Pandas를 활용한 통계 데이터 뽑아내기
개요
각 쓰레기통에 라즈베리파이가 있다.
RFID 카드를 리더기에 갖다대면, 쓰레기통이 열리게 되고, 서버와 장비는 통신한다.
일정 시간 이 후, 쓰레기통의 문이 닫히게 되는데, 이 때 쓰레기통을 언제 사용했다는 log 데이터가 담기게 된다.
로그 데이터 형태는
날짜 - 시간 - 빌딩 pk - 층 pk - 쓰레기통 token - 쓰레기통 type이다.
각 로그 데이터 파일은 일일 주기로 갱신된다.
즉, 파일명이 20220501인 경우, 22년 5월 1일에 발생한 건들에 대한 로그 데이터만 담겨있다.
이 축적된 log data를 분석해
각 빌딩 / 층 / 쓰레기통에 대한 시간대별(0시~23시) 및 각 쓰레기통의 종류별(일반/패트/캔/유리/종이) 사용량을 분석하기 위해 아래와 같이 로직을 생각했다.
[1] 로그 데이터 파일 불러온 후 data frame 형태로 변환하기
[2] 날짜를 년 / 월 / 일로 나누기
[3] 시간을 0~23시별로 나누기
[4] 필요한 항목별로 group by 해 데이터 통계 도출 후 json으로 변환하기
[5] django serializer를 사용해 db에 통계 데이터 저장하기
pandas
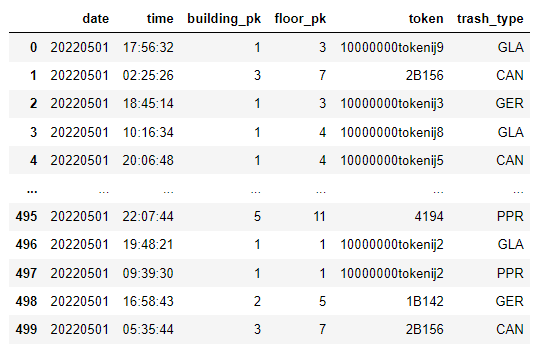
1. log 데이터 불러오기
with open (f'log_dummy/{dates}.log', encoding='UTF8') as f:
records = [line.rstrip().split(' ') for line in f]
columns = ['date', 'time', 'building_pk', 'floor_pk', 'token', 'trash_type']
df = pd.DataFrame(records, columns=columns)log_dummy에서 날짜 별 로그 데이터를 UTF8로 인코딩 후 불러온다.
python with 사용은 with 블로그를 참고했다.
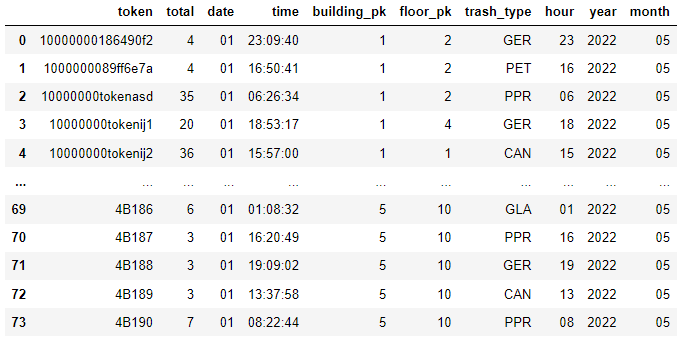
그 후, 날짜 / 시간 / 빌딩 pk / 층 pk / 쓰레기통 식별 토큰 / 쓰레기 타입 컬럼을 사용한 DataFrame을 만든다.
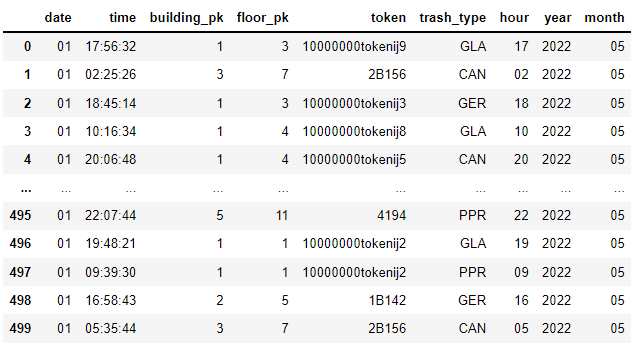
2. 날짜, 시간별 세분화
df['year'] = df.date.str[:4]
df['month'] = df.date.str[4:6]
df.date = df.date.str[6:]
df['hour'] = df['time'].str[:2]year / month / date / hour 컬럼을 새로 정의해준다.
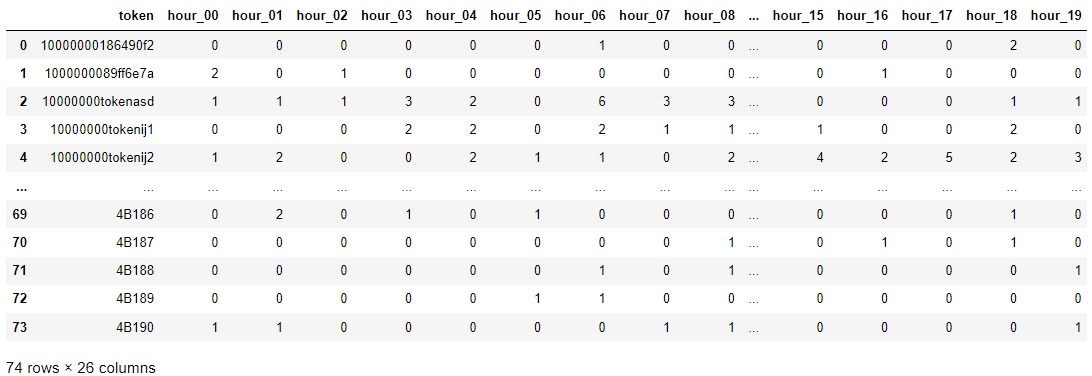
3. DataFrame Merge
right_data = df.drop_duplicates(subset=['token'])
left_data = df.groupby(['token', 'hour']).date.count().unstack(fill_value=0)
left_data.reset_index(inplace=True)
labels = ['token', 'hour_00','hour_01','hour_02','hour_03','hour_04','hour_05','hour_06','hour_07','hour_08','hour_09','hour_10','hour_11','hour_12','hour_13','hour_14','hour_15','hour_16','hour_17','hour_18','hour_19','hour_20','hour_21','hour_22','hour_23']
left_data.columns = labels
left_data['total'] = left_data.sum(numeric_only=True, axis=1)right_data : df를 token을 기준으로 중복된 값들은 제거해준다.
left_data : df를 token 및 hour을 기준으로 groupby 후 컬럼을 labels라는 시간대별 정보로 갱신한다. 그 후 total 컬럼에 해당 token 별 총 사용량을 담아준다.
new_df = left_data.merge(right_data, on='token')
new_df.drop(columns=['time', 'hour'], inplace=True)
new_df = new_df.astype({'floor_pk':'int', 'building_pk':'int'})
types = new_df.drop(columns = ['hour_00','hour_01','hour_02','hour_03','hour_04','hour_05','hour_06','hour_07','hour_08','hour_09','hour_10','hour_11','hour_12','hour_13','hour_14','hour_15','hour_16','hour_17','hour_18','hour_19','hour_20','hour_21','hour_22','hour_23']new_df : left_data와 right_data를 token을 기준으로 merge
=> 각 token 별 시간대별 사용량 및 building, floor pk 정보 등을 담아줌
floor와 building pk의 데이터 형태를 int로 변경 해준다.
그 후, 쓰레기통 종류 별 데이터를 담고 있는 types라는 DataFrame을 만들어준다.
[new_df]
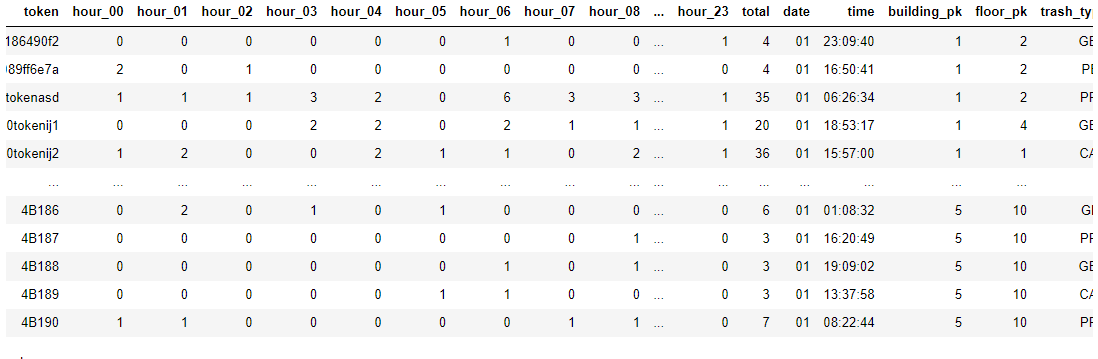
[types]
4. From DataFrame to Dictionary
trashbin= new_df.groupby(['year','month','date','building_pk', 'floor_pk', 'token', 'trash_type']).sum().reset_index()
trashbin_dict = trashbin.to_dict(orient='records')
floor_type = types.groupby(['year','month','date','building_pk', 'floor_pk','trash_type']).total.sum().unstack(fill_value=0)
floor_type.reset_index(inplace=True)
floor_type.drop(columns = ['year', 'month', 'date', 'building_pk'], inplace=True)
floor = new_df.groupby(['year','month','date','building_pk', 'floor_pk']).sum().reset_index()
floor = floor.merge(floor_type, on='floor_pk')
floor_dict = floor.to_dict(orient='records')
building_type = types.groupby(['year','month','date','building_pk','trash_type']).total.sum().unstack(fill_value=0)
building_type.reset_index(inplace=True)
building_type.drop(columns = ['year', 'month', 'date'], inplace=True)
building = new_df.groupby(['year','month','date','building_pk']).sum().reset_index()
building = building.merge(building_type, on='building_pk')
building_dict = building.to_dict(orient='records')각 항목에 맞게 데이터를 변환해준다.
기본적으로 년 / 월 / 일로 groupby 진행해준다.
floor_type, building_type은 types에서 층 / 빌딩 별 데이터를 쓰레기통 종류 별로 받아오는 DataFrame이다.
floor와 floor_type / building과 building_type을 merge 해줌으로써 시간대별 + 쓰레기통 종류별 사용량을 담고 있는 DataFrame을 얻는다.
그 것을 to_dict로 dictionary 형태로 변환해준다.
[floor]
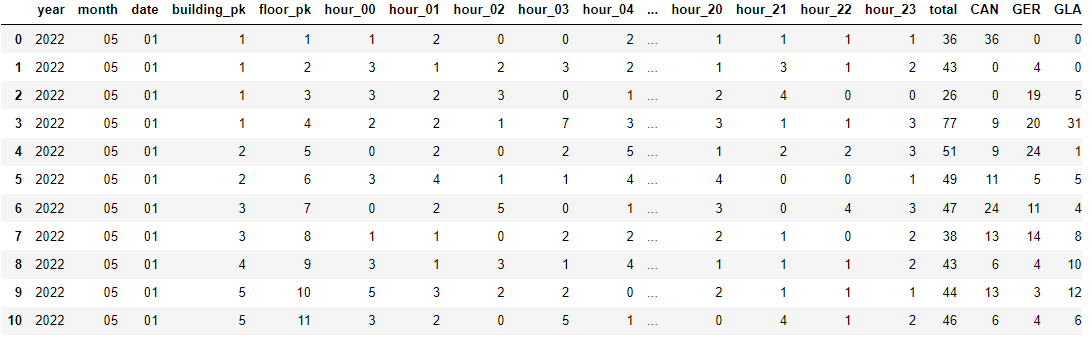
[building]

#floor_dict의 예시
[{'year': '2022',
'month': '05',
'date': '01',
'building_pk': '1',
'floor_pk': '1',
'hour_00': 1,
'hour_01': 2,
'hour_02': 0,
'hour_03': 0,
'hour_04': 2,
'hour_05': 1,
'hour_06': 1,
'hour_07': 0,
'hour_08': 2,
'hour_09': 1,
'hour_10': 1,
'hour_11': 3,
'hour_12': 0,
'hour_13': 0,
'hour_14': 2,
'hour_15': 4,
'hour_16': 2,
'hour_17': 5,
'hour_18': 2,
'hour_19': 3,
'hour_20': 1,
'hour_21': 1,
'hour_22': 1,
'hour_23': 1,
'total': 36,
'CAN': 36,
'GER': 0,
'GLA': 0,
'PET': 0,
'PPR': 0},
...
]Django Serializer
for dic in building_dict:
serializer = BuildingDateSerializer(data=dic)
if serializer.is_valid(raise_exception=True):
serializer.save()
logger.info(f'{dates} : building daily data save completely')
for dic in floor_dict:
serializer = FloorDateSerializer(data=dic)
if serializer.is_valid(raise_exception=True):
serializer.save()
logger.info(f'{dates} : floor daily data save completely')
for dic in trashbin_dict:
serializer = TrashbinDateSerializer(data=dic)
if serializer.is_valid(raise_exception=True):
serializer.save()
logger.info(f'{dates} : trashbin daily data save completely')전달받은 dict 형태의 data를 Django Serializer를 사용해 DB에 저장시킨다.
이 후 전달 완료된 항목을 log로 남겨준다.
