
Cypher?
cypher는 Neo4j사에서 만든 선언적 그래프 질의어이다. Property Graph 모델에 기반을 두며, 노드와 엣지의 표준 그래프 요소들에 레이블(label)과 프로퍼티(property)를 추가해서 데이터베이스화 할 수 있다.
1. CREATE
- 데이터 생성
- () : Node (변수:라벨)
- {} : 속성 {프로퍼티:값}
- [] : 관계
- 다수의 노드를 한 번에 추가할 때는 ,로 구분
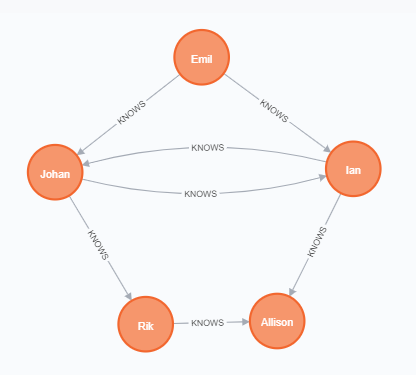
CREATE (ee:Person { name: "Emil", from: "Sweden", klout: 99 }),
(js:Person { name: "Johan", from: "Sweden", learn: "surfing" }),
(ir:Person { name: "Ian", from: "England", title: "author" }),
(rvb:Person { name: "Rik", from: "Belgium", pet: "Orval" }),
(ally:Person { name: "Allison", from: "California", hobby: "surfing" }),
(ee)-[:KNOWS {since: 2001}]->(js),(ee)-[:KNOWS {rating: 5}]->(ir),
(js)-[:KNOWS]->(ir),(js)-[:KNOWS]->(rvb),
(ir)-[:KNOWS]->(js),(ir)-[:KNOWS]->(ally),
(rvb)-[:KNOWS]->(ally)2. MATCH
- 노드(Node), 관계(Relationship)의 패턴을 이용하여 데이터 검색
2-1. 모든 노드 찾기
MATCH (n) RETURN n2-2. 특정 프로퍼티를 가진 노드 찾기
- MATCH (변수:LABEL {PROPERTY:VALUE}) RETURN 결과
- 여러 개의 조건은 ,로 구분: { PROPERTY1:VALUE1, PROPERTY2:VALUE2 } - MATCH (변수:LABEL) WHERE PROPERTY = VALUE RETURN 결과
- WHERE절의 조건은 AND, OR 연산자 사용
MATCH (n:Person {name:"Emil"}) RETURN n;
MATCH (n:Person) WHERE name = "Emil" RETURN n;
2-3. 연결된 노드 찾기
- MATCH (NODE1)-[RELATIONSHIP]-(NODE2) RETURN
- 방향 지정 가능 : MATCH (NODE1)-[RELATIONSHIP]->(NODE2) RETURN
MATCH (ee:Person)-[:KNOWS]-(friends) WHERE ee.name = "Emil" RETURN ee, friends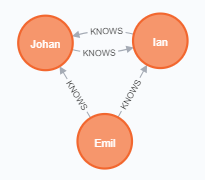
2-4. Functions
- 존재 여부 : [NOT] EXISTS(pattern-or-property)
// from 프로퍼티가 있는 Person 조회
MATCH (ee:Person) WHERE exists(ee.from) RETURN ee-
Aggregating functions
- 합계: sum()
- 평균: avg()
- 개수: count()
- 리스트로 반환: collect()
- 최대값, 최소값: max(), min()
-
String matching functions
- 시작 문자(대소문자 구분): STARTS WITH 'text'
- 종료 문자(대소문자 구분): ENDS WITH 'text'
- 글자 포함: CONTAINS 'text'
- 정규식: =~ 'regular_expresstion' ( 대소문자 무시: (?i) 추가 )
- 리스트에 포함: IN ['text1', ..., 'textN']
2-5. 기타
- 중복제거: RETURN DISTINCT 변수
- 정렬: ORDER BY 변수 [DESC]
- 결과 행 제한: SKIP 숫자 LIMIT 숫자
MATCH (ee:Person)-[:KNOWS]-(friends) WHERE ee.name = "Ian"
RETURN DISTINCT friends.name, friends.from
ORDER BY friends.name
SKIP 1 LIMIT 2
3. SET
- 기존에 생성한 노드나 관계에 새로운 프로퍼티를 추가하거나 기존 값을 변경
MATCH (ee:Person {from:"Sweden"}) SET ee.age = 30 RETURN ee
4. REMOVE & DELETE
4-1. REMOVE
- 특정 노드의 label이나 프로퍼티 삭제
MATCH (ee:Person {name:"Ian"}) REMOVE ee.title RETURN ee
4-2. DELETE
- 특정 노드를 찾아 그 노드를 삭제하거나 관계를 삭제
- 특정 노드를 찾아 그 노드와 연결된 관계를 모두 삭제할 때는 DETACH DELETE 사용
MATCH (ee:Person {name:"Rik"}) DETACH DELETE ee
5. INDEX & CONSTRAINT
- 보다 효율적인 검색을 위하여 INDEX와 CONSTRAINT를 사용
5-1. INDEX
- 생성: CREATE INDEX ON :Label(prop1, …, propN)
CREATE INDEX ON :Person(name)-
조회: CALL db.indexes

-
삭제: DROP INDEX ON :Label(prop1, …, propN)
DROP INDEX ON :Person(name)5-2. CONSTRAINT
- 생성
// 레이블이 Person인 노드에 name 값을 UNIQUE한 값으로..
CREATE CONSTRAINT ON (ee:Person) ASSERT ee.name IS UNIQUE-
조회: CALL db.constraints

-
삭제
DROP CONSTRAINT ON (ee:Person) ASSERT ee.name IS UNIQUE