JPA를 사용하는 누구나 한 번쯤은 들어봤을 N+1 문제 를 프로젝트 진행 과정에서 파악했던 방법을 작성합니다.
Spring에서 제공해주는 StopWatch를 사용해서 시간 측정도 진행해봤습니다.
1. Fetch 전략이 EAGER인 경우

다음은 주문에서 @OneToMany로 연관관계 Mapping을 한 코드입니다. 코드에서 알 수 있듯이 fetch 전략을 EAGER로 하였을 경우 주문 정보를 가져올 때 주문 도서에 대한 정보 또한 모두 조회를 하는 문제점이 존재합니다.
SaleRepository.class - 회원 주문 정보 조회 메서드 일부
List<Sale> fetch = from(sale)
.leftJoin(sale.member)
.where(sale.member.id.eq(memberId))
.orderBy(sale.saleId.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
List<SaleInfoResponseDto> responseDto = fetch.stream()
.map(f -> new SaleInfoResponseDto(
f.getSaleTitle(),
f.getSaleNumber(),
f.getMember().getEmail(),
f.getSaleOrdererName(),
f.getSaleOrdererContact(),
f.getSaleTotalPrice(),
f.getSaleDate()))
.collect(Collectors.toList());해당 메서드를 통해 DB에 접근하여 데이터를 가져와봅시다.
Pageable을 사용하여 10개의 주문 정보만 가져오도록 진행하였습니다.
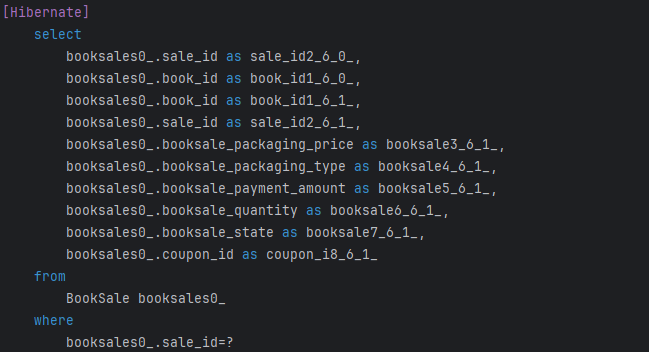
Hibernate의 출력 결과 중 의도였던 주문 정보와 회원 정보만 가져오는 쿼리문이 아닌 주문 도서에 대한 조회를 진행하게 됩니다. 쿼리 문을 세어보니 13개의 쿼리문이 나와요. 따라서 N+1 문제가 발생한 것입니다. 이로 인해 DB에 접근해 값을 가져오는데 걸리는 시간 또한 200ms 정도였습니다.
이러한 문제점을 해결하기 위해 LAZY 전략을 사용해봅시다.
2. LAZY 전략
다음과 같이 LAZY로 변경해봅시다.
확실히 쿼리문이 줄어 총 3개의 쿼리문이 나오게 되었습니다. 시간 또한 50ms 이내로 빨라진 걸 확인할 수 있었고 더이상 주문 도서에 대한 쿼리가 사라져 N+1의 문제는 없지만, 의심이 되는 것이 있습니다.
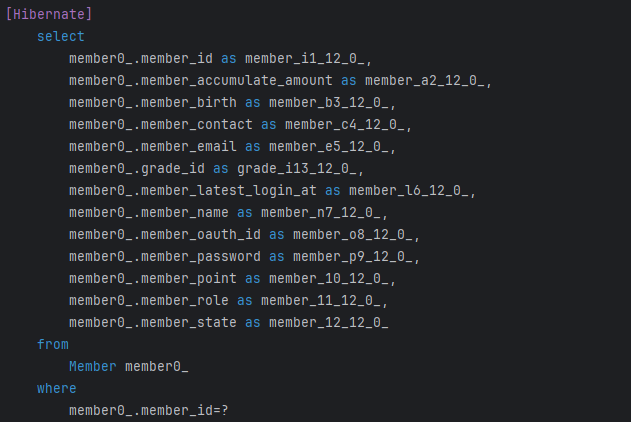
주문 → 회원 정보를 가져올 때 굳이 Query문을 한 번 더 날려야 되는지, 만약 member 연관 관계에 EAGER 전략을 사용하는 것이 있다면 또 다시 N+1 문제가 발생할 것이라고 생각합니다.
이러한 문제점을 없애기 위해 Querydsl을 사용하는 환경이므로 Fetch Join 을 사용해봅시다.
...
List<Sale> fetch = from(sale)
.leftJoin(sale.member).fetchJoin()
.where(sale.member.id.eq(memberId))
.orderBy(sale.saleId.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
...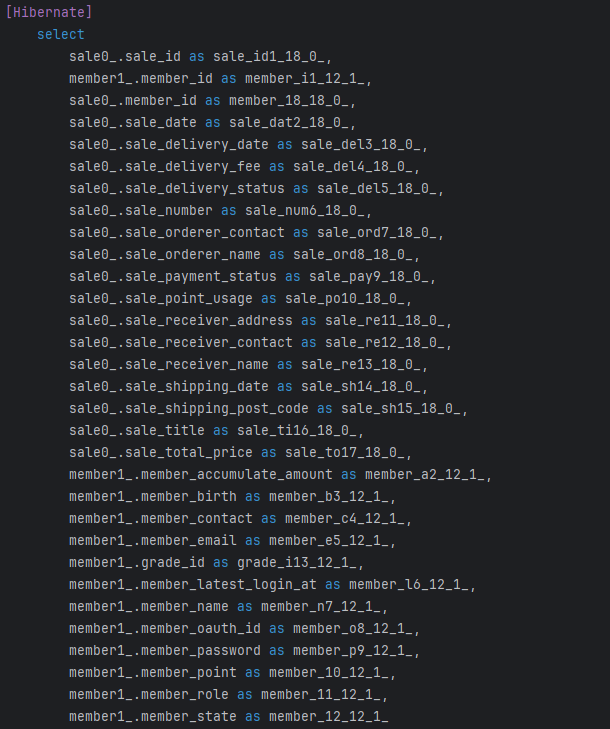
예상과 같이 총 쿼리문 2개로 모든 데이터를 가져오게 될 수 있게 되었습니다 !
하지만, member 엔티티에서 정작 필요한 정보는 Email 정보 한 개인데 모든 데이터를 가져올 수 있을까? 라는 생각이 들기 시작했습니다.
이러한 문제를 해결하기 위해서 DTO 객체 형식으로 가져오는 방법을 사용하였습니다.
3. DTO 객체로 가져오기
List<SaleInfoResponseDto> responseDto = from(sale)
.where(sale.member.id.eq(memberId))
.select(Projections.constructor(SaleInfoResponseDto.class,
sale.saleTitle,
sale.saleNumber,
sale.member.email,
sale.saleOrdererName,
sale.saleOrdererContact,
sale.saleTotalPrice,
sale.saleDate))
.orderBy(sale.saleId.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();Projections.constructor를 통해 응답하고자 하는 DTO 객체의 생성자로 주입하는 방식으로 변경하였습니다. 이러한 경우 DB에 쿼리문을 날릴 때 필요한 정보만 가져온다는 장점 또한 존재합니다.
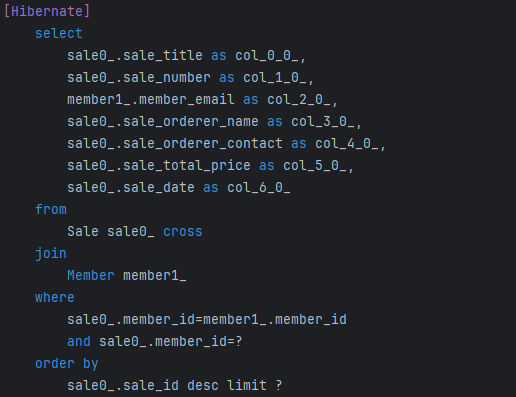
원했던 결과물이 드디어 완성되었습니다!
쿼리문 2개 (조회, 페이징 처리), 걸린 시간 20ms 이내
DTO로 변환을 하기 때문에 영속성 컨텍스트의 등록되거나 관리의 대상이 아니기 때문에 조금 더 안전한 코드라고 생각합니다.
결과
총 정리를 해보자면, 13개의 쿼리문에서 2개의 쿼리문으로 줄였으며, 200ms → 20ms로 1/10 정도 시간을 감소하게 된 것입니다. 이로 인해 DB에 부하를 줄이고, 응답 시간을 줄이는 경험을 하였습니다.
초기에는 주문을 조회할 때 어짜피 주문한 도서의 정보, 주문한 회원의 정보가 필요하니 EAGER를 사용해도 괜찮지 않을까? 라고 생각했었지만, 예상과는 다른 조회 결과를 발견하고 해결 방안들을 찾아봤던 좋은 경험을 한 것 같습니다.
물론 위에서 설명했던 Querydsl에 fetch join은 pagination 쿼리에 사용하면 모든 레코드를 가져오기 때문에 절대 사용하면 안돼요!!
JPA는 직접 쿼리를 작성하는 것이 아니기 때문에 로그를 자주 확인해줘야 한다는 말이 이러한 문제점 때문인 것 같아요. 코드를 작성할 때 잘 동작하는 것도 중요하지만, 이러한 과정을 통해 테스트하는 습관도 가져봅시다 👏🏻

좋은 글 잘 읽고 갑니다~