
1. 학습 일정
1) 강의 수강
2) 과제
3) 피어 세션
2. 학습 내용
NLP
3강: Recurrent Neural Network and Language Modeling
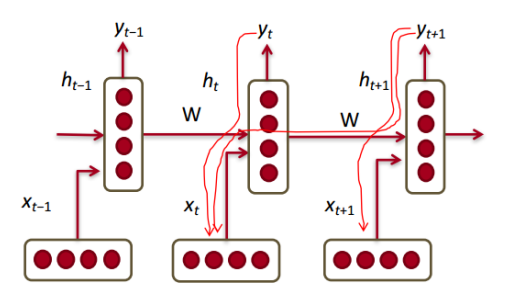
RNN 기본 구조
- Unrolled version
- rolled version
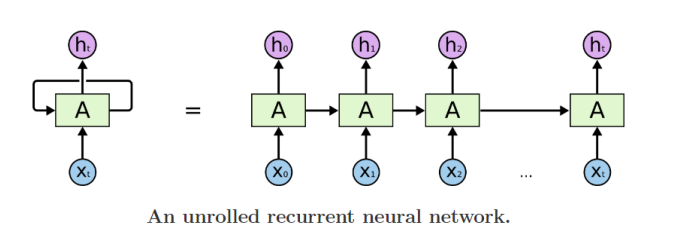
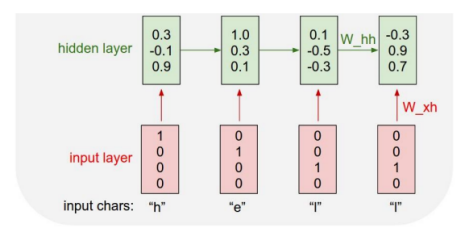
RNN의 hidden state를 계산하는 방법
- : 지난 hidden state 벡터
- : t일 때 input 벡터
- : 새로운 hidden state 벡터
- : 로 이루어진 RNN 함수
- : t일 때 output 벡터
중요한 점은 매번 같은 함수와 같은 파라미터 셋이 사용된다는 점이다.
->
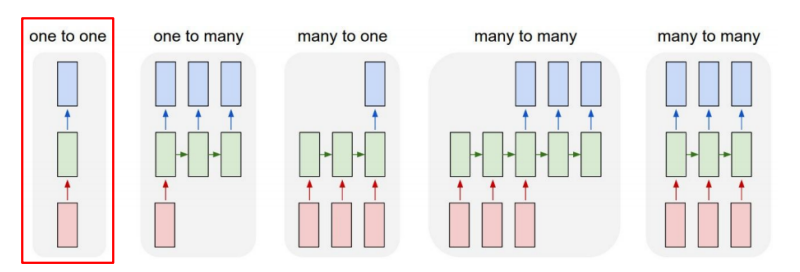
Types of RNNs
- One-to-one: Standard Neural Networks
- One-to-many: Image Captioning
- Many-to-one: Sentiment Classification
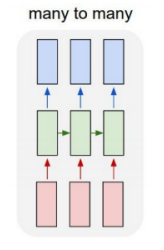
- Many-to-many (Sequence-to-sequence): Machine Translation
- Many-to-many (Sequence-to-sequence): Video classification on frame level (해당 씬이 전쟁인지? 예측)
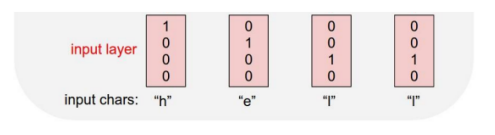
Character-level Language Model
Example of training sequence "hello"
- Vocabulary: [h, e, l, o]
- At test-time, sample characters one at a time, feed back to model
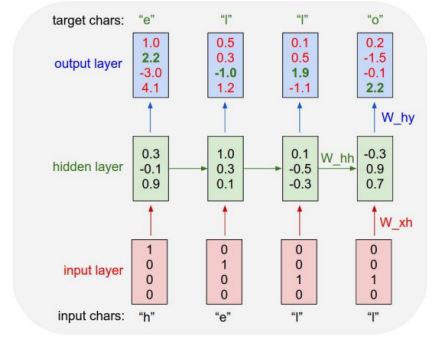
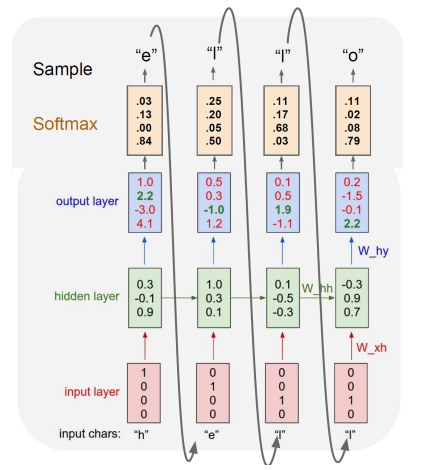
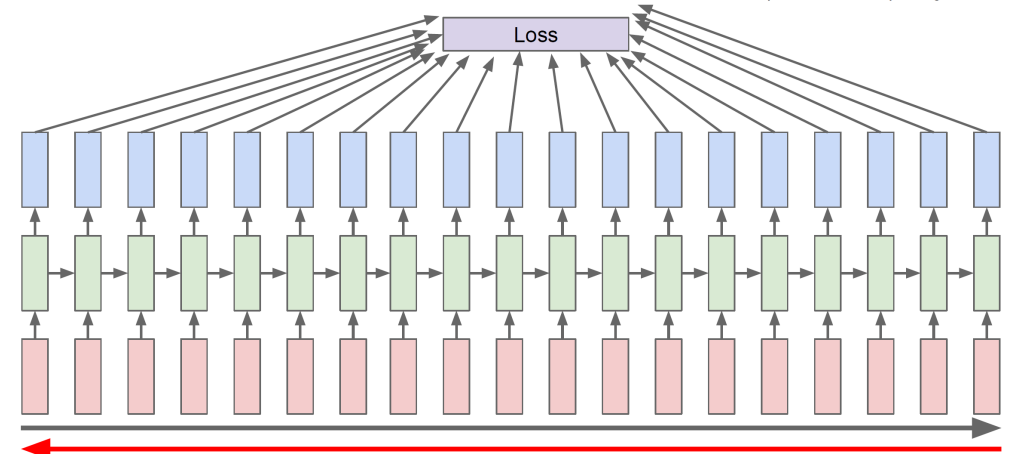
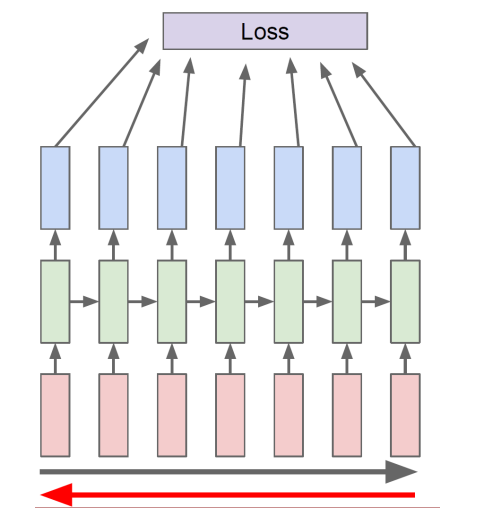
Backpropagation through time (BPTT)
- loss 계산을 위해 Forward
- gradient 계산을 위해 backward
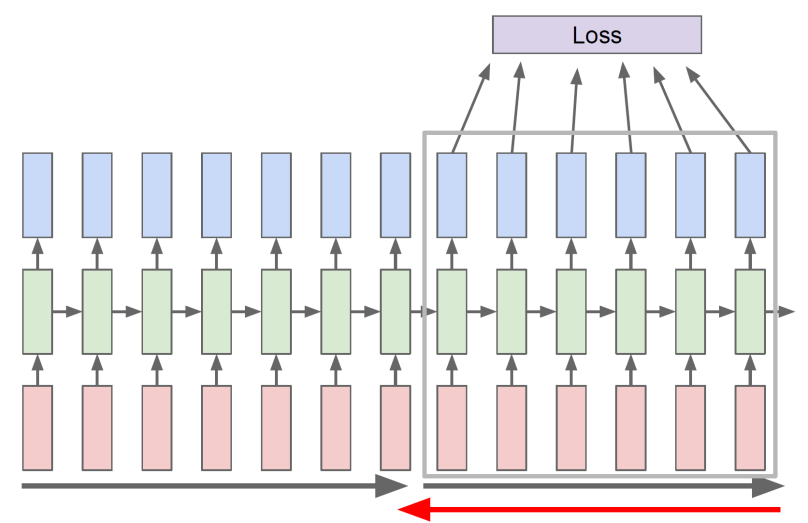
- 전체를 진행하기 보다 chunk로 나누어서 진행한다.
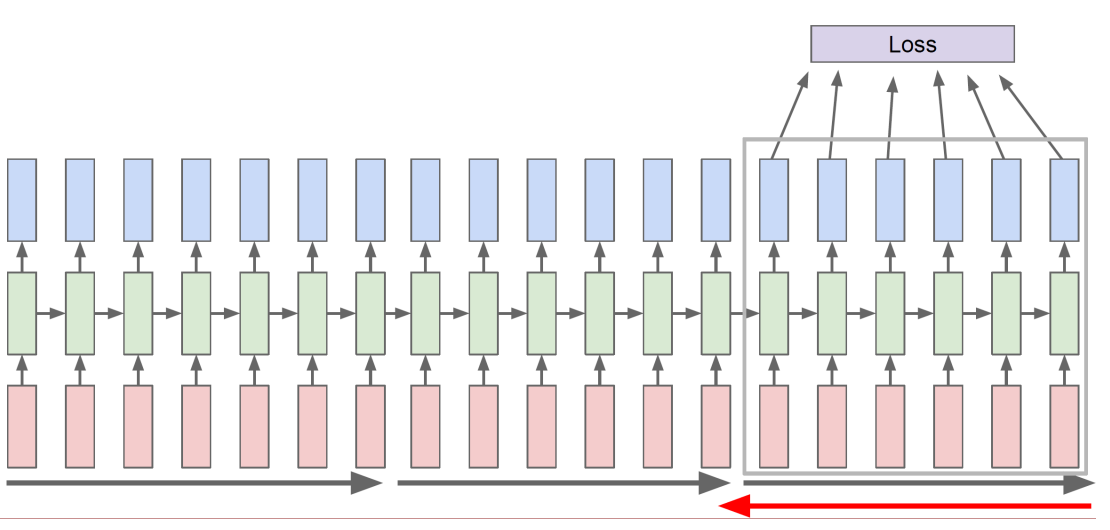
- forward를 계속 진행하되, 일부분만 backpropagation할 수 있다.
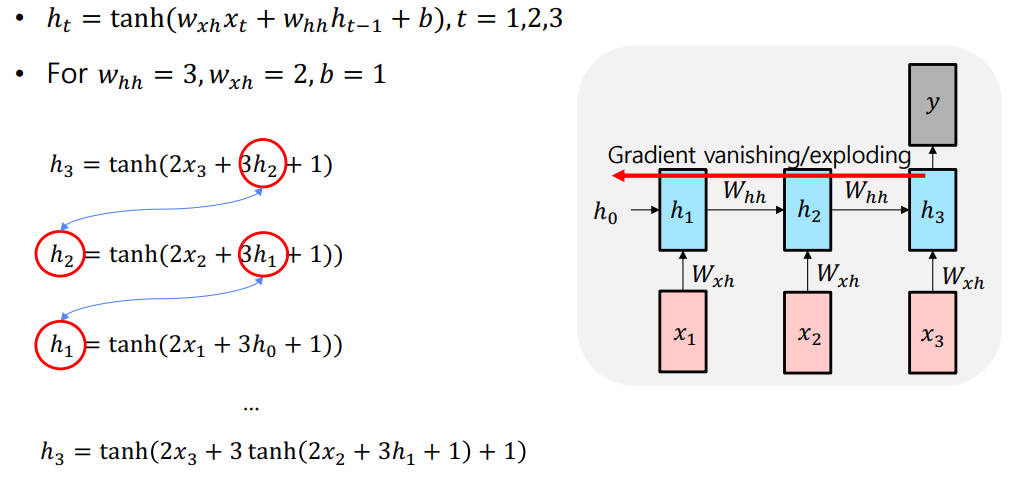
Vanishing/Exploding Gradient Problem in RNN
- RNN에서는 역전파가 진행되는 동안 계속 같은 행렬이 곱해진다. 따라서 gradient vanishing 혹은 exploding 문제가 생긴다.
- 다음은 그에 대한 간단한 예시이다.
4강: LSTM and GRU
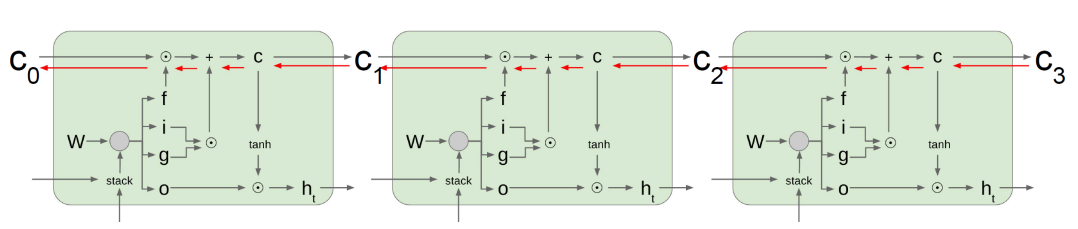
Long Short-Term Memory (LSTM)
- long term dependency와 vanishing / exploding 등을 해결하기위해 등장함.
- 중요 아이디어: cell state 정보를 변형없이 건네주는 것!
- long-term dependency를 해결하기 위해
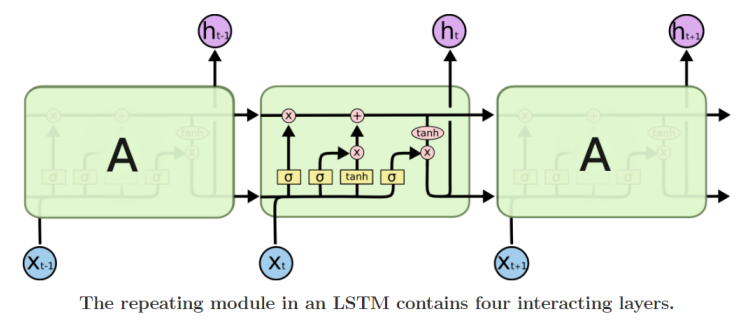
- long-term dependency를 해결하기 위해
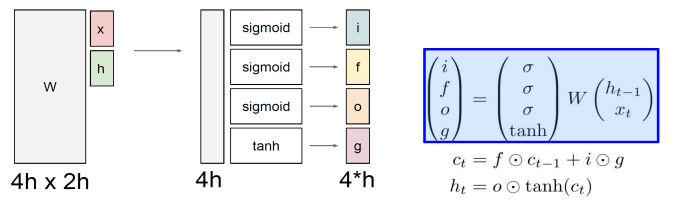
구조
- i: input gate, Whether to write to cell
- f: Forget gate, Whether to erase cell
- o: Output gate, How much to reveal cell
- g: Gate gate, How much to write to cell
Gated Recurrent Unit (GRU)
- What is GRU?
- c.f) in LSTM
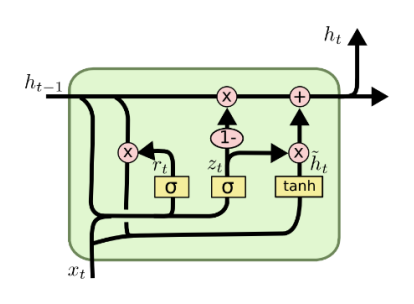
특징
1.
2. 2개 게이트 1개 게이트 (계산, 메모리 )
LSTM/GRU의 Backpropagation
- 정보가 더해지는 방식으로 explode/vanish가 사라져서 long term dependency도 해결
3. 피어 세션 정리
- 특이사항 없음
4. 과제 수행 과정
- 필수 과제 해결
- 시간날 때 코드 뜯어보는 게 좋아보임
5. 회고
- 좋지도 나쁘지도 않았던 하루.
- 슬슬 코테 준비해야할 듯 한데.. 내일부터는 해야겠다.
6. 내일 할일
- 강의 수강
- 시각화 강의 수강
- 코테 준비

AI가 세상을 바꾼다. 열심히 AI를 배워서 선한 영향력을 펼치는 개발자가 되고싶다. 인생은 Gradient Descent와 같지.