핵심 : 통계적 분석 방식과 단어 유사도 임베딩 방식의 장점을 결합해 새로운 임베딩 기법을 제시했다.
Co-occurrence 확률을 벡터의 유사도를 의미하는 내적값과 같아지도록 목적함수를 설계
Introduction
언어의 의미 벡터 공간 모델은 각각의 단어를 실수 벡터로 표현한다.
이러한 벡터는 정보 검색, 문서 분류, 질의응답 시스템, 개체명 인식, 구문 분석 등 다양한 응용 분야에서 사용된다.
보통의 경우 word vector 방법이 벡터간 각도나 거리로 의미 표현 판단 했었음.
그런데 최근 Mikolov et al.(2013c) 논문에 의하면 단어 벡터 공간의 세부 구조를 평가하기 위해 단순 거리 대신 벡터의 여러 차원 차이를 탐구하는 새로운 평가 방식을 제안했음.
예를 들어, "king is to queen as man is to woman"이라는 유추를 단어 벡터 공간에서 king − queen = man − woman이라는 벡터 방정식으로 표현할 수 있어야 한다는 것.
Glove 모델은 word-word co-occurerence 를 통해 어떻게 의미를 만들 것인지에 집중함.
Glove 모델은 global log-bilinear regression model로, global matrix factorization(통계적 정보 활용)와 local context window method(단어 사이의 여러 측면에서의 유사도) 두 방법론의 장점을 골라 만들어진 모델이라고 볼 수 있음.
- 이전 연구
- Matrix Factorization Methods
- ex. LSA, HAL, COALS 등
통계적 정보는 잘 알아내지만 단어의 유사도는 고려하지 않기 때문에 의미론적 정보는 잘 알아내지 못한다. (통계적으로 the, a 많이 나온다고 해서 해당 코퍼스의 의미가 the,a 와 관련이 많은게 아닌것처럼)
- Shallow Window-Based Methods
- ex. Word2vec (CBOW, Skip-gram) 등
코퍼스의 주변 단어를 활용해 단어의 의미론적 정보는 잘 알아내지만 Global Co-occourrence 및 코퍼스 내 통계적 정보를 잘 보지 못한다.
중심단어를 통해 주변에 있는 단어들을 잘 예측하는 단어 벡터 표현 학습 방법. 입력 벡터를 원-핫벡터로 변경해서 주변 단어를 윈도우 크기만큼 잘라서 예측.
—> 이 두 방법론의 장점을 골라 만들어진 모델이 GloVe Model
모델의 수식

<수식 설명>


-
7번에서 MSE Loss Function 쓰는 이유 + 8번의 가중치 함수

-
bias 를 i 에 대한것과 k 에대한걸 둘 다 넣어주는 이유는 i 와 k 가 바뀌어도 성립이 되어야 하기 때문이다.
-
또한 아래 f(xij) 를 추가하는 이유는 log 값에 의해 만약 xij 빈도수가 너무 작으면 제곱한 값이 무한에 가깝게 되기 때문에 이를 조절하기 위해 f(xij) 를 앞에 곱해줘서 추가.
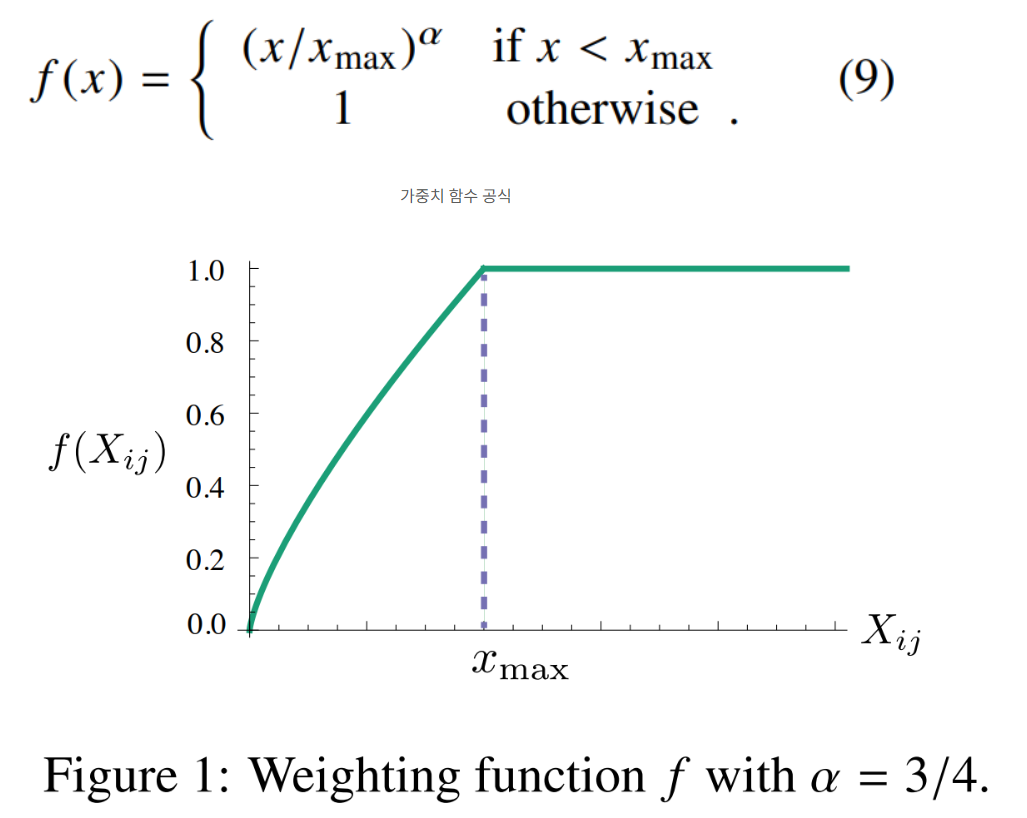
가중치 함수 공식은 다음과 같이 둬서 발생 비율 적은 단어는 반영 적게 되도록 만들었다.
결과 측정
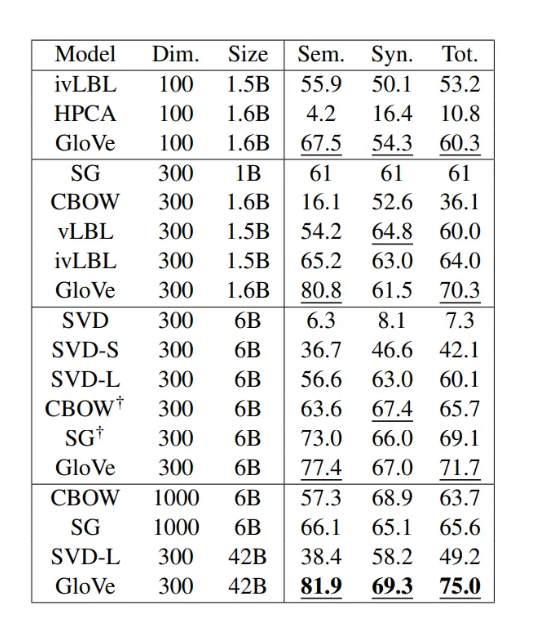
Word Analogy 방식으로 다른 모델들과 성능을 비교한 것
다른 모델들보다 성능이 매우 뛰어남을 확인할 수 있음
Word Analogy 방식이란 a is to b as c is to __? 식으로 빈칸을 채워넣는 질문 형태로 이루어져 있음.
앞서 king − queen = man − woman 의 방식으로 찾는것처럼 빈칸 d 에 맞는 단어를 찾기 위해 b-a+c 와 가장 가까운 d 를 찾는 방식으로 답을 구함
이때 가장 유사한 d 찾는데에는 벡터끼리 계산해 코사인 유사도 사용함
비지도학습에서 특히 큰 성과를 얻는다는 것을 알 수 있음
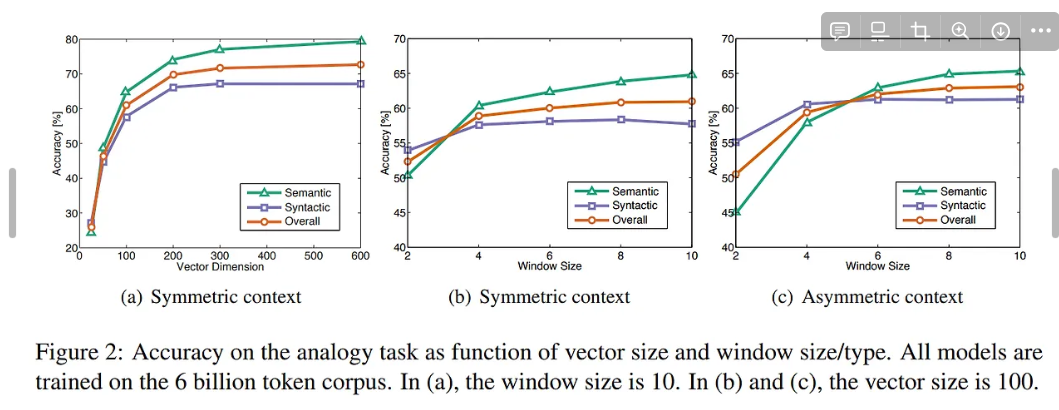
Symmetric : Context Window 가 오른쪽, 왼쪽 다 있을 때
Asymmetric : Context Window 가 왼쪽에만 있을 때
모델 분석
- 코퍼스 사이즈 크면 성능 더 좋음
- 문법정보(Syntactic) 는 asymmetric context 일때 더 성능 좋다. 즉 연관성보다는 즉시성에 더 잘 나타나고 순차적인 정보에서 더 잘 정보 추출 쉬움
- 반면 의미 정보는 윈도우 사이즈가 클수록 정보 추출이 더 쉽다
- Training Time 에 대한 GloVe 성능
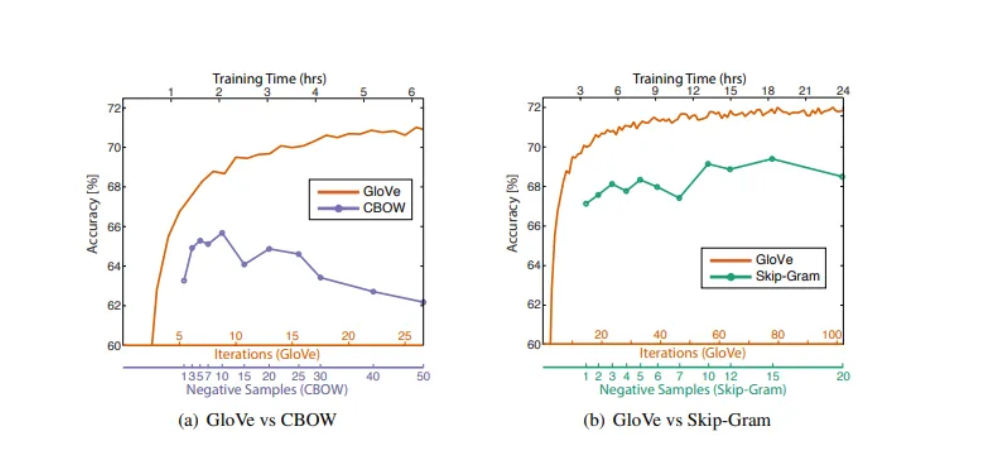
- GloVe 요약
- *전역 정보(Global Co-occurrence Information)**를 기반으로 단어 간의 관계를 학습
- 단어의 공기행렬(co-occurrence matrix)을 활용하여 전체 코퍼스에서 단어 쌍이 등장하는 빈도를 학습
- 손실함수 반영하여 MSE 최소가 되는 방식으로 학습시키는 방법, 즉 오차를 최소화시키는 방식
- Global Co-occurrence
Co-occurrence (공기 빈도)란?
두 단어가 같은 문맥이나 범위 내에서 함께 등장하는 것을 말합니다. 예를 들어, 다음과 같은 문장이 있다고 가정합시다:
이 문장에서 "king"과 "queen"은 서로 가까운 위치에 나타납니다. 따라서 이 둘은 공기(co-occurrence) 관계가 있다고 말할 수 있습니다. 공기 빈도(co-occurrence frequency)는 이 관계가 얼마나 자주 발생하는지를 수치적으로 나타냅니다. Global Co-occurrence:"The king and the queen ruled the kingdom together."
- 코퍼스 전체에서 두 단어가 함께 등장하는 빈도를 측정합니다.
- 특정 문맥(윈도우 크기)에 국한되지 않고, 전체 텍스트 데이터를 활용해 계산됩니다.
