Improving Mispronunciation Detection with Wav2Vec2 - based Momentum Pseudo-Labeling for Accentedness and Intelligibility Assessment (2022)
Text & Speech Papers
✔ Basic Info
📌 Improving Mispronunciation Detection with Wav2Vec2 - based Momentum Pseudo-Labeling for Accentedness and Intelligibility Assessment (2022)
🔗 https://arxiv.org/pdf/2203.15937
☑️Sum-up
Teacher-Student Method 과 Psudo-Labeling 이라는 개념 도입하여 사전 학습과 후속 task 학습 간 차이를 줄여 오류를 줄인다. 방법론적으로 잘 모르던 부분이라 어려웠지만 특이하다고 생각했다.
☑️Glossary
- Pseudo Labeling : 반지도 학습 방법 중 하나로 라벨이 없는 데이터에 대해 라벨이 있는 데이터로 예측하는 방법
- Online Model : 실시간으로 학습되는 현재 모델 (training 중 계속 바뀌고 있는 현재 모델)
- EMA : 최근 데이터에 더 큰 비중을 두어 데이터의 최신 변화를 더 잘 반영하는 계산 방법. 실시간 추세 파악에 유용한 계산 방법이다

✅Abstract
MDD(발음 오류 탐지 및 진단) 시스템은 end to end 음소 인식 통해 우수 성능 달성하고 있다.
그러나 주요 문제는 실제 L2 화자의 자연스러운 음성에 대해 사람이 라벨링한 음소 데이터가 부족하다는 것이다.
그래서 이 연구에서는 라벨 없는 L2 음성을 Pseudo Labeling 절차를 통해 사전 학습된 자기 지도 학습 모델을 기반으로 미세 조정 방식을 확장함
Wav2vec2 를 Self-Supervised Learning (SSL) 모델로 사용하며 원래 라벨이 있는 L2 음성과 생성된 가짜 라벨이 부여된 L2 음성 데이터를 통해 모델을 미세조정한다.
Pseudo-Label 은 동적으로 생성되며 현재 모델과 과거 모델 예측을 앙상블해서 미리 저장하지 않고 학습 중 실시간으로 생성되는 방식을 따른다 → 가짜 라벨의 노이즈 줄이기 위한 것임
이런 Momentum Pseudo Labeling (MPL) 적용한 fine-tuning 이 기존 fine-tuning 보다 PER 은 5.35% 낮아지고 F1 은 2.48% 향상됨
✅Introduction
본 연구는 L2 화자의 이해 가능성과 억양 평가를 위한 음소 수준의 발음 오류 탐지에 초점 맞춤
-
대부분의 음소 수준 발음 오류 및 탐지 (MDD) 시스템은 DNN (Deep Neural Networks) 기반 아카텍처가 L2 화자 음성을 입력받아 end to end 음소 인식을 하는 구조이다.
-
근데 Data sparsity 즉 데이터 희소성이 문제임 → 이 문제를 해결하기 위해선 pre-training + fine-tuning 이 효과적인 것으로 나타남.
-
대규모 비라벨 데이터에서 SSL(Self Supervised Learning) 통해 모델 사전학습 시킨 후 → 목적에 맞는 라벨 있는 데이터로 미세 조정하는 방식이 효과적인걸로 나타남.
-> 이 방법이 발음오류탐지 등 다양한 후속 테스크에서 우수 성능 보임
BUT Vanilla fine-tuning, 즉 사전 학습된 모델을 후처리 없이 바로 라벨 있는 데이터로 학습시키는 방식은 도메인 차이, 즉 사전학습에 사용된 음성 데이터와 실제 후속 task 간 스타일 차이로 성능 저하 발생 가능.
이 문제 해결하기 위해 pseudo labeling 기반 semi-supervised-learning 사용하게 됨
본 논문에서는 모멘텀 가짜 라벨링 (MPL) 방식 제안.
Teacher-Student 구조에서 동적으로 실시간으로 가짜 라벨을 생성하는 방식이다.
이때 Student Model 은 EMA (지수 이동 평균) 기반 Teacher 모델이 생성한 가짜 라벨로 학습됨
EMA : Exponential Moving Average 를 말하며 과거 모델 가중치를 지수적으로 평균내 더 안정적인 교사 (teacher) 모델 만드는 방식. Noisy 한 라벨링을 완화한다.
Teacher Model 은 실시간 (online) 모델의 가중치에 대한 모멘텀 기반 이동 평균 유지
실시간 (online) 모델이 가짜 라벨 노이즈에 강인하게 만들고 라벨 없는 데이터에 대한 학습 안정화함
그 결과, MPL 사용한 미세조정이 단순 미세조정보다 PER 5.35% MDD F1 은 2.48% 향상
또한 추가로 MDD 모델을 자동으로 L2 화자의 이해 가능성과 억양을 평가하는 방향으로 학습시킴 → 인도식 영어 억양 가진 L2 데이터셋에서 공개 테스트 수행
결과에 따르면, 사람의 청취 테스트 통해 MDD 모델의 음소 인식 성능이 L2 화자의 이해 가능성과 억양에 대한 사람의 평가와 높은 상관관계 보임을 확인함
즉, MDD 모델의 예측과 사람의 인식이 잘 align 되어 있음을 보여줌
💡 Student Model 과 Teacher Model 동작 방법
- 학생 모델 (Student Model) : online model 임 - 즉 계속 업데이트 되고 학습하는 모델
- 교사 모델 (Teacher Model) : EMA 으로 누적하는 모델로 학생 모델의 가중치를 매 스텝마다 지수 이동 평균으로 누적한다는 말
teacherweights_t = a * teacher_weights(t-1) + (1-a)*student_weights_t
a : 모멘텀 계수
student model 은 teacher 가 제공한 더 업데이트된 가짜 라벨로 학습 → 불안정 or 폭주 (update explosion) 방지
즉, Student Model 이 실제 학습 대상 (매 스텝마다 gradient update 변함)
Teacher Model 은 Student Model 의 가중치를 EMA 로 누적하여 만든 ‘예측기’ 임
student model 이 학습을 하고 (라벨 있는 데이터나 teacher 가 만든 pseudo label 로) teacher model 은 학습 안하고 대신 student 가중치를 가져와서 EMA 방식으로 업데이트 하며 노이즈 덜낀 pseudo label 생성에만 사용
✅Related Work
-
MDD (발음 오류 탐지) 분야에서 GOP - ASR 이 출력하는 음소 후 확률 값 기반으로 발음 오류 평가했음 (즉 특정 음소가 발화되었을 확률 계산)
-
end-to-end 방식 음소 인식으로 wav2vec2 를 미세조정하는 방법이 사용되었었다.
BUT 논문은 라벨 없는 도메인 특화 L2 음성 데이터 활용해 MDD 성능 향상시키는데 중점줌
이전 연구는 라벨 있는 데이터만 초점 맞췄고 이 논문은 라벨 없는 데이터의 pseudo labeling 연구함
Pseudo-Labeling 은 Offline PL (한번에 라벨 예측하고 저장) 과 Online PL (학습 중 실시간으로 라벨 생성) 로 나뉨
Offline PL : 따로 학습된 교사 모델 사용해서 라벨 없는 샘플에 대해 pseudo label 할당 → 즉 정지된 모델 사용해서 unlabeled data 에 예측 (저장해서 사용)
Online PL : 실시간으로 현재 학습 중인 모델에 의해 pseudo label 생성. 이 논문은 이 방법을 택하면서 단순히 현재 student model 을 teacher 로 사용하는게 아니라 모멘텀 업데이트 도입해서 라벨 노이즈 줄임
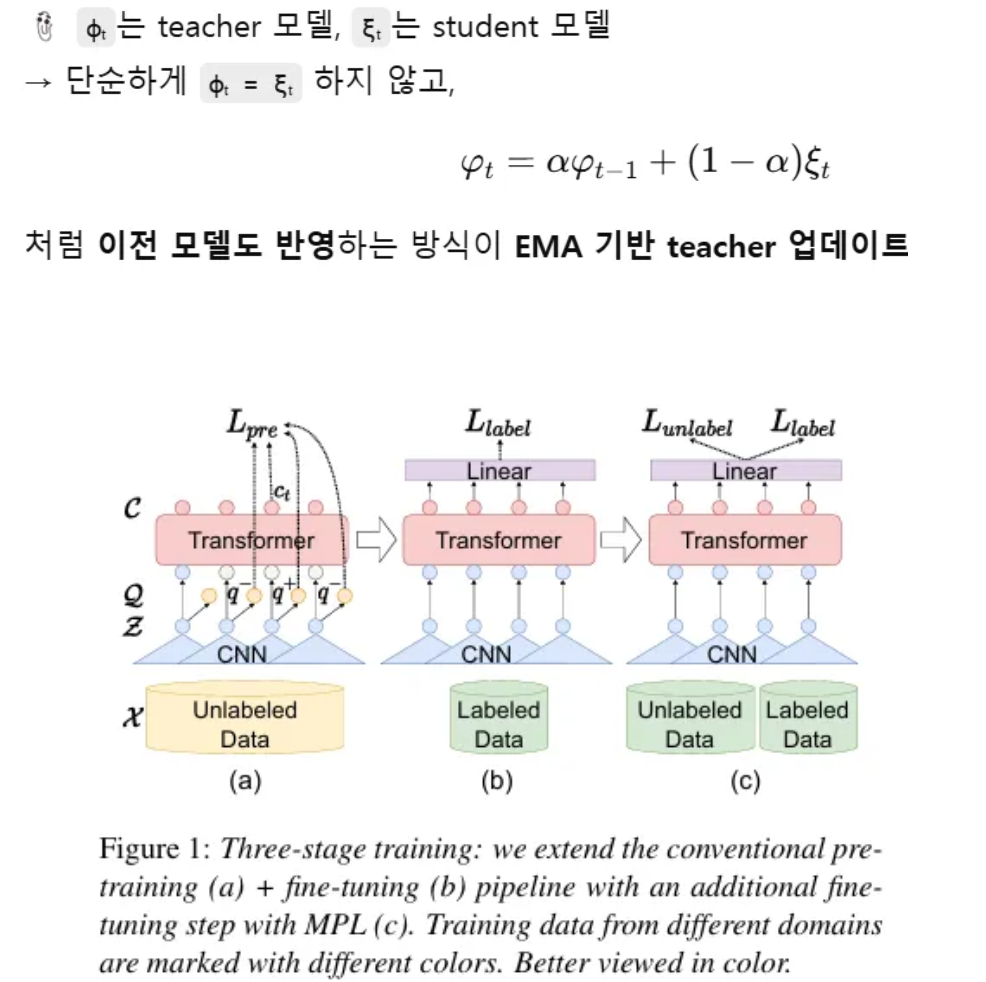
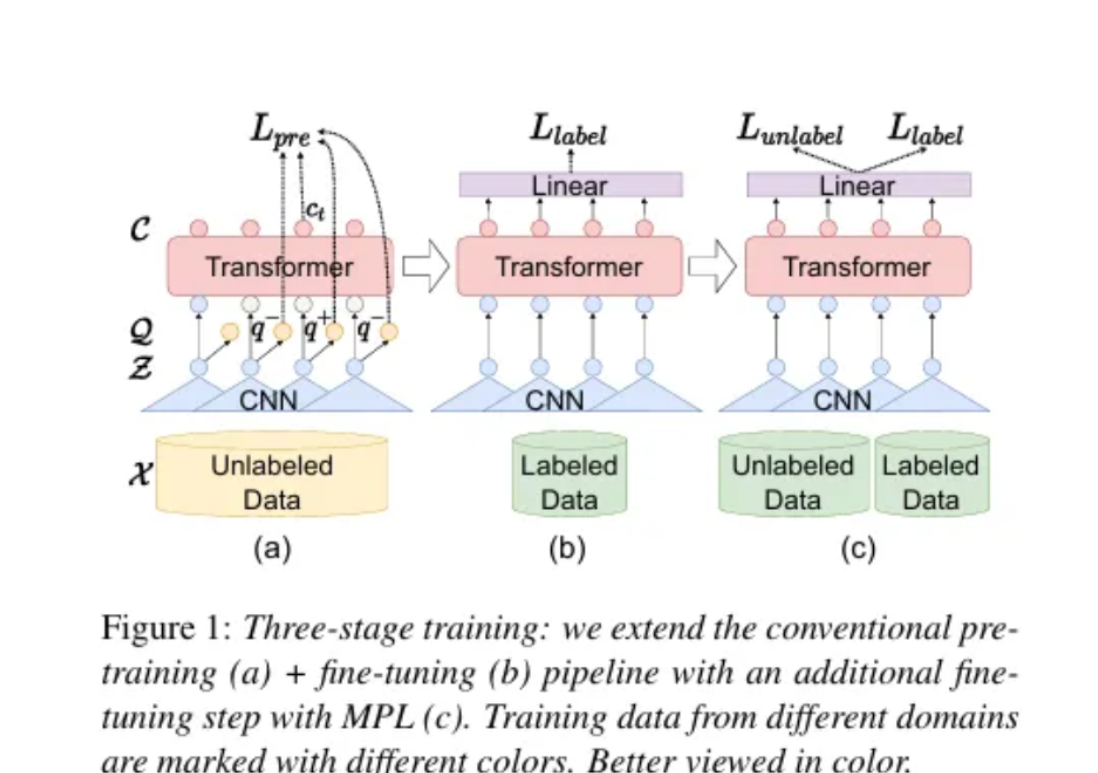
a : 기본 wav2vec2 로 학습 (unlabeled data ) - 사전 학습 시키는거임
b : 기존에 많이 사용하던 방식으로, 라벨이 있는 데이터로 모델 미세조정 (fine-tuning) + linear layer 추가 (음소를 인식해야 하니 특정 phoneme label 에 대응시켜야 하니까)
c : Momentum Pseudo Labeling 기반 Fine-Tuning
✅Method Explained
1️⃣ Teacher 모델이 Unlabeled Data에 대한 pseudo-label 생성
- 현재 시점의 Teacher 모델을 사용해 unlabeled data에 대해 pseudo-label 생성
- 이때 사용하는 Teacher의 가중치는 직전 스텝까지 EMA로 누적된 값
2️⃣ Student 모델 학습시킴
- Student 모델은 Labeled data 와 Unlabeled data 둘 다 사용해서 학습한다.
- Labeled data는 진짜 정답으로 학습
- Unlabeled data는 방금 Teacher가 만든 pseudo-label로 학습
- Loss 계산은 unified loss L 사용

- Loss 계산 → Backpropagation → Student 파라미터 업데이트 (student_weights_t)
3️⃣ EMA로 Teacher 업데이트
- Student 업데이트 직후
- Student의 새로운 파라미터로 Teacher 모델을 EMA 방식으로 누적 업데이트
- teacherweights_t = a * teacher_weights(t-1) + (1-a)*student_weights_t a : 모멘텀 계수
4️⃣ 다음 스텝으로 넘어가서 pseudo-label 생성
- EMA 업데이트된 Teacher model이 새로운 pseudo-label 생성에 사용됨
✅Experimental Setup
✅Datasets : L2 ARCTIC(L2 화자가 영어로 말한 음성을 수집한 발화 corpus. 각 화자에 대해 15% 발화에 대해 사람이 실제로 들은 대로 라벨링한 음소가 제공.) - 6명의 화자에 대해 라벨 있는 발화는 테스트셋으로 사용, 나머지 화자들의 발화는 라벨 없는 학습용 데이터로 사용
추가로 UTD-4Accents 라는 자체 구축 데이터 사용 (L1 영어, 오스트레일리아, 스페인, 인도 억양 포함)
발화 내용은 일반 어휘, 음성 검색 등 다양한 도메인에서 수집된 읽기 음성
✅Evaluation : PER, MDD Metrics, F1, Precision, Recall,
Implimentation Detail : wav2vec2-base / wav2vec2 base 960h (LibriSpeech 960 시간 fine-tuned)
후자는 사전학습 후 LibriSpeech 데이터로 ASR fine-tuning 더 되어 있는거라 표준 영어발음에 더 적합하게 조정된 모델
✅Results
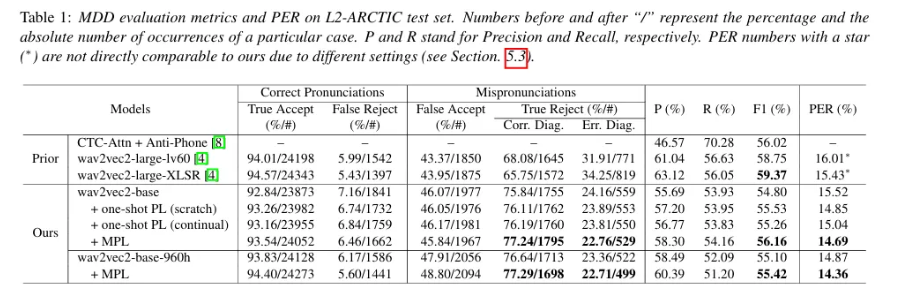
-
wav2vec-based 기본 finetuning (b 단계까지만 학습)시 F1 : 54.8, PER 15.52→ MPL 적용시 56.16 14.69 개선
-
wav2vec-base-960h 기본 finetuning (b 단계까지만 학습)시 F1 : 55.10 PER 14.87 → MPL 적용시 55.42, 14.36 개선
즉 MPL 적용시 확실한 성능 향상.
또한 MPL 이 기존 고정 one-shot PL 보다 우수함.
one-shot 고정 PL 모두 라벨 있는 데이터만 학습한 baseline 보다는 성능 좋음. 다만 MPL 적용한 모델이 wav2vec2 960, wav2vec2 에서 모두 우수.
기존 연구와 비교시, CTC Attention 모델에 anti-phone(유사 음소 증강) 보다 논문 모델이 F1 score 더 우수하다.
다만 대규모 wav2vec2 모델 (wav2vec2 large) fine-tuning 보다 전체 성능(F1 Score) 은 뒤쳐짐
BUT
- Correct Diagnosis (실제 발음 상태를 정확히 진단한 비율) 은 더 높으며
- Error Diagnosis (실제 발음을 잘못 진단한 비율) 은 더 낮다.
이는 실제 발음 진단에서는 논문 모델이 더 우수할 수 있음을 시사함.
✅추가 실험 - 인도 억양 및 전달력 평가
가설 : 좋은 MDD 모델은 사람과 비슷하게 L2 발음 인식해야 함.
음소 인식 성능과 발음 억양 (Accent) 과 전달력 (Intelligibility) 사이의 어떠한 상관관계가 존재할 것이라고 함.
PER 높을수록 → 발음 오류 많고, accent 강하고, intelligibility 가 낮을 가능성 있다.
결과 (accentedness 는 1-9 중 1 이 악센트 센거)
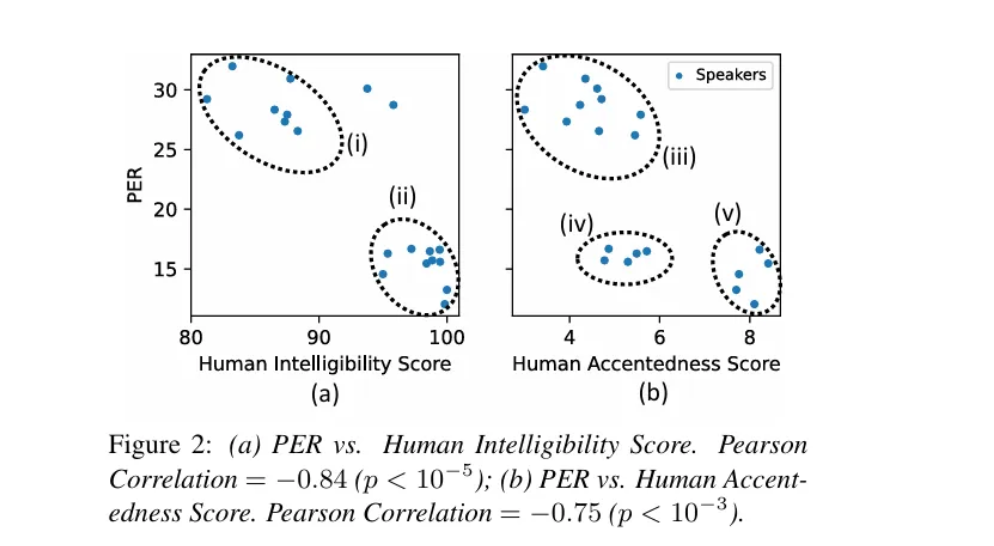
✅a : PER-intelligibility
i : 높은 PER - 낮은 전달력
ii : 낮은 PER - 높은 전달력
가설과 동일한 음의 상관관계 확인
✅b: PER-accentedness
역시 예측과 비슷하나 특이점은 iv 클러스터 (심한 accent, 낮은 PER) → 전달력 파트에서는 ii (낮은 PER, 높은 전달력) 에 속하는 사람들이였음.
이 말은 외국어 억양 강해도 전달력 높을 수 있음을 시사함
MDD 모델은 음소 오류 위주로 탐지가 더 적합하며 운율 기반 억양 평가는 한계가 있음을 알 수 있다.
✅Conclusion
Pseudo-labeling 통해 라벨 없는 L2 발화 활용해 MDD 성능 높이는 방법 제안함
MDD 모델 활용해 자동 L2 언어 이해도 및 억양 평가 확장 가능성 열었음
청취 테스트 통해 MDD 모델의 예측 결과를 사람의 인식 간 강한 상관관계 확인함
