결론 정리 (Abstract/Conclusion)
*BLEU 지표 : 기계 번역 성능을 평가하는 대표적인 자동 평가 지표. 기계 번역된 문장이 사람이 번역한 정답 문장과 얼마나 유사한지 측정. 점수 높을수록 성능 우수.
본 논문의 모델은 크게 두개의 LSTM 네트워크로 구성되어 있다.
-
인코더(Encoder): 입력 시퀀스를 받아서 하나의 컨텍스트 벡터 ****또는 시퀀스 형태의 벡터로 변환
-
디코더(Decoder): 인코더의 출력을 기반으로 새로운 시퀀스를 생성
LSTM 을 사용시 긴 문장에서도 (본 논문에서는) 어려움을 겪지 않았다고 함.
영어-프랑스어 번역 작업으로 테스트를 해 보았을때 본 모델 전에는 통계 기반 기계번역(SMT) 시스템이 일반적이였는데, BLEU 지표 기준 LSTM 기반의 모델이 더 높은 점수를 받았다.
LSTM 기반 모델은 단어 순서에 민감하면서 능동태와 수동태에 따라 변하지 않는 구와 문장 표현을 학습할 수 있었다.
또한 원본 문장의 단어 순서를 뒤집어서 학습 수행 (즉, Encoder 통해 문장 읽을 시 역순으로 읽으면) 성능이 향상되는걸 발견함. 단어 순서를 거꾸로 뒤집어 학습시키면 긴 문장도 무리 없이 번역 가능하다.
예를 들어 :
입력이 - I want to eat now 일때 인풋을 - now eat to want I 라고 모델어 넣는다는 뜻 (번역된 출력은 동일)
이는 번역 과정에서 short-term dependency 를 더 증가시키게 되어 (역전파가 더 쉽게 이루어질 수 있다고 예측) 학습이 쉬워지기 때문이라고 함.
Introduction
본 논문 모델 나오기 전에는 기계 번역이 DNN (Deep Neural Network) 을 활용한 통계적 기계 번역(SMT) 방식으로 사용되었었다.
그런데 이전 모델의 단점은 각 요소들과 관계를 가지고 있는 연속적인 데이터를 가진 언어의 특징 고려가 잘 안됨 → 이 문제가 어느정도 해결이 된 RNN, LSTM 등장 후에는 길이가 정해져 있지 않은, 가변적인 문장을 학습하기 어려워함. (즉, 인풋과 아웃풋 문장 길이가 정해져 있지 않을 때 학습이 불가능했음)
논문의 모델은 LSTM 네트워크를 기반으로 사용하였으나, 긴 문장 학습에 큰 문제가 없었음. 그 이유가 앞서 말한것처럼 역순으로 단어를 input 해서 short term dependency 증가시켜 SGD(Stochastic Gradient Descent)) 과정을 더 수월하게 만들어줌
즉, 출력 문장의 초반부를 생성할 때 중요한 정보를 더 가까운 시점에서 활용할 수 있게 만들어줬기 때문에, 초기 기계번역시 근처 단어가 번역 의미에 영향을 많이 끼쳤던 만큼 성능이 비교적 좋게 측정될 수 있었던 것.
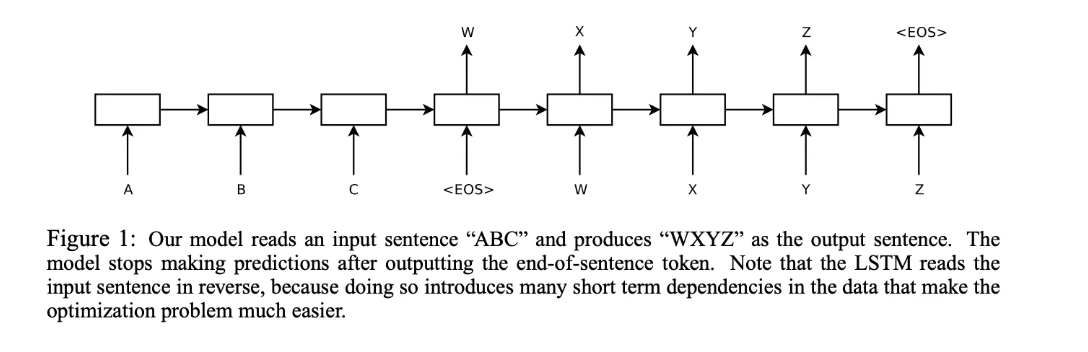
*역순으로 출력한다

yt = 출력값
-
RNN 구조에서는 입력과 출력 사이의 정렬을 미리 알 수 있을때라면 시퀀스와 시퀀스 사이를 쉽게 매핑 가능할 것이다.
-
다만 문제는, 인풋과 아웃풋 시퀀스 길이가 다르면서 단조 관계가 아니라 복잡한 관계일 때는 학습하기 어렵다.
-
RNN 에서 시퀀스 학습을 위해 가장 간단한 전략은 입력 시퀀스를 고정된 사이즈(fixed-size) 벡터로 매핑 후, 이 벡터를 다른 RNN 을 사용해 타겟 시퀀스로 매핑해주는 방법이 있다.
-
근데 이 문제는 Long Term Dependency (장기 의존성 문제) 를 발생시킬 수 있음 (역전파 과정에서 기울기 소실로 인하여 가중치 업데이트 저하)
-
이 문제를 LSTM 으로 해결 가능
-
LSTM 구조일때
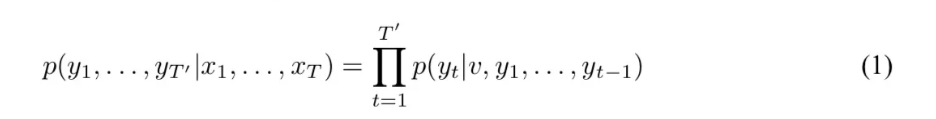
특정 입력 시퀀스 x1…xt 가 주어졌을 때 출력 시퀀스 y1…yt-1 이 생성될 확률을 조건부 확률식으로 표현한 것.
v : 입력 정보를 요약한 벡터 (인코더 최종 상태)
(전체 출력 시퀀스가 나올 확률) 입력 시퀀스 x1…xt 가 주어졌을 때 출력 시퀀스 y1…yt-1 이 생성될 확률 = 이전까지의 출력 단어들과 인코딩된 입력 정보 v를 고려한 상태에서 yt(출력 시퀀스) 가 생성될 확률에 각 단어의 조건부 확률을 모두 곱한 값이다 → 확률을 누적시키는 방식이라는 것.
<특징>
-
Input Sequence, Output Sequence 이렇게 두개의 다른 LSTM 모델을 사용한다.
-
모델 파라미터 수는 늘어나지만, 동시에 연산량은 크게 늘어나지 않으면서 (병렬로 연산 가능)
-
복수 언어 동시 학습하기 쉽기 때문
-
-
깊은 층 구성 LSTM 구조가 적은 층 LSTM 구조보다 더 성능이 좋았음 → 논문 모델은 4개 층의 LSTM 구조 사용
-
입력 문장의 단어 순서를 뒤집는 것이 성능 향상에 큰 도움이 됨 (앞에 강조한 내용)
SGD 과정에서 입력과 출력 사이 연산을 더 쉽게 만들어줌 (단기 한정 입력값 출력값 간격이 짧으니까)
Experiment
- Data
- WMT' 14 영어 -> 불어 기계번역
- 데이터셋 : WMT’ 14 영어-불어 데이터셋
- 16만 개의 빈도 높은 단어(소스 언어)와 8만개의 빈도높은 단어(타겟 언어)를 사용해 단어 사전 구성함
- . Decoding & Rescoring
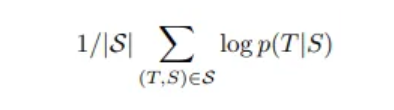
T : 올바른 번역
S : 원본 문장(training set)
Log likelihood 를 최대화 시키는 방향으로 학습시킨다.
p(T|S) = 주어진 입력 문장 S 에 대해 번역된 문장 T 가 나올 확률
1/S 를 곱하는 이유는 모든 문장 쌍에 대해 동일 중요도를 가지게 계산하기 위해.
→ 핵심은 모델이 출력하는 T 가 실제 정답 확률 p(T|S) 를 최대화하는 방식으로 LSTM 을 학습시킨다는 뜻
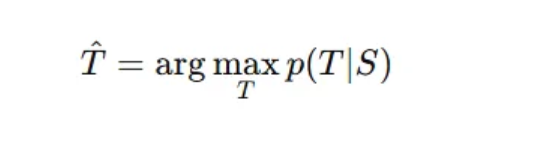
예측된 번역 결과 T(^) 가 입력 문장 S 에 대해 가장 확률 높은 번역 T 를 출력하는 방식으로 번역 결과를 낸다는 뜻.
-
Left-to-Right Beem Search 디코더를 통해 번역 문장 생성
- 여러 개의 후보 문장을 동시에 고려하면서 가장 가능성 높은 문장을 선택 → 이걸 왼쪽에서 오른쪽 방향으로 진행
-
디코더의 번역 단어에 대한 가설 (번역 결과 가능성 말하는듯) 를 확장해나가며 학습하다가 그 중 가장 가능성이 높은 번역 결과 log 확률 최대 되는 걸 선택하고, 나머지는 버린다.
-
빔 사이즈 (Beam Search에서 한 번에 유지하는 후보 개수, 즉 가장 가능성 높은 k 개의 다음 단어) 가 1일때도 성능 좋았고 빔 사이즈 2이면 빔 서치 사용할 때 모델이 가질수 있는 이점을 다 포함한다.
- 문장 뒤집어서 넣기
-
앞서 말한것처럼 문장 뒤집어서 학습시켰더니 test perplexity (낮을수록 좋음) 수치가 떨어졌고 (5.8→4.7) BLEU 스코어는 상승함 (25.9→30.6)
-
문장 뒤집어서 넣었기 때문에 디코더가 처음 학습할 단어가 인코더에서 가장 나중에 처리됨 → 긴 문장 학습 시 멀리 떨어져 있는 단어 기억을 더 잘함 (최소한 처음 나오는 몇 단어들이 타겟 문장 단어와 매우 가까움) → 정보 손실 줄임
→ 생각보다 논문의 모델은 긴 문장에서도 LSTM 구조가 잘 작동했다고 함
→ (개인 생각) : 다만, 이게 어디까지나 논문 나왔던 당시 이전에 비해 번역 성능이 올라갔다는 것이지 궁극적으로 문제를 해결한건 아니라고 봄. 초창기 기계번역은 거꾸로 입력해서 임시적으로 번역 결과 처음 몇단어의 인풋 타겟 처리 시간은 줄여 이전에 비해 기억 손실을 줄인것일 뿐..!
