Linear Regression
SGD기법
Keras를 이용한 머신러닝 Linear Regression
🎈 선형회귀분석(Linear regrssion)
주어진 데이터를 가장 잘 설명할 수 있는 기울기의 선을 찾는 분석 방법.
📌OLS(Ordinary Least Squares)기법
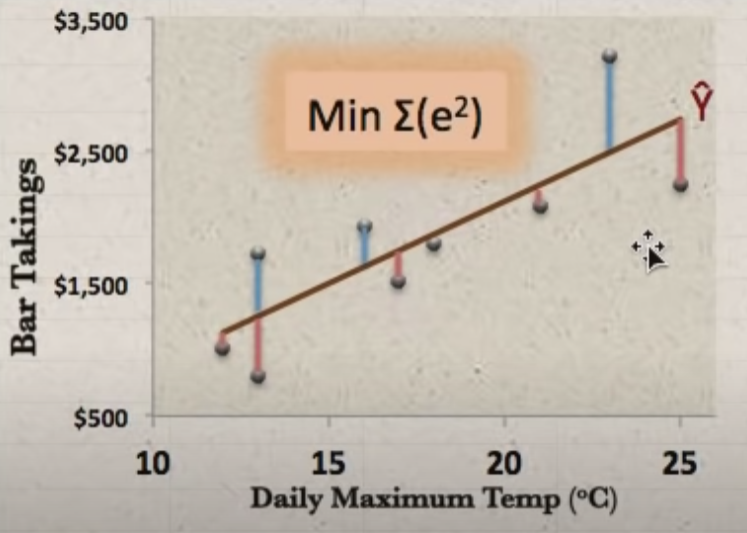
Ordinary Least Square또는 Least Square Method 으로 불리며 에러가 가장 작은 선을 찾기위한 가장 널리 쓰이는 방법 중 하나
값을 예측하는 선이기때문에 당연히 error가 발생하는데 이 error가 가장 적은 선을 찾기 위해서는, Sum of Squared Error 값이 가장 작은 선을 구하는 방법이 OLS기법이다.
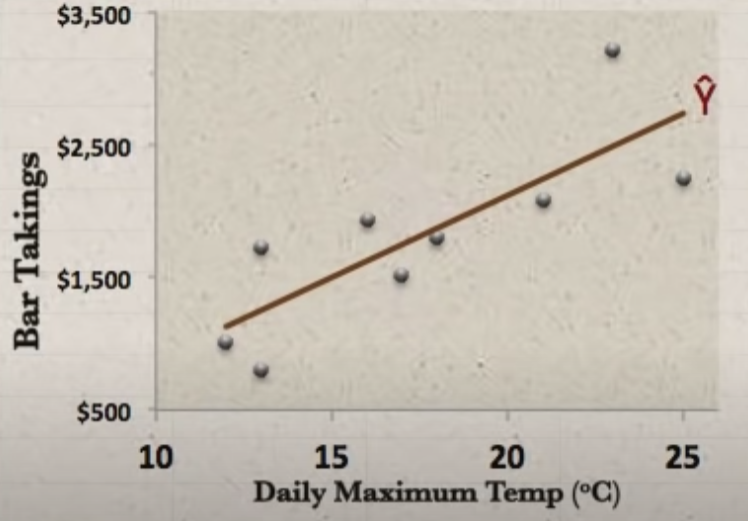
위와 같이 온도와 바의 매출에 대한 데이터가 놓여져 있을때,
Y(매출) = m(기울기)x(온도) + b(상수) 로 표현할 수 있다. 이때 데이터를 예측할 수 있는 최적의 기울기를 구하는 것이 선형 회귀 분석.
🎈 경사 하강법 (Gradient descent method)
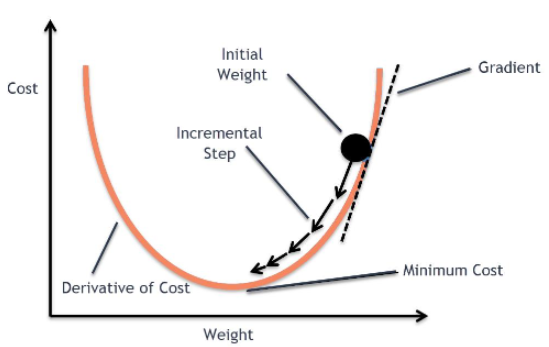
손실 함수를 최소화(Optimize)하기위해 손실 함수의 기울기에 맞게 내려가는 방법
컴퓨터는 경사하강법을 이요하여 문제를 푼다. 랜덤하게 시작된 한 점에서 한 스텝씩 움직이면서 (이때 어느정도 움직일 것인지 정해주는 값이 Learning Rate) 이전 값보다 작아지는 관찰한다. 최소점에 도달하면 종료.
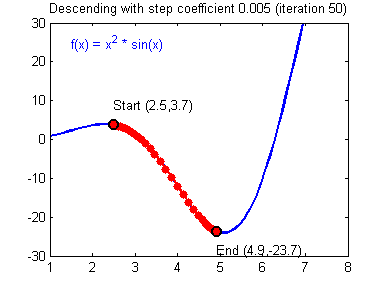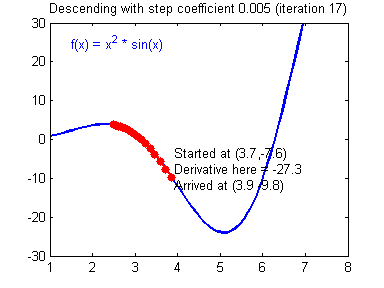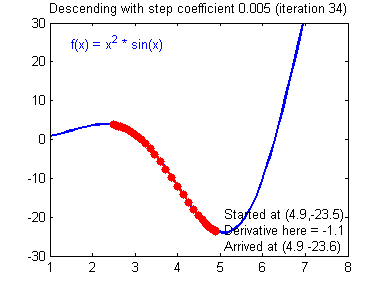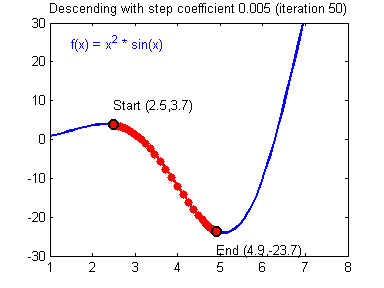
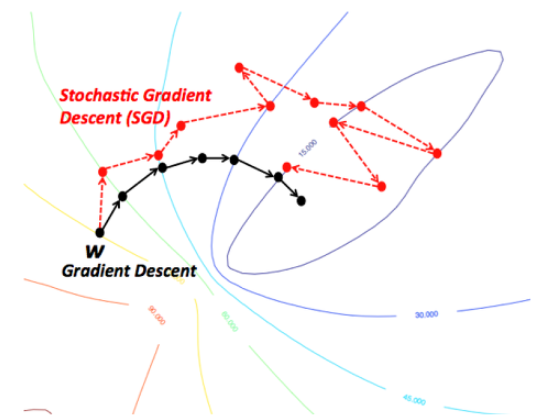
📌SGD(Stochastic Gradient Descent)
통계의 OLS기법처럼 머신러닝을 통해 선형회귀분석을 할때,
Loss function의 최소값을 구하기 위해 현재 wight의 기울기를 구하고 loss를 줄이는 방향으로 반복해서 시행하는 Optimizer 중 하나이다.
모든 데이터(full-batch)를 매 Epoch마다 분석하는 것이 GD(Gradient Decent), 데이터를 쪼개서 정확도는 낮아지더라도 계산 속도를 높이는 방법이 SGD이다.
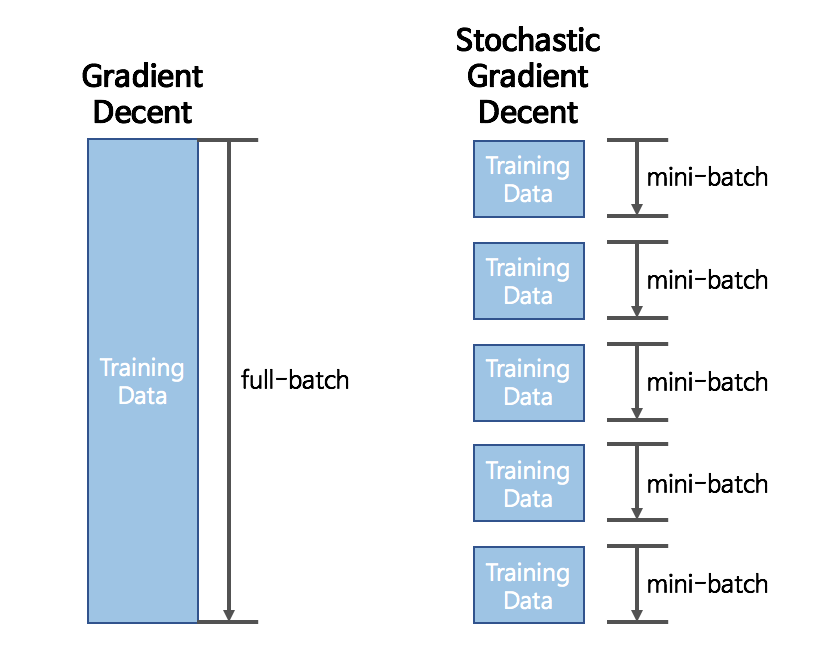
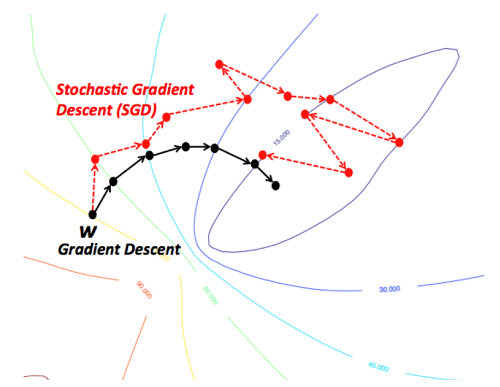
뒤죽박죽 형태로 찾아가지만 속도는 GD보다 훨씬 빠르다.
GD
- 모든 데이터를 계산한다 => 소요시간 1시간
- 최적의 한스텝을 나아간다.
- 6 스텝 * 1시간 = 6시간
- 확실한데 너무 느리다.
SGD
- 일부 데이터만 계산한다 => 소요시간 5분
- 빠르게 전진한다.
- 10 스텝 * 5분 => 50분
- 조금 헤메지만 그래도 빠르게 간다
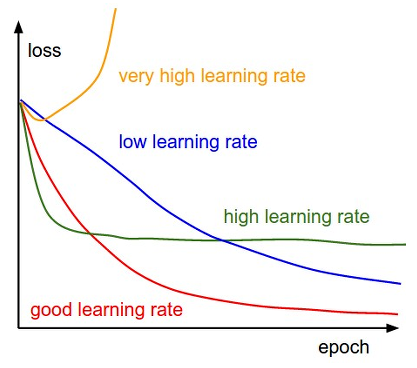
적절한 Learning rate를 찾지 못하면 최적의 값을 구하지 못하거나 학습하는데 너무 오래 걸린다.
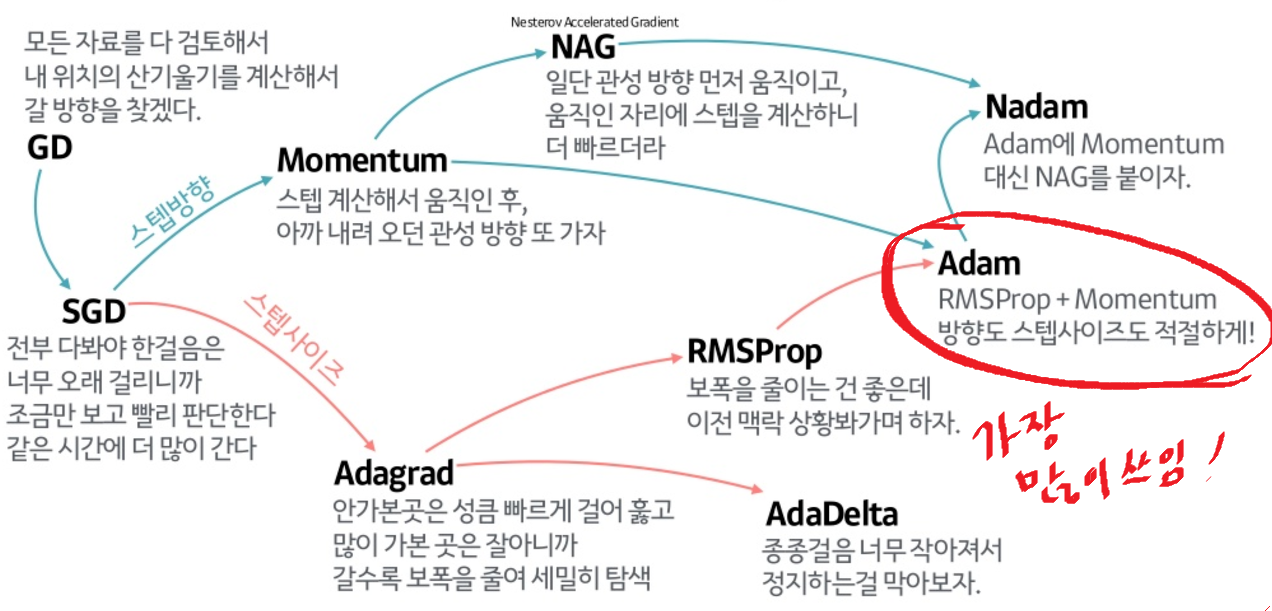
Adam이 가장 많이 쓰인다고 한다. 잘모르겠지만 아직
🎈 Keras를 이용한 머신러닝 Linear Regression
# 데이터셋 준비하기
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d rsadiq/salary # download datasets from kaggle
!unzip salary.zip # unzip# 라이브러리
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('Salary.csv')
df.tail(5)# Linear Regrssion
x_data = np.array(df['YearsExperience'], dtype=np.float32)
y_data = np.array(df['Salary'], dtype=np.float32)
x_data = x_data.reshape((-1, 1)) # -1은 알아서, 1은 행값
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
#
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.01))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)Reference: https://seamless.tistory.com/38
