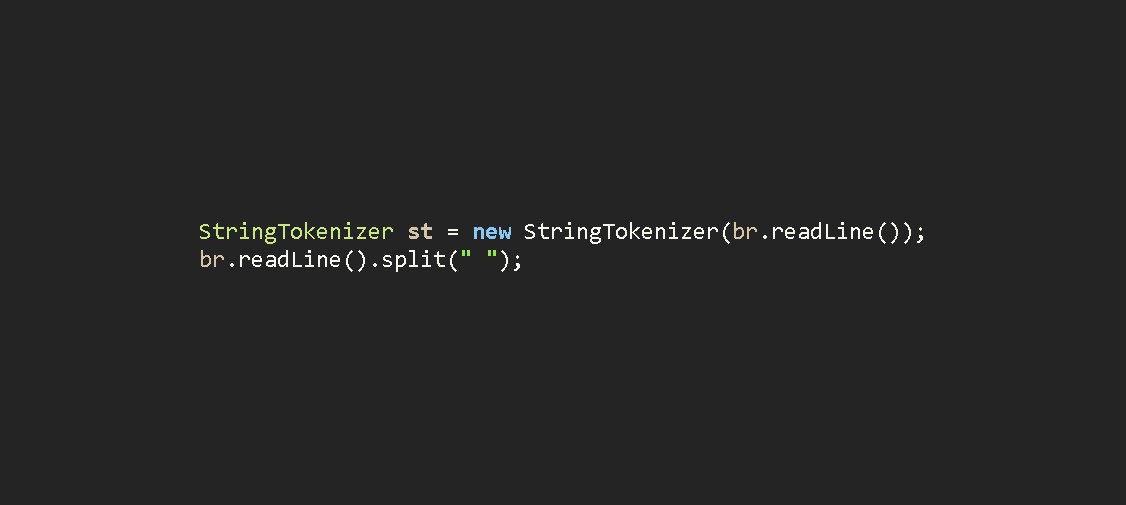
시작글
일반적으로 문자열을 자를 때 StringTokenizer와 String클래스의 split메소드를 사용한다.
알고있기로는 StringTokenizer가 미세하게 좀 더 빠르다고 알고있는데, 왜 그런지, 또 토큰이란게 정확하게 무엇인지 궁금해져서 각각의 내부 구조를 찾아보기로 하였다.
1. String.split()
String클래스의 split메서드의 동작은 다음과 같다.
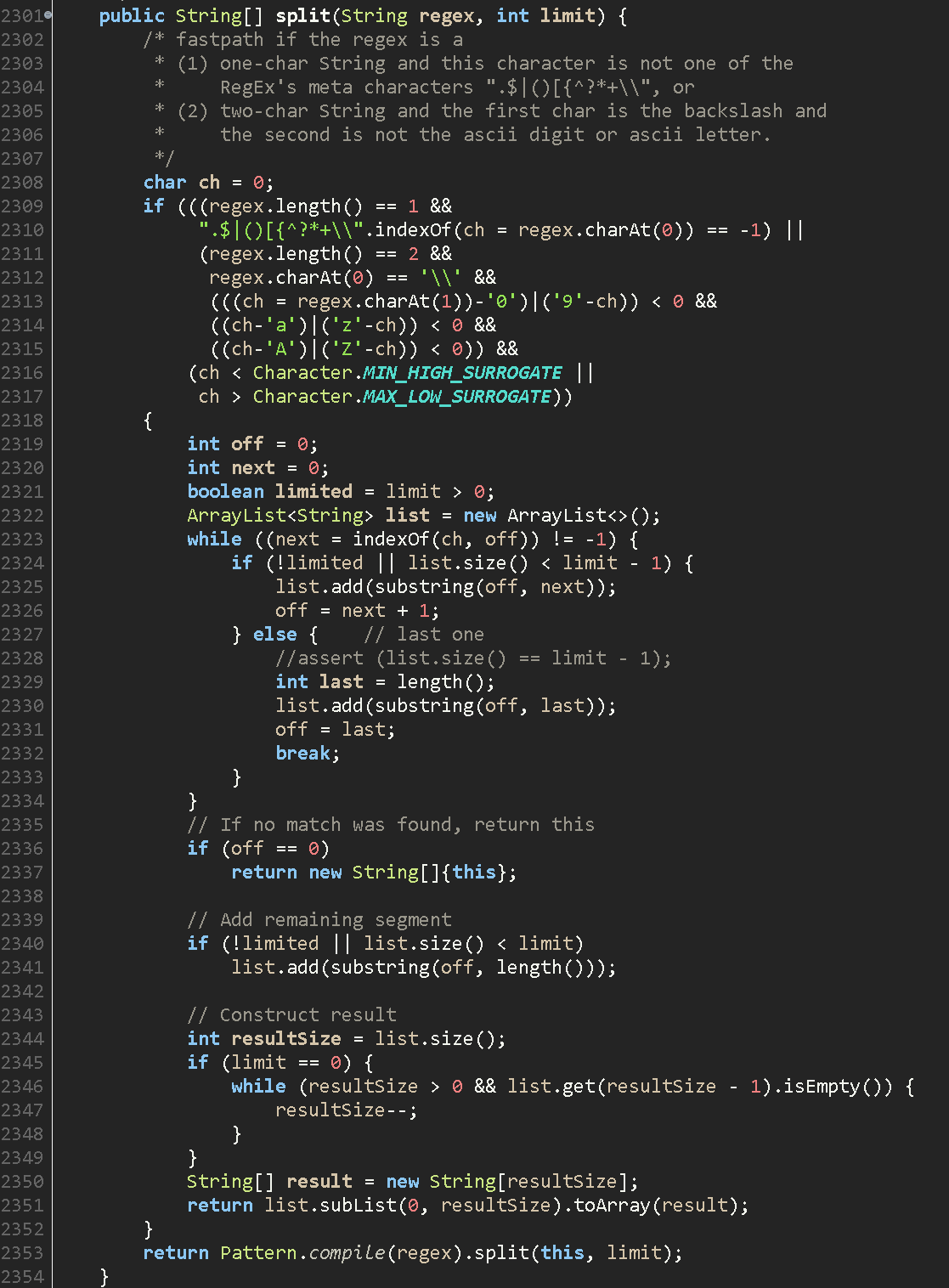
- 구분자가 문자 1개로 정의 될 경우
1-1. ArrayList선언
1-2. indexOf()를 통해 구분자 index 찾기
(indexOf()는 byte배열에 인덱스로 접근하여 찾으면 index 반환.)
1-3. 해당 영역 substring으로 잘라서 list에 넣기.
1-4. 다음 index를 시작점으로 2,3 반복 진행.
1-5. 다음 구분자를 찾지 못하면 마지막 남은 내용을 list에 넣기.
1-5. ArrayList를 array로 반환.
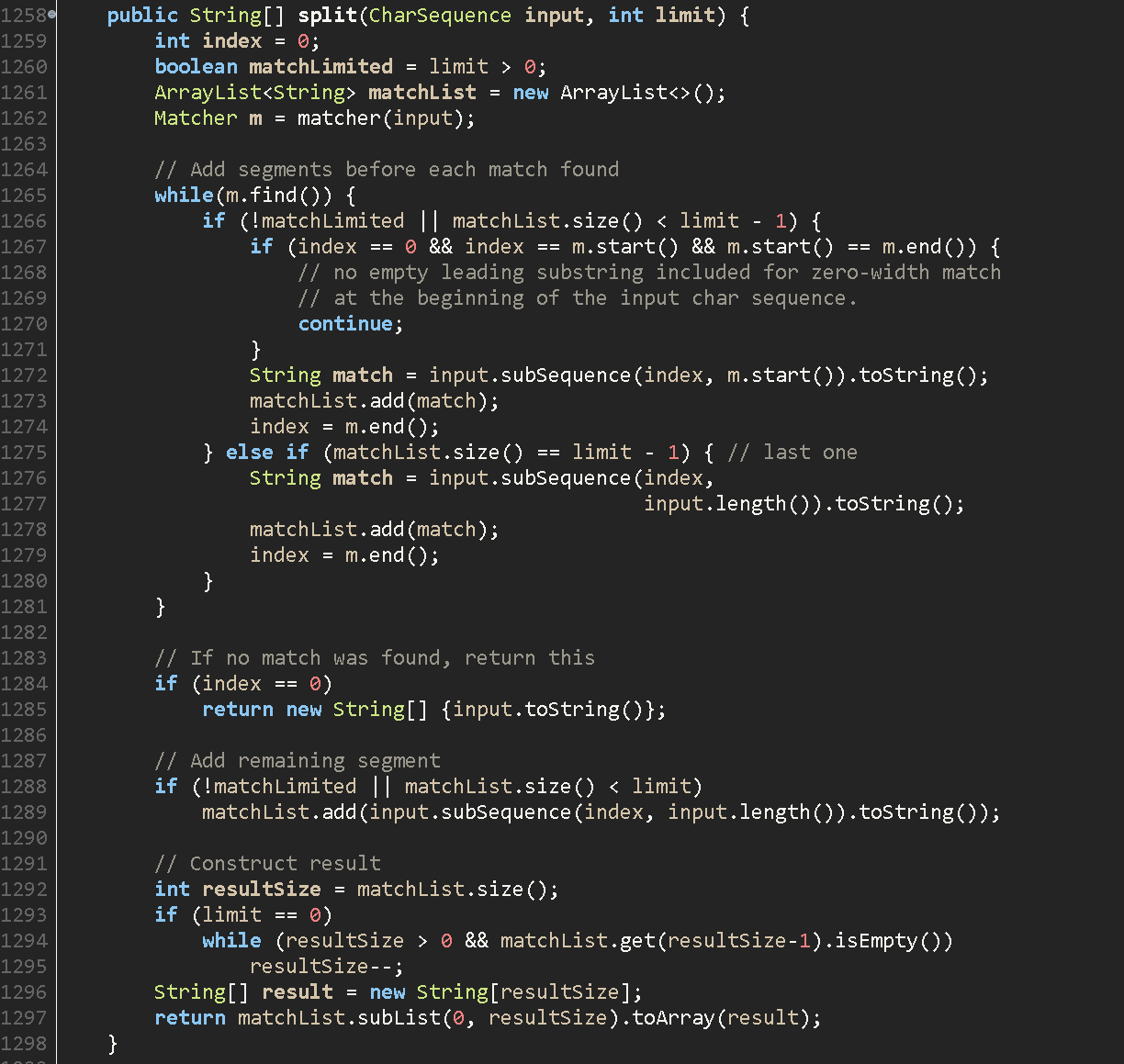
- 구분자가 정규표현식으로 표현된 경우 Pattern클래스의 split() 호출.
2.1 ArrayList 선언
2.2 Matcher클래스에서 find() -> search() -> match()호출됨. (정확히는 모르겠지만 정규표현식이 Node로 관리되고 Node들이 next로 연결되어 있는 형태이다. match()가 Node클래스에 정의된 메소드인데, match되는것이 있으면 그 index를 저장하는 것 같다.)
2.3 찾으면 해당 영역 subSequence로 잘라서 list에 넣기.
2.4 다음 index를 시작점으로 반복. 다음 구분자를 못 찾을 때 까지. 마지막 내용도 list에 넣기.
2.5 ArrayList를 list로 반환.
2. StringTokenizer
StringTokenizer객체 생성 시, 파라미터 string 값을 멤버변수로 가지고, string의 index를 가르킬 포인터, string의 길이 등을 변수로 가진다.
nextToken()
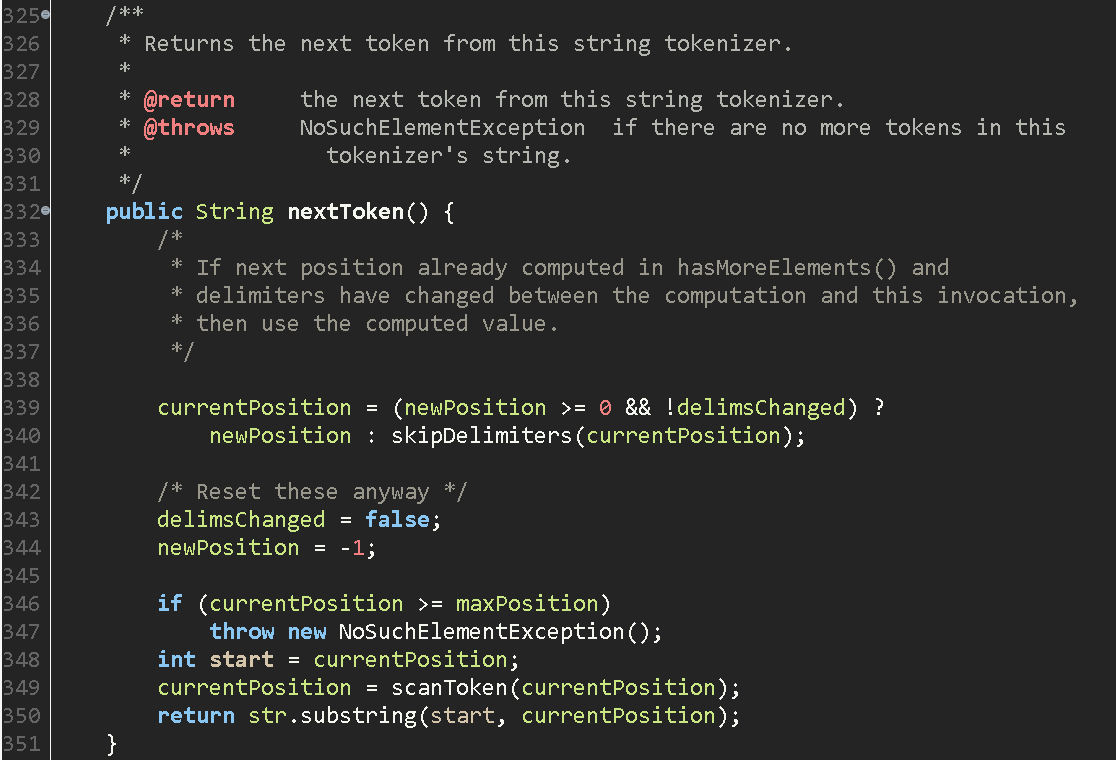
nextToken메서드의 동작은 간단하게 다음과 같다.
1. 현재 포인터가 길이를 넘지 않는지 확인.
2. scanToken을 호출하여 다음 구분자가 있는 index 찾기.
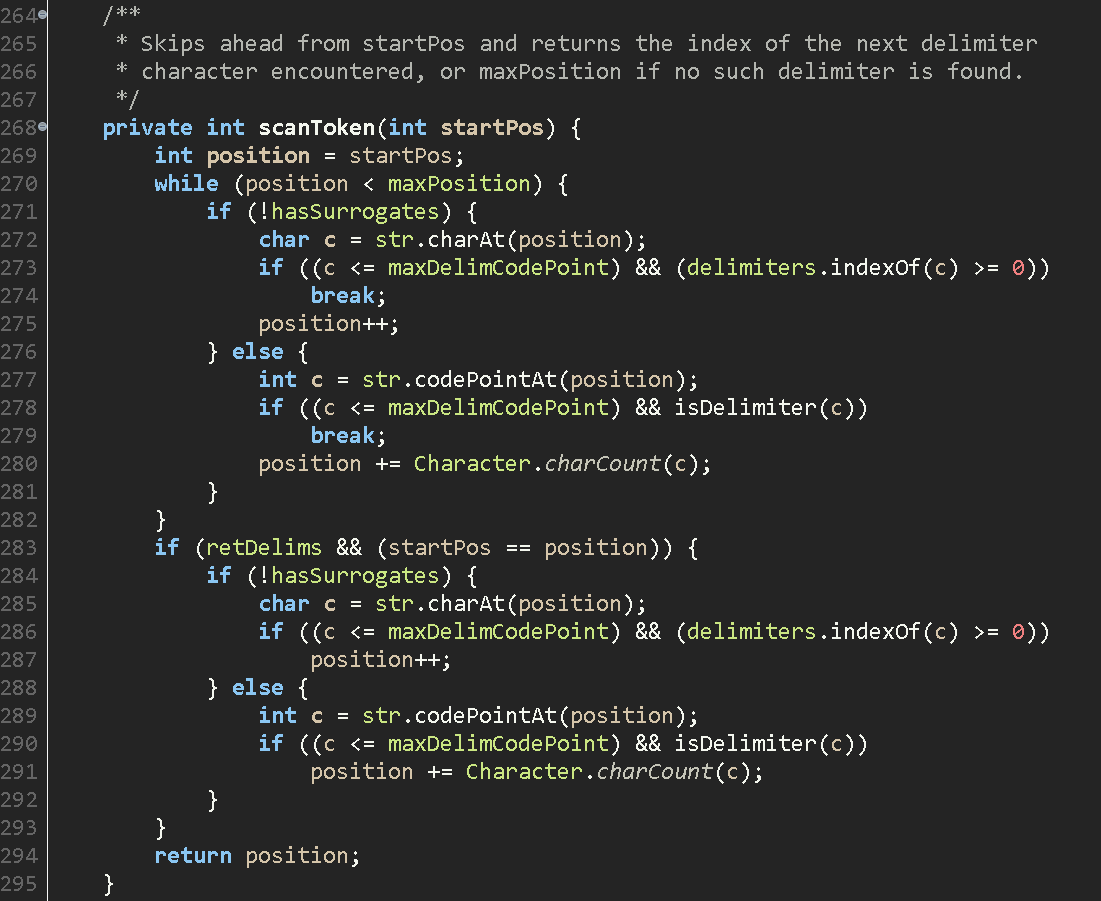
2-1. 포인터로 string을 charAt()해서 char로 들고오기
2-2. 해당char가 구분자에 있는지 indexOf()로 확인.
3. substring으로 해당 영역을 잘라서 반환.
StringTokenizer의 scanToken()은 string index 하나하나마다 구분자 하나하나와 같은것이 있는지 확인하기 때문에 구분자의 길이가 길어지면 시간이 배로 소요된다.
구분자를 지정해주지 않고 기본으로 생성하여도 " \t\n\r\f" 5가지를 구분자로 설정한다.
3. Legacy class
코드를 읽어보며 재미있었던 점은 StringTokenizer 클래스는 레거시 라는 점이다!
* {@code StringTokenizer} is a legacy class that is retained for
* compatibility reasons although its use is discouraged in new code. It is
* recommended that anyone seeking this functionality use the {@code split}
* method of {@code String} or the java.util.regex package instead.해석해보면 StringTokenizer는 하위 호완성을 위해 유지되는 레거시 클래스이니 String의 split을 사용하라고 권장한다.
String, StringTokenizer 두 클래스를 열심히 쳐다보면서 느낀점은
- 첫째로, 학부시절에 교수님께서 어려우니 사용말라던 삼항연산자를 실제로는 굉장히 많이 쓰고있었다..!! 근데 생각보다 어렵지는 않았다.
- 둘째로, 코드 네이밍이 정말 중요하다는걸 다시한번 깨달았다. 변수 이름이 길기는 하지만, 이름을 해석한 뜻과 용도가 같아서 읽기 쉬웠다. 그리고 메소드 위에
@param,@return이런 태그들에 설명이 있어 좋았다. 나도 코드 적으면서 주석을 잘 써야겠다는걸 다시 되새기는 시간이 되었다. - 아직 이해가 안가는 부분도 있지만.. 더 열심히 공부해야겠다..!!
