
I. INTRODUCTION
머신러닝의 최종적인 목표는 정확한 예측임
그런데 실제 세계에 적용했을 때 더 중요했던 것들은 1. 시스템에서의 안정성, 2. 데이터 분포 추적에 대한 회복력, 3. 예측에 대한 정확한 평가, 4. 안전성(보안), 5. 법을 위반하지 않는것, 6. 전문가들에게 도움이 되는지, 7. 데이터 사이의 연관성 추정이였다.
그래서 XAI가 개발되었고 이 XAI는 과학자들에게 영감을 주기도 함
이 리뷰 페이퍼에서는 최근의 놀라운 개발들을 요약하고, 이론적 지식, 관점을 제공하며 현재의 가장 좋은 응용에 대해 강조한다. 이 페이퍼는 모든 페이퍼를 다루진 않지만 사후검증 방법들에 집중한다.
II. TOWARD EXPLAINING DEEP NEURAL NEETWORKS
머신러닝은 의 문제를 푸는 형태로, Input feature x가 있을 때 그에 해당하는 Classification 같은 문제를 품. 그런데 medical scenario에서 예를 들면 좋은 건강관리 능력이 있다면 바로 적용단계를 생각하겠지만 적용을 위해 이 예측에 대해서 설명할 때 문제가 생김**
A. How to Explain: Global Versus local
몇몇은 전체 해석에 집중함(activation-maximization) 그리고 Valid case에만 집중을 하기도 함. 몇몇 prototype들은 이런 해석에 대해서 어떤 Feature가 모델 출력에 영향을 미쳤는지 궁금해했음.
여기에 가장 적합한 예시는 비선형 결정 함수를 선형 함수로 추측하는 것임. 아래 식에서 가 예측에 영향을 주는 정도임
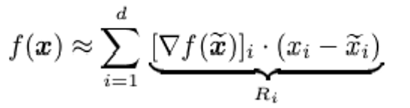
이런 함수 f(x)에서 어떤 feature 가 큰 영향을 미치는 조건은 두 가지임. 1. 데이터로 표현되고 2. 현재 의 값에 따라 출력 값이 민감하게 변해야 함.
예를 들어 “Concrete compressive Strength data set”을 사용하여 설명했을 때, Blast Furnace Slag가 가장 큰 영향을 주었고 다른 것들은 미미한 영향을 주었음. 그런데 여기서 저자는 XAI를 적용할 때는 특정 도메인의 전문용어보단 쉬운 단어로 설명해야 한다고 했음
B. Deep Networks and the Difficulty of Explaining them
세 가지 어려움이 있음
- DNN은 선형 모델이나 얕은 신경망보다 깊기 때문에 신경망의 weight를 계산하기 힘듬
- DNN은 갈수록 gradient가 부서지는 “shattered gradient” 문제가 있음
- 데이터와 적대 데이터의 중간뿌리인 를 찾기 어려움
III. PRACTICAL METHODS FOR EXPLAINING DNNs
다양한 DNN XAI 모델이 개발되었고 아래 네 가지에 집중하여 설명할 것임
A. Interpretable Local Surrogates
이 방법은 decision function을 local surrogate model로 대체하는 것임
이렇게 하면 original DNN 모델의 gradient에 의존하지 않기 때문에 Shattered gradient 문제를 회피할 수 있음
예시에는 LIME과 LORE, Anchors가 있음
B. Occlusion analysis
이 방법은 occluding path나 feature에 얼마나 영향을 미치는지 꾸준히 테스트하는 것임
강하게 연관성이 감소하는 곳을 하이라이트 하여 히트맵을 생성할 수 있음
Shapley values도 occlusion analysis라고 볼 수 있음
occlusion analysis의 확장은 함수 값 의 감소가 나타나는 occlusion pattern을 찾는 의미있는 섭동(어떤 물체가 움직이는 형상)이다.
C. Integrated Gradients (IG) /SmoothGrad
Integrated Gradients는 엣지의 기울기(Gradient)를 적분하여 설명함
구현을 위해서는 Gradient 들이 이산화 되어야 함
이산화 단계가 많을수록 계산 비용이 더 많이 듬
SmooteGrad는 원본 데이터의 주변 여러 perturbation에 의해 gradient가 평균화됨
shattered gradient(gradient가 부서지는) 문제도 해결함
D. Layerwise Relevance Propagation (LRP)
LRP는 신경망의 계층 구조를 명시적으로 사용하고 반복적으로 동작하여 설명함
출력에서 activation function 순으로 인풋 피쳐까지 역추적함
여러가지 룰에 따라 진행되는데, min/max pooling, activation,
LRP는 SmoothGrad의 역할도 하지만 단일 백워드 패스만 필요하다. (SmoothGrad는 주변 여러개)
또한 편향된 Gradient로 해석될 수도 있음
E. Other Methods
위 네 가지 Post-hoc에 해당하지 않고 특별한 신경망 구조를 가지는 것들을 모아둔 파트
self-explainable 모델은 모델들의 생각을 설명하도록 설계함. 예를 들면 선형 모델에서 블랙박스를 추론하거나, 내부 표현을 한다거나 등
다른 방법은 일반적인 설명 방법이 직접적인 해결책을 제공하지 않는 특정 심층 신경망 모델에 특화됨. GNNexplainer, GNNLRP 등
추가적인 방법은 input feature 가 아닌 latent space code의 관점에서 설명을 추구함. 예를 들어 TCAV는 개별 예측에 대한 잠재 공간을 설명한다.
IV. COMPARING EXPLANATION METHODS
Section 3에서는 다양한 방법들을 기술하였는데, 이는 같은 ground-truth에 대해 다른 설명을 생성함
IG vs LRP 의 경우 IG는 픽셀단위로 설명하는 반면 LRP는 전체적인 특징을 설명하는 경향임 (Fig 5)
실무에서, 설명에 대한 정답(ground-truth)를 정하기 어렵기 때문에 좋은 설명인지 판단하기 어려움
이를 일반화 하기 위해서는 1. 목표 Task가 무엇인지 2.설명을 사람에게 사용했을 때 성능이 오르는지
그런데 저런 end-to-end 방식은 실제로 사용하기 어렵기 때문에 아래와 같은 설명들이 제안됨
A. Faithfulness/Sufficiency
첫 번째 방법은 ML의 decision structure를 신뢰성 있게, 이해하기 쉽게 설명했는지 분석하는 것임
실용적인 방법에는 “pixel-flipping”이 있음.
이 방법은 반복적으로 가장 관련성 높은 특징을 지운 후 신경망 출력의 변화를 모니터링하는 것
(Fig.6의 가로축이 occlusion 한 비율)
이때 붕괴 예측 점수가 나오는데, 이것이 가파르게 떨어지면 설명 방법은 더욱 신뢰도 높아짐
- Fig 6에서 알 수 있는 점 1. 모든 설명에서 특정 feature의 occlusion은 빠르게 클래스 증거를 파괴함, 2. IG가 초반에 높은 감쇠율을 보이지만 후반에는 비슷해진다

이 방법은 설명 방법들이 얼마나 클래스 결정에 영향을 주는지 보지만, 이것이 사람이 그 설명에 대해 쉽게 이해하고 있는지를 설명하지는 않는다
B. Human Interpretability
두 번째 방법은 사람이 분류기의 결정 전략을 잘 이해할 수 있는지를 본 것임.
근데 각 사람마다 읽는 능력이 다르기 때문에 일반적으로 그 기준을 정하기 어려움
이미지 분류에서는 관련된 정보를 담은 작은 픽셀을 사용한 히트맵을 예시로 들 수 있음
실전에서 신경망은 인풋 특징들을 설명할 필요는 없음. occlusion이나 LRP 방법은 특정 계층에서 개념을 표현하려고 함.
C. Applicability and Runtime
Faithfulness와 interpretability는 설명 방법의 총 유용성을 나타내지는 않음.
Occlusion-based 설명은 구현하기 가장 쉽고 어떤 신경망에서든 할 수 있음. 그래서 예측의 설명에 서드파티 모델로 사용할 수 있음.
IG는 각 신경망의 gradient로의 접근 권한이 필요함. 이 방법또한 복잡한 신경망에 쉽게 구현될 수 있음.
LRP는 여러 레이어, activation layer, poolying layer들로 구현되어 있을 때 각 레이어를 명확하게 설명하기 위해서는 많은 overhead가 생김
Occlusion은 pixel을 파괴하고 재평가하는 과정을 반복해야 하기 땜에 가장 느리다.
IG는 여러 반복이 필요하기 때문에 런타임이 좀 길어진다.
LRP는 가장 빠른 방법이다. 그래서 large-scale analysis에 중요하다.
IV. THEORETICAL FOUNDATIONS OF EXPLANATION METHODS
위 파트에서 설명한 Faithfulnesss, usability, runtime 보다 이론적인 기초에 집중한 연구들도 있다
A. Sharpley Values
이 방법은 협동 게임에서 원래 개인의 공헌도를 계산하기 위해 제안되었음
협동에 참여한 개인 부분집합을 삭제하여 최종 보상에 어떤 변화가 있는지 확인하는 방법임
이 방법을 ML 모델에 적용할 때 개인은 input feature가 되고 보상은 output으로 생각함
Sharpley value는 보상을 측정하는 함수에 영향을 주진 않고 이 매커니즘이 설명 방법의 기초가 됨
B. Taylor Decomposition
테일러 함수는 함수를 인풋과 degrees 의 조합으로 decompose하는 수학적 프레임워크임
Sharpley value는 여러 번 평가하지만 이 방법은 한번에 진행함.
고차원 함수일수록 여러 gradient를 가지지만 선형으로 진행된다면 2차 이상은 무시가능
그래서 root point와 가까운 첫 gradient만 생각하면 1차항만 신경쓰면 됨
일반적으로 root point를 찾는 방법은 없고, 최적화 방법이 적용

C. Deep Taylor Decomposition (DTD)
input feature의 할당 문제를 공식화하는 방법의 대안으로 Deep Taylor Decomposition이 있음
DTD는 DNN 같은 신경망에서 모든 뉴런에 Taylor decomposition을 적용하여 input feature의 예측 결과에 대한 attribute를 찾는 과정임
Message 라고 하는 를 정의하여 특정 계층에 뉴런이 수신한 관련성 점수를 산출함
이를 최상위 계층에서 하위 계층까지 진행함
D. Connections Between Explanation Methods
- Table 1

IV. EXTENDING EXPLANATIONS
이전 섹션까지는 DNN에 적용되어 특정 유형의 설명을 하는 방법들을 설명한 것임
이 파트에서는 특징의 조합을 포함하는 더 풍부한 설명을 생성하기 위한 방법
설명이 필요한 비지도 학습과 같은 비신경망 모델로 설명을 확장하는 체계적인 방법
DNN 분류기에 대한 설명이 분류 차별적인지 확인하는 원칙적인 방법
개별 설명을 넘어 ML 모델에 대한 일반적인 이해에 도달하는 전략에 대한 내용이 이어졌습니다.
