b)-[:LINKS {weight: 1.0}]->(home),
(c)-[:LINKS {weight: 1.0}]->(home),
(d)-[:LINKS {weight: 1.0}]->(home),
(links)-[:LINKS {weight: 0.8}]->(home),
(links)-[:LINKS {weight: 0.05}]->(a),
(links)-[:LINKS {weight: 0.05}]->(b),
(links)-[:LINKS {weight: 0.05}]->(c),
(links)-[:LINKS {weight: 0.05}]->(d);2) "myGraph"라는 이름의 그래프 생성
CALL gds.graph.create(
'myGraph',
'Page',
'LINKS',
{
relationshipProperties: 'weight'
}
)3) 페이지 랭크를 측정하여 값이 큰 것부터 정렬하고, 점수와 이름 출력
CALL gds.pageRank.stream('myGraph')
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC, name ASC4) 관계 가중치를 사용하여 페이지 랭크 측정
CALL gds.pageRank.stream('myGraph', {
maxIterations: 20,
dampingFactor: 0.85,
relationshipWeightProperty: 'weight'
})
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC, name ASC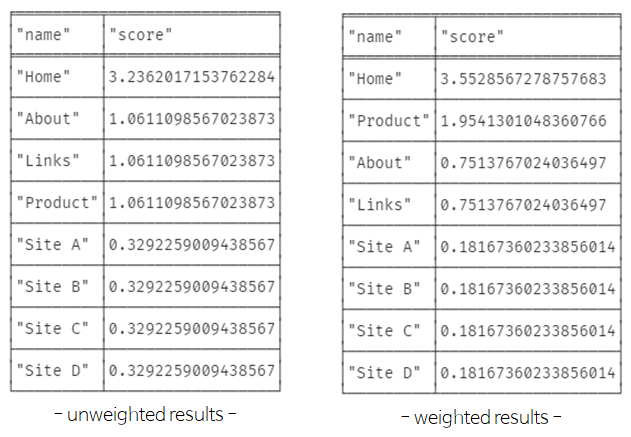
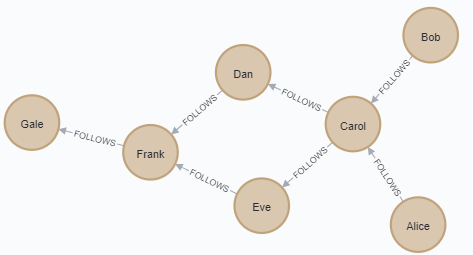
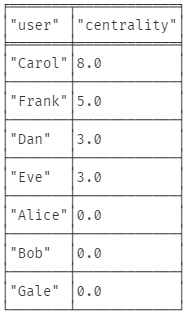
5) 각 노드의 매개 중심성 점수 구하기
CALL gds.alpha.betweenness.stream({
nodeProjection: 'User',
relationshipProjection: 'FOLLOWS'
})
YIELD nodeId, centrality
RETURN gds.util.asNode(nodeId).name AS user, centrality
ORDER BY centrality DESC