
1. Introduciton
Perceptual brain decoding(PBD)는 f-MRI와 ECoG같은 다양한 modality들로 탐구되어 왔지만 우리는 높은 시간적 해상도와 비용 효율성 및 비침습성 를 위해 ****EEG를 활용한 PBD task를 선택했다.
EEG-based brain decoding은 매우 저명하며 다양한 medical, cognitive 응용이 가능하다. 예를 들면, 움직임이나 목소리에 문제가 있는 혼수상태나 마비 환자들과 소통할 수 있고, 인지 자극을 주어 어떤 대답/상상을 하고 있는지 알 수 있고, 기억 회복, 생각의 시각화를 통해 인지 연구와 재활이 가능하고, 건강 관리에도 응용할 수 있다. 더 나아가, 보안이나 법정에서 개인 정보를 강제로 얻을 수도 있다.
몇몇 연구들은 EEG 신호를 디코딩하여 잠재 벡터를 뽑아내어 visaul stimulus 와 같은 클래스의 이미지를 생성하였다.
VAE나 GAN을 SOTA로 생각하고 사용하여 잠재 특징 공간을 통해 이미지 생성을 하는 것은 딥러닝에서 활발한 연구 분야이다. 하지만 EEG-facilitationg PBD를 통해 생성되는 잠재표현을 사용하는 연구가 몇몇 있었는데, 우리는 이 작업들이 개선의 여지가 많은 작업이라고 생각한다. 예를 들면, 이미지의 분포를 파악하여 생성하는 Task를 사전학습된 classification network에서 얻은 latent embedding을 통해 수행하는 것으로 대체하는 것은 아직은 초기 노력에 불과하기 때문이다.
이 작업에서 우리는 informative cue를 학습하고 이미지를 생성하는 NeuroGAN을 제안한다. 우리는 이 작업이 class-specific image를 생성하는데 novel한 방법이라고 생각한다. 게다가, 우리는 성능을 향상시키기 위해 perceptual loss와 관계된 특징들을 극대화하는 attention module을 추가하였다. 우리는 이미지 퀄리티 평가만으로는 충분하지 않기 때문에 class-specificity는 class-diversity score로 계산한다.
우리의 Contribution은 아래와 같다.
- An encoder–decoder-based image generation from EEG signals. We demonstrate that this encoder–decoderbased paradigm yields reasonably good results on simplistic images while failing on complex natural object images.
- A novel architecture, NeuroGAN, is proposed that is trained in an end-to-end fashion both for learning the latent EEG representations and image generation.
- We also propose to make use of perceptual loss function along with the traditional GAN loss to generate good-quality realistic complex natural images.
- An attention module for the generator of the network is also introduced to help in learning the compact representation by giving more weightage to the relevant features.
- The performance of NeuroGAN is shown to surpass all the available SOTA in terms of inception and diversity score.
NeuroGAN을 학습할 때 EEG-이미지가 완전히 대응되는 셋이 아닌 EEG와 클래스 레이블별 pair를 사용하였다. 사람이 생각하는 class의 이미지를 생성하는 것에 초점을 두었다.
구성은 아래와 같다. 2. 관련 연구 …
2. Related Works
Machine learning for EEG classification은 발작 감지, 이벤트 관련 potential 감지, 정신과 관련된 , 감정 인식, 동작 상상 등에 초점을 가진다. 여기서는 perceptual brain decoding 에 가장 가까운 것에 대해 말할 것이다.
첫번째 방법은 EEG data를 수집하면서 목표 이미지를 시각화 하였다. 저자들은 LSTM 기반 패러다임으로 feature를 판별하고 생성 방법으로 시각적 자극을 재구성(reconstruct)하였다. 다른 작업에서는 저자들이 semi-supervised 기반 cross modal image 합성 방법을 제시하였다. 저자들은 EEG와 GT 이미지를 학습에 같이 넣어 학습하는 multi-modal framework를 사용했다. 다른 연구는 GAN 기반으로 이미지를 생성하였다. 위에 언급된 모든 작업은 뇌파-이미지 쌍 간의 대응 관계에서만 실행이 가능하다.
반면에 우리랑 비슷하게 EEG 와 corresponding image와 1대1 mapping이 되지 않고 EEG를 사용하여 이미지를 합성하는 작업이 있었다. 이 저자들은 사전 학습된 EEG classifier embeddings을 조건 벡터로 사하였는데 이는 generative 에서는 좋은 선택이 아닐 수 있다는 단점이 있다.
이 작업에서 우리는 이미지 합성에 prominent한 GAN을 사용할 것이다. GAN은 명백한 데이터 분포가 필요 없다는 장점이 있다. 하지만 기본적인 GAN은 noise 외에 다른 조건은 조절하지 않습니다. 이를 극복하기 위해 noise와 생성기에 조건을 입력하여 모드별 조건부 입력을 넣습니다. 우리는 EEG 신호를 조건부 입력으로 시각적 자극을 생성하는 것에 초점을 둔다.
3. Dataset Details
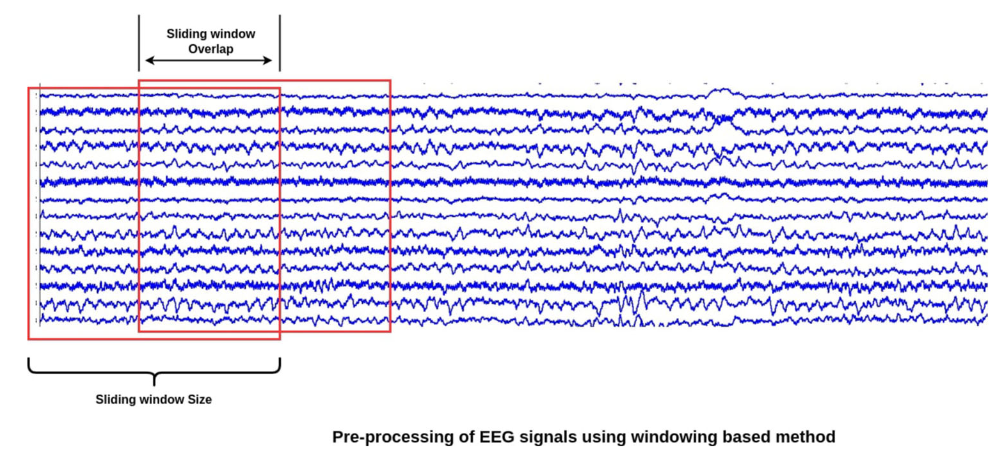
데이터셋의 세부 사항은 ThoughtViz [9] 에 있습니다. 이는 23명의 자원자에게 characters, digits(0-9), objects (10 class from ImageNet)을 보여주고 얻은 데이터셋입니다. 각 카테고리에서 10개의 Example이 선정되었습니다. 각 Example들은 23 자원봉사자의 10개의 클래스 이미지에 대한 데이터를 가지고 있고 각 녹음은 10초입니다. 이 데이터의 전처리는 8개의 샘플이 중첩된 32개 샘플의 슬라이딩 윈도우를 사용하여 수행되었습니다.
3.1 Pre-processing using a sliding window
수집한 EEG 신호는 One-trial에 10초입니다. 14Channel이고 Sampling frequency는 128hz 이다. 그래서 One-trial당 샘플의 숫자는 14X1280 이다. 이제, 작은 smaller temporal section을 슬라이딩 윈도우 방법을 통해 생성할 수 있다. 슬라이딩 윈도우는 14X32의 크기를 가지고 다음 포인트에서는 지난 슬라이드와 8 time poinst의 중복되는 부분을 가진다. 뇌파 신호를 더 작은 조각으로 변환하면 학습 데이터가 증가하고 분류를 위한 localized 표현이 가능하다.
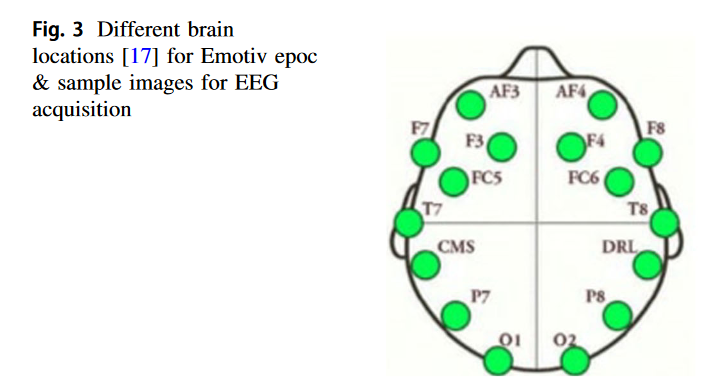
EEG 데이터는14 채널을 가진 Emotiv epoc headset을 통해 수집되었다. 이 기계의 sampling frequency는 128Hz이며 아래 그림과 같이 전극의 위치가 되어있다.
4. Image synthesis using a cross-modality-based encoder-decoder network
encoder-decoder network 기반 이미지 변형은 딥러닝에서 주로 사용된다. 우리는 여기에 동기를 얻어 EEG 신호를 인풋으로 한 cross-domain 이미지 합성을 사용한다. EEG 신호는 채널과 time stamp의 행렬 형태로 들어간다. 인코더는 시간 축을 위한 1D CNN 레이어, 채널 축에 걸친 1D CNN 레이어로 되어있다.
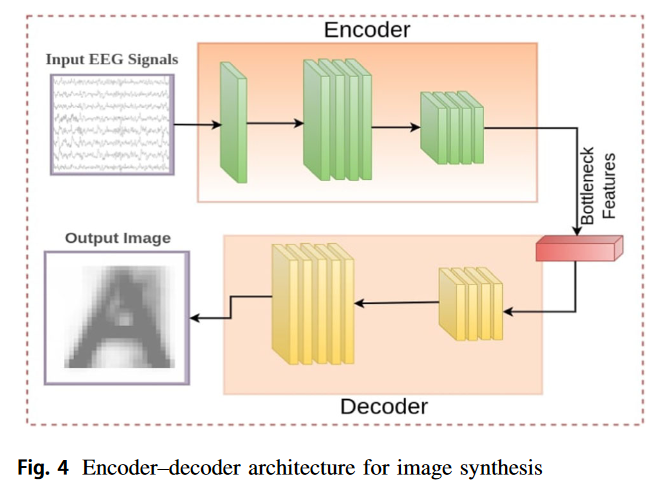
Bottleneck layer의 사이즈는 100이고 Decoder는 encoder와 동일하지 않다. Decoder는 2-D CNN 레이어들로 업샘플링의 역할을 한다. 네트워크는 MSE loss를 사용하여 훈련되고 EEG와 visual stimuli의 pair가 없기 때문에 EEG와 class label을 가지고 mapping을 진행한다. 마지막층은 64x64x3의 ImageNet, char74K 을 생성하고 64x64x1 MNIST dataset을 생성한다. EEG signal w.r.t를 넣어 생성시킨 결과는 Fig.5 에 있다.

생성 결과 (Fig.5) char74K와 MNIST는 선명하지만 object는 퀄리티가 좋지 않았다. 이는 복잡한 이미지보다 간단한 이미지에서 더 성능이 좋다는 것을 볼 수 있었다. 우리가 추측할 때 이는 이미지와 EEG 신호 간의 1대1 corresponding이 없기 때문이라 추측할 수 있습니다. 잘 생성된 문자와 숫자는 비슷한 형태를 가지고 있습니다. 이러한 encoder-decoder의 무능력때문에 새로운 구조를 찾아야 합니다.
하지만, 인코더 디코더 모델은 간단하면서 충분히 효율적인 모델로 간주될 수 있으며 digit과 character 이미지를 생성하기에는 충분히 좋다.
아래는 분석을 위해 원본과 생성 이미지에 대해 t-SNE로 bottleneck layer의 분포를 시각화 결과이다.
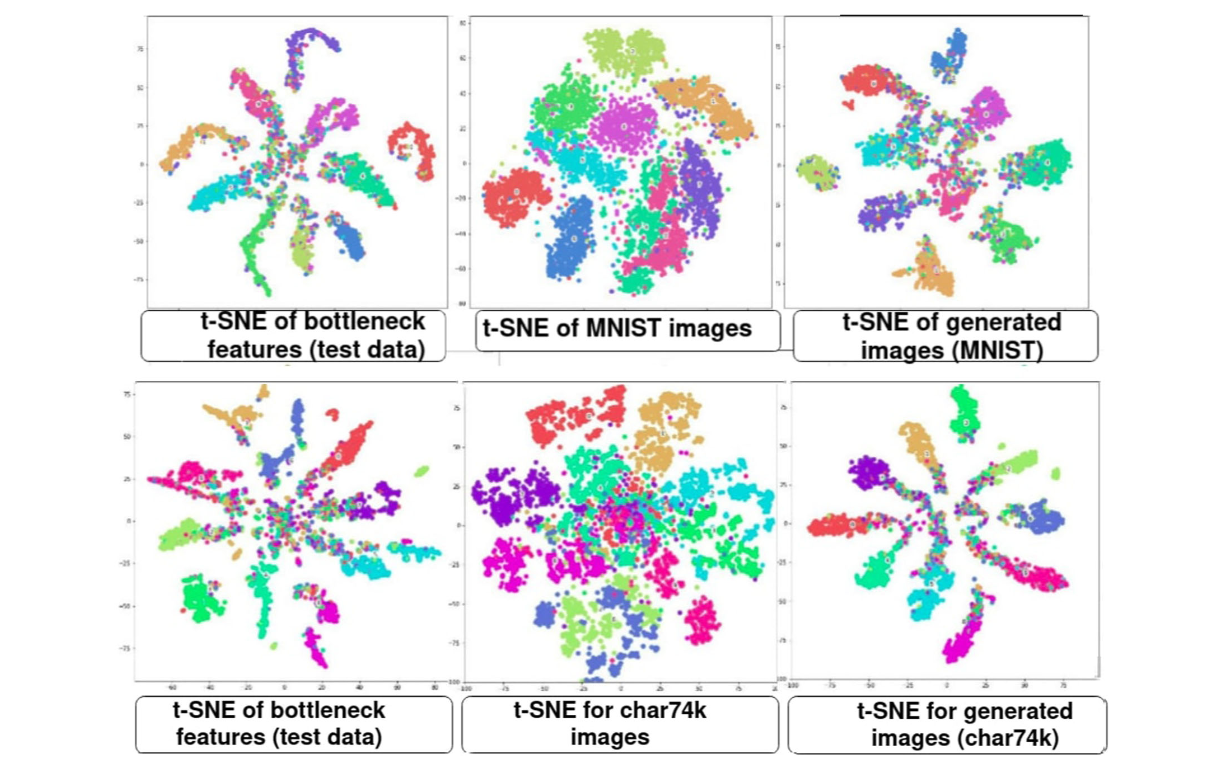
그림을 보면 각 Feature은 충분히 compact한 cluster를 이루는 것을 볼 수 있다. MNIST digis와 char74K 데이터의 흔한 특징은 shape이고, 네트워크는 이 shape들을 잘 학습한다. ImageNet 데이터의 경우에는 variation이 높으며 좋은 퀄리티의 이미지를 생성하기 좋지 않기 때문에 인코더-디코더 네트워크가 뇌파 신호로부터 자연스러운 객체 이미지를 생성할 수 없다.
5. The proposed approach: NeuroGAN
EEG 신호는 네트워크가 학습하기 힘들게 noisy하고 고차원으로 퍼져있다. EEG 신호로 class-specific image를 생성하려면 효과적인 corresponding embeddings가 필요함. 사전학습 EEg classifier를 embedding으로 생성하는 기존 연구와는 달리 우리는 AC-GAN 구조를 제안한다.
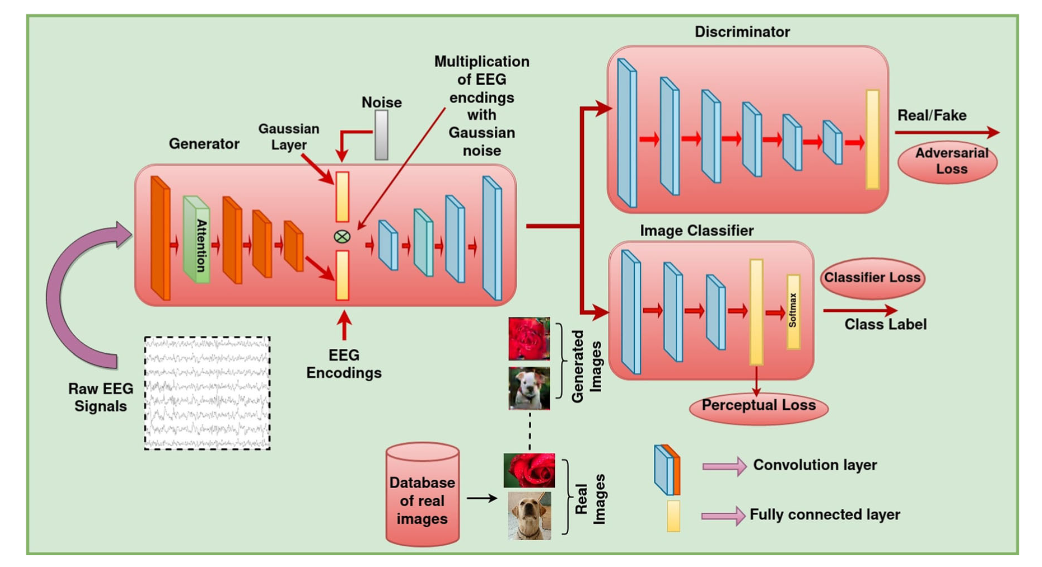
5.1 The proposed network
이 네트워크는 생성기, 판별기, 사전학습 이미지 분류기로 구성되어 있다. 전통적으로, 생성기는 랜덤 noise를 통해 이미지를 합성하고 판별기로 진짜인지 가짜인지 분류한다. 이 조합은 적대적 fashion이고, 실제 이미지에 가깝게 하는 것을 목표로 한다. 구성요소의 세부사항은 아래와 같다.
5.1.1 Generator
이 아키텍처의 생성기는 두 가지 과업을 진행한다.
a) class-specific 임베딩 학습, b) 임베딩을 통해 class-specific 이미지 생성
생성기는 encoder-decoder 네트워크로, encoder은 32,25,50 convolution filter를 포함한다 (필터사이즈 (1,4) (14,1) (1,4) ). 첫번째 convolution 레이어에 attention module을 적용한다. Dense layer는 199개의 뉴런을 가지고 있다. 모든 레이어에 ReLU activation function이 있다. 생성기의 네트워크의 마지막 임베딩은 100의 차원을 가지고 있다. 이렇게 인코딩된 EEG 임베딩은 가우시안 레이어에서 발생하는 노이즈를 측정(weigh)하는데 사용된다. 가우시안 레이어는 잠재벡터를 reparameterization하여 Mixture-ofGaussian model로 reparameterization한다. 이 작업에서, 학습가능한 매개변수 를 가진 gaussian layer를 사용합니다. 이를 통해 sample point 을 가지고 를 생성한다.

이 reparameterizng technique은 적은 데이터로 GAN을 학습하는데 효과적이다. 디코더는 4개의 convolution layer로 이루어져 있다 (256, 128, 64, 3 filter). 디코더에서는 첫 세 레이어만 ReLU를 사용한다. output으로 0~1의 범위를 출력하기 위해 Sigmoid를 사용하였다. EEG 신호는 신호와 noise의 조합으로 볼 수 있다. 따라서 사전 학습된 분류기의 인코딩을 사용하여 생성기 네트워크에 입력으로 사용할 수 있다. 하지만, 사전 학습 EEG 분류기를 통해 생성된 임베딩은 이미지 합성에는 적합하지 않고 이미지를 판별하는데 더욱 적합하다. 이 문제를 해결하기 위해서 우리는 네트워크가 더 적합한 임베딩을 결정하도록 한다. 그러므로, 우리는 EEG classifier의 임베딩을 사용하지 않고 raw EEG를 인풋으로 사용한다.
5.1.2 Image classifier
우리는 또한 생성 이미지에 대해 classification loss를 얻기위해 pre-trained CNN 기반 이미지 분류기를 사용한다. 이 분류 loss는 생성기가 클래스별 이미지를 생성할 수 있는 클래스별 잠재 표현을 학습하게 한다. 분류기는 class label이 있는 ImageNet과 함께 학습된다. 이 분류기는 EEG 데이터가 나타내는 10 Class 만 학습한다.
5.1.3 Attention module (AM)
또한 Generator에 Attention module을 사용한다. AM의 주 목적은 더 중요한 특징을 더 집중하기 위해서다. 또한 이 모듈은 더 빠른 수렴을 보여준다. AM에서는 CNN과 fully connected layer의 조합이 attention vector에 도움을 준다. 게다가, Sigmoid layer가 각 채널의 attention value를 얻은 다음 해당 입력 특징맵의 채널에 곱한다. 마지막으로 얻은 출력은 residual learning을 위해 input과 합쳐진다.
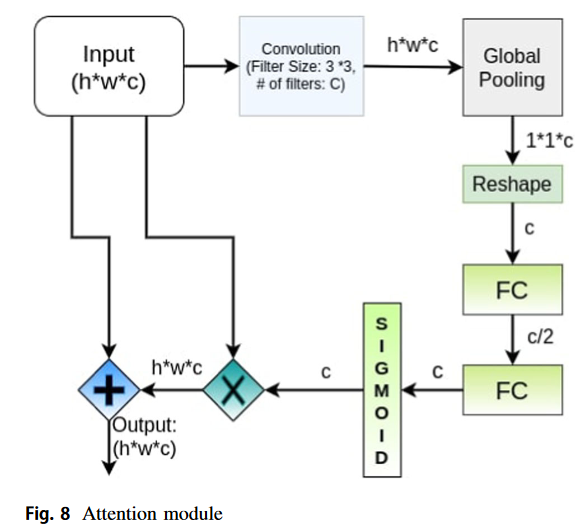
d인풋 사이즈가 이고 이게 AM으로 들어갈 때 먼저 3x3 필터를 가진 convolutional layer가 적용된다. 개의 filter가 이 convolution layer에 쓰이고 output은 의 shape을 가진다. 이후, global pooling layer가 각 채널의 를 얻기 위해 에 적용된다. 에 적용되어 채널은 c이다. 이렇게 얻은 descriptor를 두 개의 fully connected layer에 적용하고 c dimensional vector 을 얻는다. 마지막으로 sigmoid layer에 통과시켜 0~1의 값을 가지게 한다. 이는 Attention value를 얻는 과정이다. 이후 입력 특징맵의 corresponding 채널과 곱해지고 이 결과를 residual learning과 합치기 위해 입력 에 더해집니다.
5.1.4 Discriminator
판별기는 real or fake 의 분류를 시행하는 여러 겹의 CNN 레이어의 조합이다. 생성기가 실제 데이터에 가깝게 생성하도록 정확하게 분류하려 노력한다.
5.1.5 Loss function
GAN 신경망을 학습하기 위한 로스 펑션 중 기본(standard)는 adversarial loss function이다.
랜덤 노이즈 인풋: , 실제 이미지: , 실제 이미지 분포:
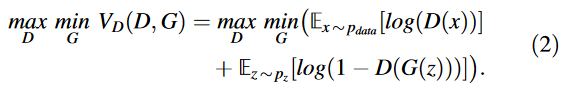
class-specific image를 생성하기 위해 분류기의 분류 loss인 cross-entropy loss를 사용함.
EEG sample의 라벨: , 이미지 분류기의 예측 이미지 라벨:

또한 결과의 시각적 질을 높이기 위한 Perceptual loss도 채용한다. Perceptual loss 는 이미지 분류기의 마지막에서 두번째 레이어의 특징들을 사용한다.
l 번째 이미지 분류기 레이어의 실제 이미지 임베딩: , 생성 이미지 임베딩:
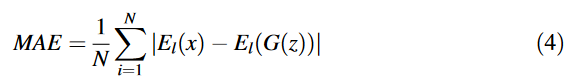
깊은 층이 high-level 특징을 학습하고, 더욱 실제 의미를 담은 content를 생성하는데 도움이된다. total loss는 위 세 loss의 조합이라 생각하면 된다.
5.2 Training
우리는 NeuroGAN을 10개의 object 클래스와 대응되는 EEG sample로 학습한다. 생성기는 raw EEG signal을 인풋으로 가진다. 각 EEG sample은 14X32의 크기를 가지며 총 45390개의 샘플이 학습에 사용되었다. EEG 데이터와 대응되는 이미지들은 판별기를 학습과 MAE(perceptual loss) 를 계산하는데 사용되었다.
생성기는 class-specific EEG 임베딩을 생성하도록 훈련되었고 bottleneck layer가 출력층이다. 이 생성 이미지와 EEG 데이터와 대응되는 실제 이미지들은 판별기를 학습하는데 사용된다.
더 자세하게 말하면, 실제 이미지와 생성된 이미지 셋이 real인지 fake인지 분류하도록 판별기를 학습한다.
생성 이미지와 실제 이미지는 사전학습 이미지 분류기에 분류, 인지 loss를 계산하는데에도 사용된다. 인지 loss는 이미지 분류기의 2번째~마지막 레이어의 임베딩으로부터 학습된다. 신경망은 100개의 배치사이즈로 학습되고 학습률은 의 Adam optimizer를 채용한다.
6. Results
우리는 Ablation study와 비교로 Qualitative, Quantitative 결과를 제공한다.
6.1 Evaluation measure
평가지표는 두 개를 사용한다.
- Inception score: 생성 이미지의 Quality를 비교하는 지표이다. IS가 높을수록 퀄리티가 좋다.
생성된 샘플: , p와 q 사이의 KL-Divergence: ,
조건부 class 분포: ,
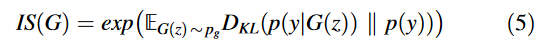
- Class Diversity Score: 생성 이미지의 class-diversity score를 계산하기 위해 사전학습 이미지 분류기를 사용한다. 생성된 이미지를 분류기에 통과시키면 one-hot 인코딩벡터 가 나온다. 각 클래스의 class diversity는 one-hot 예측 벡터의 entropy 평균으로 계산된다.
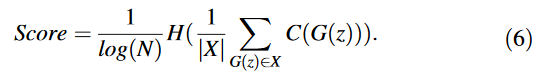
전체 클래스의 개수: N, 전체 생성 샘플의 개수: |X|, 분류기: C, Entropy 측정: H
Diversity score의 범위는 0~1이고 낮으면 낮을수록 정답과 가깝다.
6.2 Qualitative results
생성 이미지는 Fig.9에 있고 우리가 발견한 점은 아래와 같다.
- 특정 class의 EEG 신호로 생성된 데이터들은 대부분 동일한 클래스에 속한다.
= NeuroGAN은 class-specific한 이미지를 합성하고 있다. - 생성된 이미지는 물체를 알아볼 수 있을만큼 선명하다.

6.3 Quantitative results
Quality는 두 Evaluation metrics를 통해 분석한다. class diversity score를 생성하기 위해서 다른 생성기를 사용했다 [9 ref]. 결과의 Diversity score 표 1에 나타나있다.
비교에서 [9 ref] 와 비교했을 때 더 적은 Diversity score를 가지고 있었다.
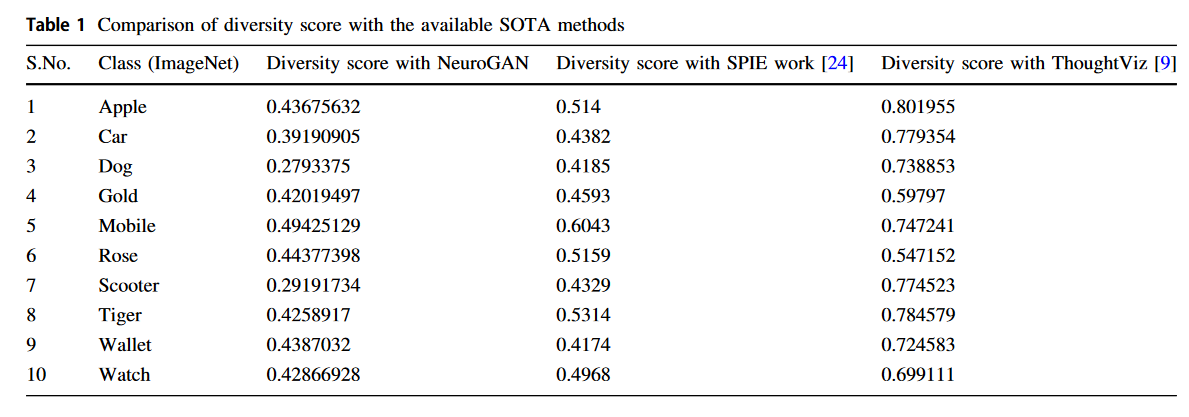
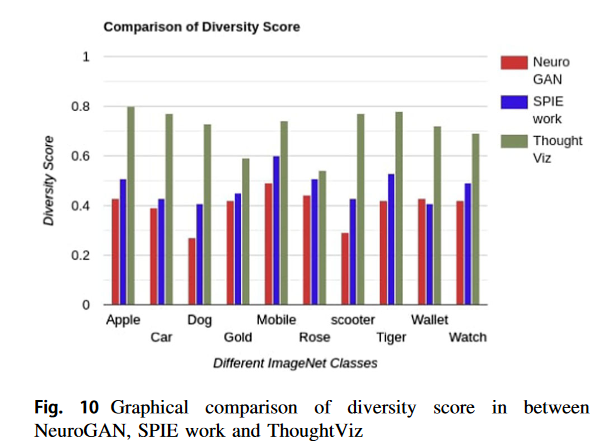
또한 IS도 비교하였다. 다른 방법보다 IS도 높았다. 결과로부터 perceptual loss가 이미지의 퀄리티를 높였다고 주장할 수 있다.

6.4 Ablation study
특정 components들을 삭제하며 결과를 보는 Ablation stud도 진행하였다.
- Condition 1: Attention module X, classifier loss X, perceptual loss X
바닐라 GAN 신경망은 좋은 퀄리티의 이미지를 생성할 수 없었다. 이는 Adversarial loss 만으로는 EEG 신호를 포함하는 cross-domain 합성은 충분하지 않다는 것을 알 수 있다. 이미지를 알아볼 수 없기 때문에 Diversity score와 inception score를 고려하지 않았다. - Condition 2: Attention module X, classifier loss O, perceptual loss X
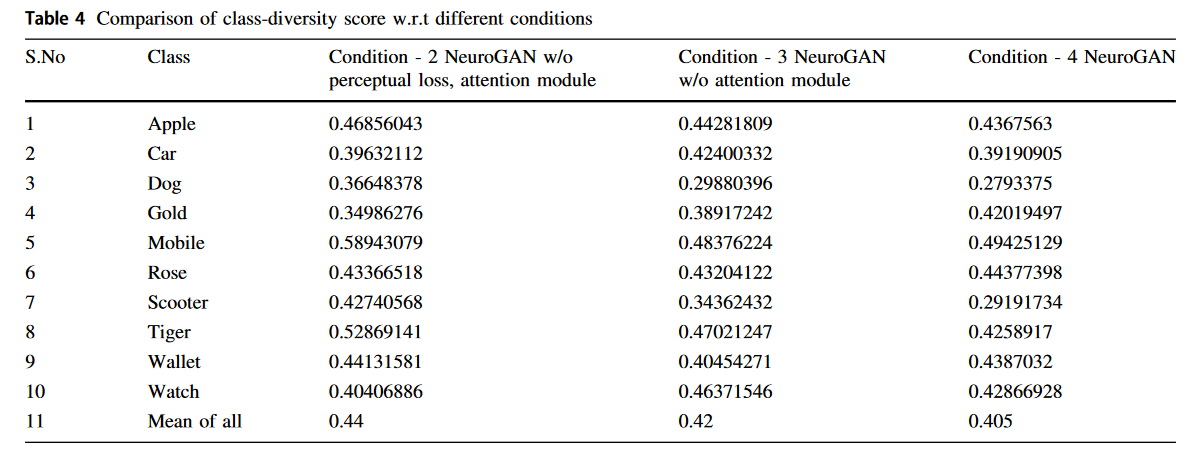
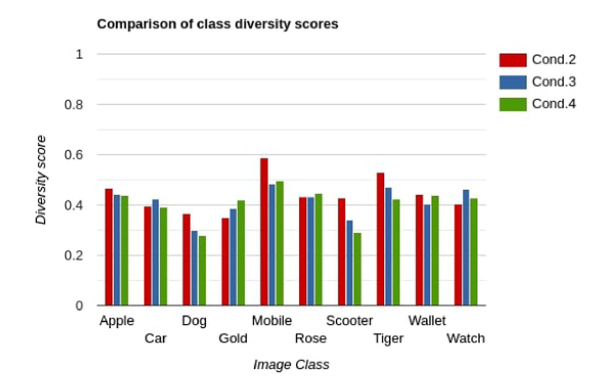
우리는 이전 모델에 classification loss를 계산하기 위해 이미지 분류기를 추가했습니다. 이미지 분류기의 추가는 EEG로부터 class-specific image를 생성하기에 도움을 주었다. 성능의 향상은 Table 4를 통해 알 수 있다. 이 구조를 사용했을때 IS는 4.81이 나왔다. - Condition 3: Attention module X, classifier loss O, perceptual loss O
위 구조를 사용했을 때 class-specific image를 생성할 수 있지만 성능 향상의 여지가 더 있다. 성능을 향상시키기 위해, perceptual loss를 사용했다. 이 loss는 분류기의 높은 층에서 동작하고 high-level 의 의미론적 특징을 판별하는데 도움을 주었다. 그러므로 이 결과는 class-diversity score의 감소로 나타났다. - Condition 4: Attention module O, classifier loss O, perceptual loss O (NeuroGAN)
마지막으로, Attention module을 추가하였다. 이는 관련 특징에 대한 가중치를 주는데 도움을 주고 성능의 향상으로 결과가 나왔다.


그림을 통해 여러 loss를 채용하면서 생성 이미지의 퀄리티가 향상되고 있다는 것을 알 수 있다. Condition-1에서 생성기는 낮은 퀄리티의 이미지를 생성해서 quantative analysis는 고려하지 않았다. Quantative analysis를 위해 다른 컨디션에서 IS를 비교하였다. 표에서 볼 수 있듯이 IS가 향상하는 것을 볼 수 있다.
각 클래스별 Diversity score들도 계산해봤다. 각 조건에 따라 diversity score의 평균이 감소하는 것을 확인할 수 있었다. 이는 생성기의 class-specific image 생성이 향상되었음을 의미한다.
7. Conclusion
이 work에서 우리는 EEG 신호로부터 이미지를 합성하는 Attention 기반의 NeuroGAN을 제안하였다. 다양한 실험을 통해 생성기가 class-specific 이미지를 생성하고 더 나은 이미지를 생성할 수 있음을 보여주었다. Ablation study를 통해 각 components들이 중요함을 보여주었다.
우리의 접근법은 EEG 신호의 생성 임베딩을 동시에 학습하고 클래스에 따라 조건을 지정하고 이 임베딩을 사용해서 이미지를 생성하는 supervised learning 접근법이다. 이 연구의 가설은 클래스와 관련하여 뇌파에 차이가 있는 경우 이러한 차이를 추가로 사용하여 해당 클래스에 특정한 이미지를 생성할 수 있는 더 나은 임베딩을 학습한다. 그러므로 이는 open set 환경에서는 적합하지 않다고 생각한다.
접근방식이 일반적인 뇌 디코딩 영역에서 점진적인 단계가 될 수 있고 재활 및 의사소통과 같은 몇가지 유용한 응용 프로그램으로 이어질 수 있다. (개수가 한정적일때)
