영상의 병렬 처리
이미지 각 구역 별로 코어를 할당해서 병렬 처리 구현
OpenCV에서 지원하는 병렬 프로그래밍 기법
Intel TBB
HPX
OpenMP
APPLE GCD
Windows RT concurrency
Windows concurrency
Pthreads
병렬 처리용 for 루프
range : 병렬 처리를 수행할 범위
body : 함수 객체
ParallelLoopBody 클래스를 상속받은 클래스 또는 C++11 람다 표현식
void parallel_for_(const Range& range,
const ParallelLoopBody& body,
double nstripes = -1.)
void parallel_for_(const Range& range,
std::function<void(const Range&)> functor,
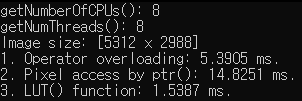
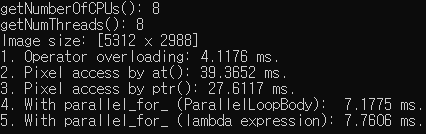
double nstipes = -1.)4와 5는 유사한 성능이지만 5가 간결하므로 추천
룩업 테이블(LUT)
특정 연산에 대해 미리 결과 값을 계산하여 배열 등으로 저장해 놓은 것
픽셀 값을 변경하는 경우 256x1 크기의 unsigned char 행렬에 픽셀 값 변환 수식 결과 값을 미리 저장한 후 실제 모든 픽셀에 대해 실제 연산을 수행하는 대신 행렬(LUT) 값을 참조하여 결과 영상 픽셀 값을 설정
룩업 테이블 연산 함수
ptr() 연산 비교
실수형 27.6117 ms
float alpha = 1.f;
pDst[x] = saturate_cast<uchar>((1 + alpha)*pSrc[x] - 128 * alpha);정수형 14.8251 ms
pDst[i] = saturate_cast<uchar>(2 * pSrc[i] - 128);