wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations (2020)
Text & Speech Papers
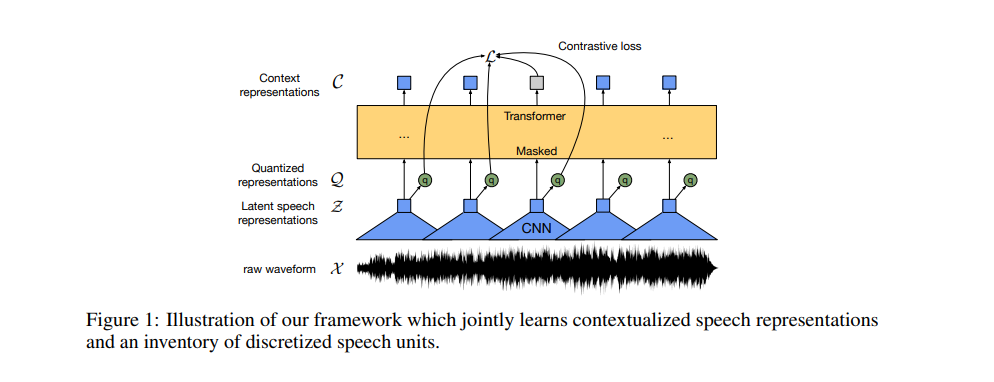
1. Introduction
Wav2vec 2.0 은 음성 데이터에서 벡터화된 representation 을 Self-Supervised Learning (자기지도학습) 으로 학습하는 방법이다.
일단 Unlabeled 음성 데이터로 사전학습 시키고, Labeled 데이터로 미세조정 시키는 방식임
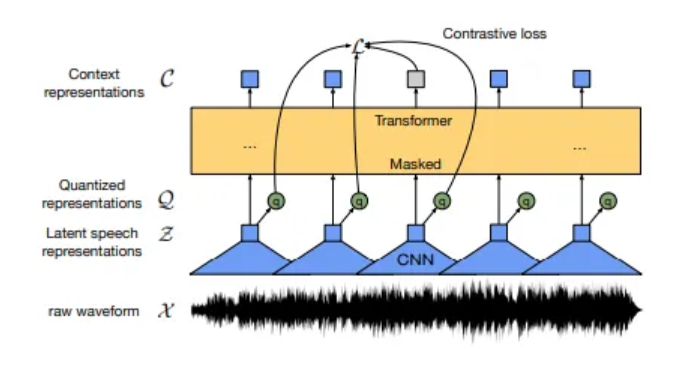
Raw Audio → CNN → Latent Speech Representation Feature (음성 데이터 압축하거나 추상화해서 음성의 중요한 정보 요약해서 표현하는 벡터 공간) → Masking → Transformer → Context Vector 뽑아냄 → Quantization → Contrastive Loss 학습
2. Model
- Feature Encoder (CNN)
- 입력 오디오를 받아서
- 시계열 특성 벡터 z1-zT 까지 출력하는데 이걸 latent representation 이라고 함
- Contextualized Representations (Transformer 구조)
- z1-zT 중 일부 마스킹
- 이후 Transformer 구조에 통과시켜서 문맥 벡터 생성 c1-cT
- Quantization Module
- z가 오디오 자체의 feature vector 인데 연속적인 벡터를 이산적으로 (discrete) 변환시키는 모듈
- Gumbel Softmax 사용 → 코드북 벡터 q 로 변환

결과는 각 코드북 그룹 g 안에서 특정 실제 코드북 벡터 v 선택 확률→ q 의 경우는 즉 가장 확률 높은 v 선택해서 만든 이산 코드북 벡터.
선택된 v 들을 concate 해서 선형변환 적용해서 feature vector q 만들어내는 방식
Codebook 이라는 개념
인풋 받은 음성 신호를 짧은 시간단위로 나눠서 음향 특징 (에너지 패턴, 주파수 성분 등) 을 표현한 벡터 조각임
3. Training
Feature Encoder 에서의 출력값 특성 벡터 (z1-zT) 일부를 마스킹함
각 마스킹된 시간 스텝에 대해 주어진 후보 중 정확한 정답 (latent audio representation) 을 구별해서 맞추는 방식
무작위로 마스킹 시작시점 고르고 → M개의 연속된 시간 스텝 마스킹 하는 방식
샘플링 중복 없이 하지만 마스킹 영역끼리 겹칠 수 있다고 함
정답 벡터는 Quantization Module 통과해서 나온 codebook vector q 임
총 Loss 는
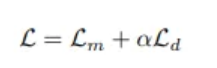
contrastive loss + diversity loss 느낌으로 해석 (a 는 하이퍼파라미터)
- Contrastive Loss

context vector ct (마스킹된 시간 스텝 t 의 context vector) 가 정답 벡터인 qt 와는 비슷하게, 정답이 아닌 나머지는 “틀리다” 로 인식시켜서 학습시키는 것임
- Diversity Loss

codebook 안의 모든 엔트리 골고루 사용하게 유도하는 loss.
특정 code 만 계속 사용하면 overfitting 될수도 있으니까 다양한 code 가 골고루 쓰이도록 강제하는 loss
→ 이 과정에서는 음성 인풋으로 정답 찾는 contrastive learning 하고, 학습된 소리 representation 으로 label 붙이는 fine-tuning 진행
Fine-Tuning
문자, 음소 예측(TIMIT 나 Libri-Speech 데이터를 이 단계에서 사용)
CTC Loss 사용하고, 이를 최소화 하는 방식으로 학습 (입력 시퀀스와 출력 시퀀스 길이 다를 때 align 없이 학습할수 있도록 해줌)
시간 정보가진 인풋과 - 문자 특징 가짓 아웃풋을 다루니까 시퀀스 길이가 다름 → CTC Loss 사용
4. Experimental Setup
4.1 Datasets
- Unlabeled 데이터로는 LibriSpeech corpus(LS-960, 약 960시간 분량)와 LibriVox(LV-60k) 데이터 (53.2k 시간 분량)을 사용 (오디오북 녹음)
- Labeled 데이터로는 총 5가지 설정을 사용
- 960시간 전체 (LibriSpeech)
- 100시간만 사용 (train-clean-100)
- 제한된 리소스 상황(train-10h, train-1h, train-10min) 설정
- train-10h: 10시간
- train-1h: 1시간
- train-10min: 10분
Labeled 데이터를 인위적으로 다르게 해서 적은 labeled 데이터에도 잘 작동하는지 확인
TIMIT 데이터셋(5시간 분량 정밀 음소 레이블된 오디오) 도 사용해서 phoneme recognition fine-tuning 적용
4.2 Pre-Training
마스킹 비율은 약 49%
Feature Encoder 구조
- CNN 인코더는 7개 블록(block)으로 구성됩니다.
- 각 블록은
- 채널 수: 512
- stride: (5,2,2,2,2,2,2)
- kernel width: (10,3,3,3,3,3,2)
- 최종 출력 feature는 약 20ms 간격으로 추출됨.
Transformer 구조
- BASE 모델:
- 12개 Transformer block
- dimension 768
- inner dimension (FFN) 3072
- 8개 attention heads
- LARGE 모델:
- 24개 Transformer block
- dimension 1024
- inner dimension 4096
- 16개 attention heads
학습 환경
- BASE: 64개 V100 GPU로 1.6일간 학습
- LARGE: 128개 V100 GPU로 2.3~5.2일간 학습
4.3 Fine-Tuning
Context Network 위에 랜덤 초기화된 선형 레이터 추가
- Libri-light (few label 데이터)에서는:
- learning rate 2e-5와 2e-5 두 가지를 비교
- best WER (word error rate) 모델을 선택
- 960h full label 데이터에서는:
- learning rate 1e-4 사용
4.4 Language Models & Decoding
- Language Model (LM) 두 종류를 사용합니다:
- 4-gram LM
- Transformer LM
- 4-gram LM은 N-gram 기반 간단한 모델입니다.
- Transformer LM 이 더 복잡
디코딩 (Decoding) 방식
- beam search 사용:
- 4-gram LM: beam size 50
- Transformer LM: beam size 500
- best WER (Word Error Rate)를 내는 모델을 선택
→ LM 쓰는 이유 : Fine-Tuning 후 소리로만 봐서 애매한 부분을 Language Model 문맥으로 보완하기 위해 Language Model 필요
5. Results
라벨이 매우 적은 상황에서 pre-trained 모델 평가함 → Unlabled 데이터로 학습된 representation (feature vector) 이 적은 리소스 상황에서도 잘 작동하나 확인
즉, 극소량 labeled data 에서도 엄청 효과적
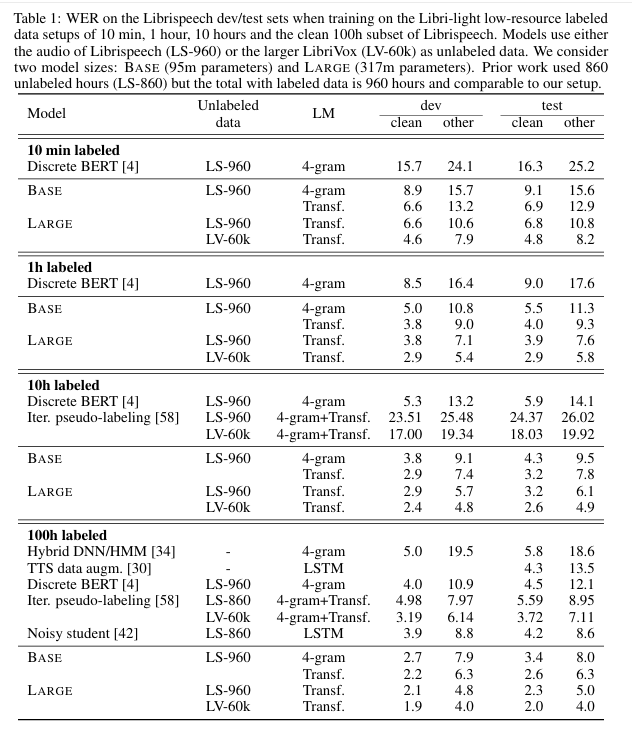
매우 적은 labeled data (10분) 만으로도 노이즈 섞인 데이터 8.2% 까지 낮은 WER 달성
Unlabeled → Fine-Tuning 만으로도 좋은 성능 나온다
이번에는 labled data 가 많은 경우 실험 (960시간)
Self-Supervised Pre-training 은 labeled 많을때도 성능 좋음
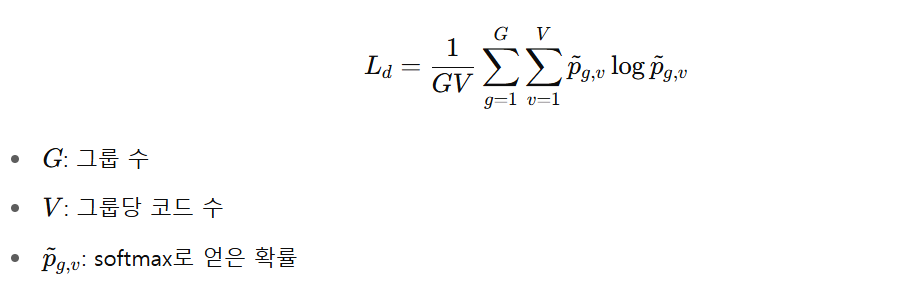
Phoneme Recognition(음소 인식) 을 TIMIT 데이터셋에 적용했을때
이때 labeled phoneme 데이터만 사용
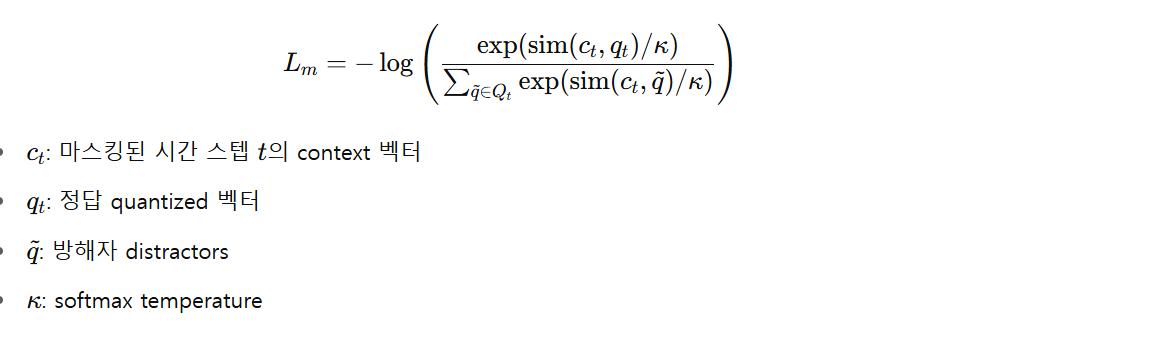
PER 기존 wav2vec 1.0 보다 훨씬 좋은 성능 (Phoneme Error Rate)
어떤 설계가 성능에 가장 큰 영향을 미쳤는지
입력을 quantization 하지 말고 연속 유지해야 WER 낮음
continuous input + quantized targets 구조가 가장 WER 낮았음
6. Conclusion
단 10분의 labeled data 썼는데도 WER 4.8/8.2 (clean, other) 달성 → 오류율 매우 낮음
noisy speech 로 SOTA 달성
100 hr Librispeech setup 에서 100배 적은 labeled data 로 최고 성능 달성
