이 글은 [랭체인으로 LLM 기반의 AI 서비스 개발하기] 도서를 읽고 개인 정리한 글입니다. 모르는 부분을 중심으로 TIL을 작성했습니다.
파인튜닝과 전이학습의 차이
파인튜닝과 전이학습은 모두 기존에 학습된 모델을 활용하여 새로운 작업을 수행하기 위한 방법이지만 접근 방식과 적용 범위에 차이가 있다.
-
전이학습(Transfer Learning) : 사전 학습된 모델의 지식(가중치)을 새로운 과제에 일부 또는 전체 활용하는 것이다. 예를 들어, 이미지넷으로 학습된 모델을 다른 이미지 분류 작업에 활용하는 것이 전이학습의 예시에 해당한다.
-
파인튜닝(Fine-Tuning) : 전이학습의 한 방식으로, 사전 학습된 모델 전체 또는 일부를 새로운 작업에 맞춰 추가 학습시키는 것이다. 전이학습의 하위 개념으로 볼 수 있으며, 전이학습 중에서도 특히 모델 파라미터를 수정하면서 학습하는 것을 말한다.
요약하자면 기존 모델의 지식을 활용하는 것은 전이학습이고, 기존 모델을 추가 학습으로 하여 새로운 작업에 최적화하는 것은 파인튜닝이다.
RAG에 대하여
- RAG(Retrieval-Augmented Generation) : 정보 검색(Retrieval)과 텍스트 생성(Generation)을 결합한 것으로, 단순히 학습된 지식만으로 답을 생성하는 것이 아닌, 외부 지식(문서 등)을 실시간으로 찾아 정확하고 신뢰도 높은 답변을 생성할 수 있다.
RAG는 정보 검색 단계와 텍스트 생성 단계를 포함한 두 단계로 구성되어 있다.
-
정보 검색 단계 : 사용자가 질문을 입력하면, 모델은 사전에 구축된 문서 데이터 베이스에서 질문과 관련된 가장 연관성 높은 문서들을 검색한다.
-
텍스트 생성 단계 : 검색된 문서와 사용자의 질문이 함께 LLM에 전달된다. 모델은 이 문서들을 바탕으로 질문의 의미를 이해하고, 검색한 정보와 모델이 알고 있는 지식을 결합하여 사용자의 질문에 대한 정확하고 구체적인 답변을 제공한다.
제로샷, 원샷, 퓨샷 러닝에 대하여
- 제로샷 러닝(Zero-Shot Learning) : 모델이 아무런 예시도 보지 않고 오직 질문만으로 작업을 수행하는 학습 방식이다. 사전 학습된 지식만을 바탕으로 문제를 해결하는데, 사람이 지시한 문장만으로 모델이 작업 의도를 파악해야 한다.
Q: 다음 문장을 영어로 번역하세요: "나는 학교에 갑니다."
A: # 예시 없이도 번역 결과를 생성할 수 있다.- 원샷 러닝(One-Shot Learning) : 모델이 예시 1개만 보고 새로운 작업을 수행하는 방식이다. 새로운 작업에 대한 구조나 형식을 예시 하나로 학습한다.
Q: 한국어를 영어로 번역하세요.
예시: "나는 집에 간다." → "I go home."
Q: "나는 학교에 갑니다." → # 예시 하나를 참고하여 새로운 문장도 같은 형식으로 번역할 수 있다.- 퓨샷 러닝(Few-Shot Learning) : 보통 2 ~ 10개 정도의 예시를 보고 작업을 수행하는 방식이다. LLM이 작업의 패턴을 예시 몇 개를 통해 이해하는데, 가장 자연스럽고 효과적인 방식 중 하나이다. (ChatGPT도 기본적으로 이 방식을 사용한다.)
Q: 다음 문장을 영어로 번역하세요.
"나는 집에 간다." → "I go home."
"그녀는 밥을 먹는다." → "She eats rice."
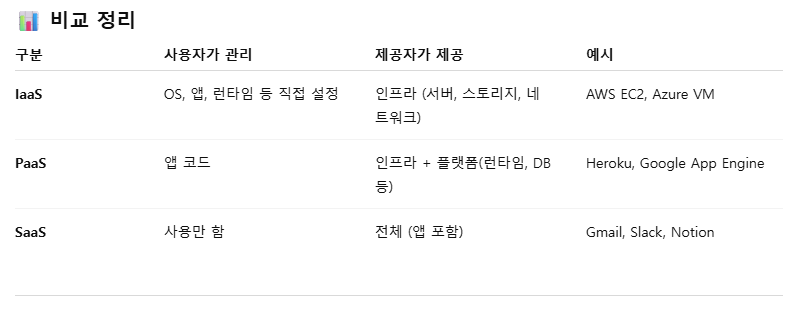
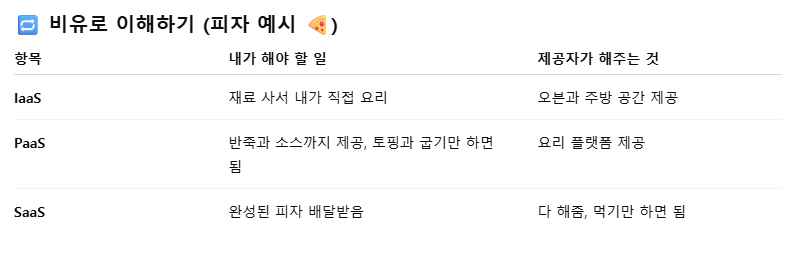
"나는 학교에 갑니다." → # 여러 예시를 보고 패턴을 파악한 뒤 문장을 번역할 수 있다.클라우드 컴퓨팅 서비스 모델 - SaaS, PaaS, IaaS
-
SaaS(Software as a Service) : 소프트웨어를 서비스 형태로 제공하는 것이다. 사용자는 소프트웨어를 설치하거나 관리할 필요 없이 웹을 통해 바로 사용할 수 있다.
-
PaaS(Platform as a Service) : 개발에 필요한 플랫폼을 서비스로 제공하는 것이다. 사용자는 인프라를 신경쓰지 않고 애플리케이션 개발 및 배포에 집중할 수 있다.
-
IaaS(Infrastructure as a Service) : 서버, 스토리지, 네트워크 등의 인프라를 가상화하여 제공하는 것이다. 사용자는 OS부터 애플리케이션까지 모두 직접 구성 가능하다.
RAG 구현 과정
RAG에서 정보 검색 단계의 전체 흐름은 다음과 같다.
1. 사용자 질문 입력
- 사용자가 자연어로 질문을 입력한다. 이 질문은 모델이 문서를 찾고 생성하기 위한 핵심 입력으로 작용한다.
2. 문서 검색 (Embedding + 검색 방식)
- 질문을 벡터로 변환하여 문서와 비교할 수 있게 한다. 질문 문장과 문서들을 임베딩(의미 기반 벡터 공간에 매핑)한다.
3. 유사도 계산 (키워드 또는 시멘틱 기반)
- 키워드 검색(Lexical Search) : 전통적인 방식으로, 검색에서 포함된 단어를 기준으로 문서를 찾는다.
- 시맨틱 검색(Semantic Search) : 문장 간 의미 유사도를 기반으로 유사한 문서를 검색한다. 질문과 문서 벡터 간 코사인 유사도를 계산한다.
4. 관련도 기반 랭킹 처리
- 검색된 문서들 중에서 가장 관련성이 높은 순서대로 정렬한다. 경우에 따라 2단계 방식을 사용하는데, 1차 검색에서는 빠른 검색을 적용하고 2차 정렬에서 의미 기반 정렬을 적용한다.
5. 최종 문서 선택해서 LLM에 전달
- 상위 N개의 문서를 선택하고 선택된 문서들을 질문과 함께 LLM의 입력에 포함한다.
코사인 유사도와 유클리드 거리
- 코사인 유사도 : 두 벡터가 이루는 각도의 코사인 값으로 유사도를 측정한다. 방향이 얼마나 유사한지를 판단한다.

- 유클리드 거리 : 두 벡터 간의 직선 거리를 의미하는데, 위치가 얼마나 떨어져 있는지를 말한다.

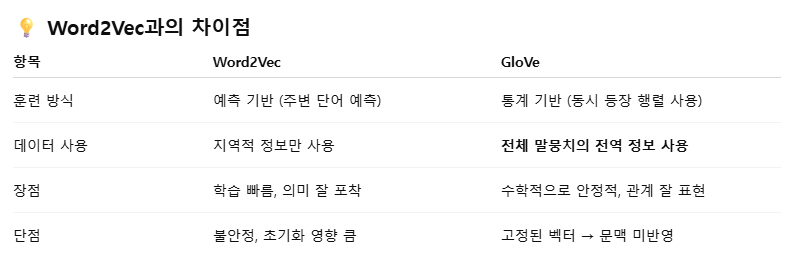
GloVe에 대하여
- GloVe(Global Vectors for Word Representation) : 단어 같의 동시 등장 빈도 정보를 바탕으로 단어를 고차원 벡터로 표현하는 기법이다. 단어는 다른 단어와 함께 등장하는 맥락 속에서 의미가 드러난다는 것을 전제로 한다.
GloVe는 전체 말뭉치에서 단어 i와 단어 j가 몇 번 함께 등장했는지를 기록한 동시 등장 행렬(Co-occurrence Matrix)을 생성한다.
그런 다음, 이 행렬을 바탕으로
두 단어 벡터 간의 차이가 의미적 관계를 반영하도록 학습합니다.