🔍이진논리회귀 vs 다항논리회귀
🔍정규화 vs 표준화
🔍실습코드
📌논리회귀
✔ 이진논리회귀(Binary logistic regression)
대학교 시험 전날 공부한 시간을 가지고 해당 과목의 이수 여부(Pass or Fail)를 예측하는 문제
Independent variable(x): 전날 공부한 시간
Dependent variable(y): 이수 여부이때 우리는 이수 여부를 0,1로 나눌 수 있고, 이런 경우 이진 논리 회귀(Binary logistic regression)으로 해결할 수 있다.
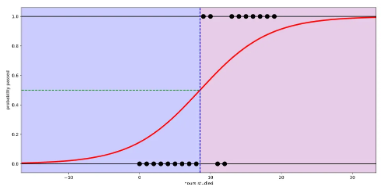
로지스틱 함수는 Independent variable에 어떤 값이든 넣을 수 있지만 Dependent varible 값은 항상 0에서 1사이가 되며, 이를 Pass or Fail로 표현할 수 있다.
🔑 딥러닝에서는 Sigmoid function이라고 부른다.
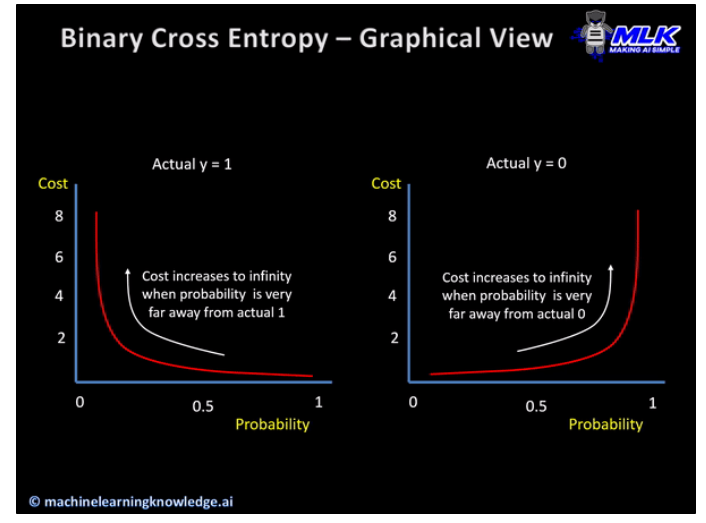
Sigmoid function의 손실함수
y가 1이여야 하는 경우, 0일수록 cost가 무한대
y가 0이여야 하는 경우, 1일수록 cost가 무한대가 된다.

🔑 Keras에서 이진 논리 회귀의 경우 binary_crossentropy 손실 함수를 사용한다.
✔ 다항논리회귀(Multinomial logistic regression)
대학교 시험 전 날 공부한 시간을 가지고 해당 과목의 성적(A, B, C, D, F)을 예측하는 문제
Independent variable: 전 날 공부한 시간
dependent variable: 과목의 성적(A, B, C, D, F)이 문제를 풀기 위해서는 과목을 5개의 클래스로 나눈 방법이 다중 논리 회귀 방법이다.
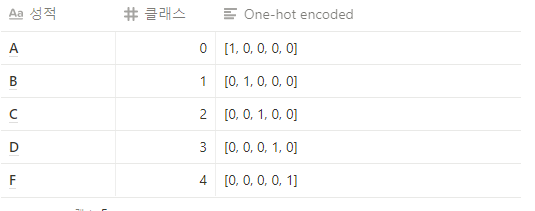
💬 One-hot encoding
원핫 인코딩은 다항 분류(Multi-label classification) 문제를 풀때 출력값을 표현하는 방법.
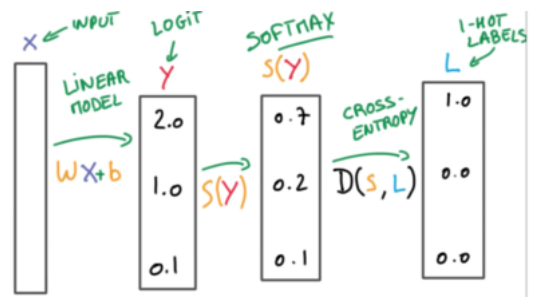
🔑 Softmax함수는 선형 모델에서 나올 결과(logit)을 모두 더하면 1이 되도록 만들어 주는 함수. 예측의 결과를 확률(=confidence)로 표현하기 위함.
📌전처리(Preprocessing)
✔ 정규화 (Nomalization)
정규화는 데이터를 0과 1사이의 범위를 가지도록 만든다.
서로 다른 단위의 데이터를 같은 단위로 만들어 주기 위함.
✔ 표준화 (Standardization)
데이터의 분포를 정규분포로 바꾸는 과정.
즉 데이터의 평균을 0으로 만들고 표준편차가 1이 되도록 만들어줆. 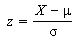
데이터의 평균을 0으로 만들어줄 경우 데이터의 중심이 0에 맞춰진다.(Zero-centered data) 표준편차를 1로 만들어 주면 정규롸가 된다.(Nomalized)
표준화를 시키게 되면 일반적으로 학습 속도(최저점 수렴속도)가 빠르고, local minima에 빠질 확률도 적어진다.
📌실습코드
https://github.com/attabooi/til/blob/main/ml/logistic-regression.md
Reference:
http://cs231n.stanford.edu/2016/
https://www.programmersought.com/article/62574848686/
https://www.tutorialexample.com/implement-softmax-function-without-underflow-and-overflow-deep-learning-tutorial/
https://machinelearningknowledge.ai/cost-functions-in-machine-learning/
https://ursobad.tistory.com/44
