AI Tech Day 27 (Seq2seq with Attention, Beam Search and BLEU Score)
AI Tech Week 6 - NLP 이론 1
목록 보기
3/5

1. 학습 일정
1) 강의 수강
2) 피어 세션
3) 코딩 테스트 준비
2. 학습 정리
NLP
5강: Sequnce to sequence with attention
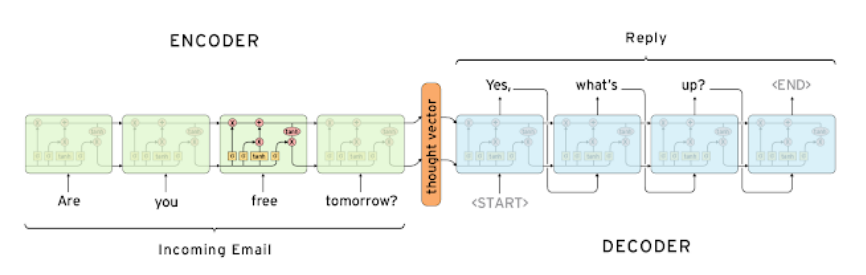
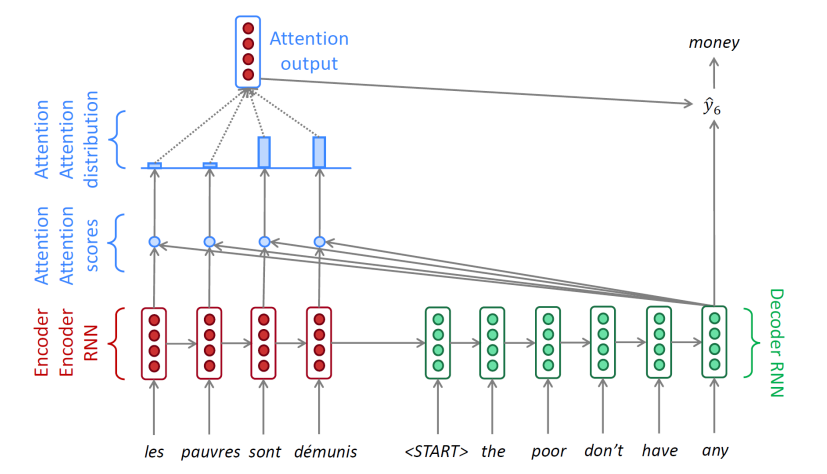
Seq2Seq Model
- input과 output 모두 단어들의 sequence이다.
- 인코더와 디코더로 구성된다.
Seq2Seq Model with Attention
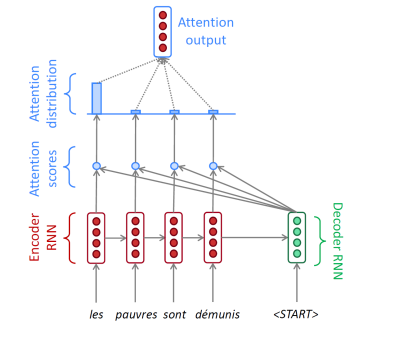
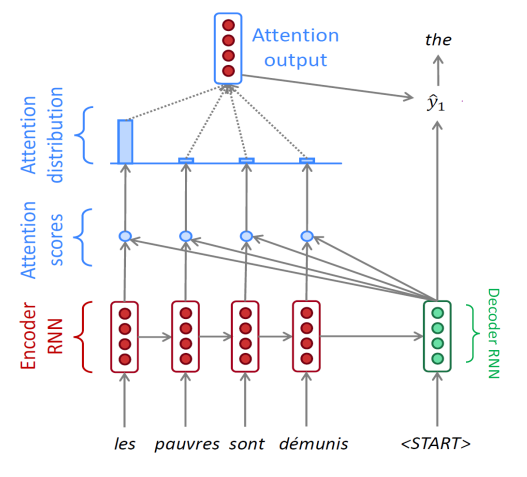
- Attention은 bottleneck problem의 해결책이다.
- decoder의 step마다 source sequence의 특정 부분에 집중한다.
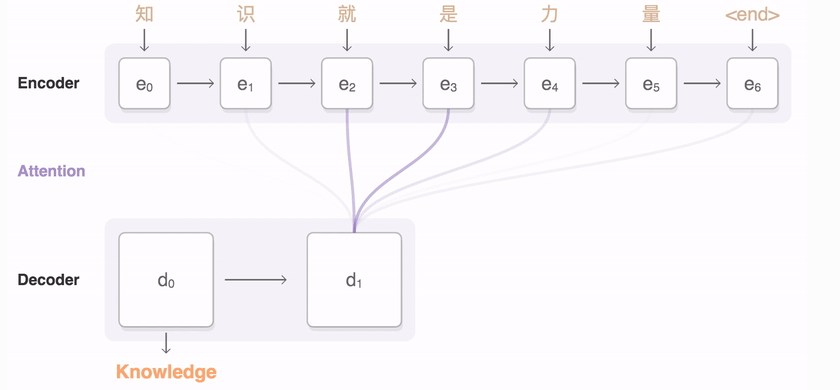
- 인코더 hidden state들의 weightted sum을 구하기 위해 attention이 사용된다.
- attention output과 decoder hidden state를 concatenate하면 을 계산할 수 있다.
- 다음 단어들에 대해 계속 진행하면 위와 같이 전개된다.
티쳐 포싱(Teacher Forcing)
티쳐 포싱은 Seq2seq (Encoder-Decoder)을 기반으로 한 모델들에서 많이 사용되는 기법이다.
target word(Ground Truth)를 디코더의 다음 입력으로 넣어주는 기법이다.
- 배경: 만약 t-1에서 잘못된 예측이 이루어졌다면, t부터는 잘못된 예측으로 이어진다!
따라서 입력으로 Ground Truth를 넣어준다.- 장점: 학습이 빠르다.
- 단점: 추론 과정에서는 Ground Truth를 제공할 수 없다. 따라서 학습과 추론 단계에서의 차이 (discrepancy)가 존재한다.
- 초반에는 Teacher Forcing하다가 점차 줄이는 방법도 있음.
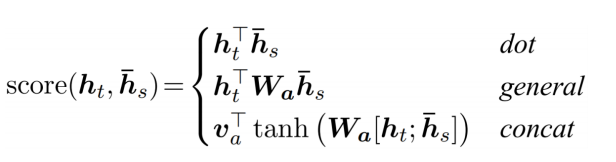
- 위와 같이 유사도를 구하는 다양한 방식이 있다. general과 concat의 경우 를 넣어주어 유사도 또한 학습 가능하게 만든다.
Attention의 장점들
1. Attention은 NMT performance를 크게 개선시켰다.
-> decoder가 특정 부분에 집중할수 있도록 한 것이 유용했다.
2. bottleneck problem 해결
-> decoder가 source를 직접적으로 볼 수 있도록 함.
3. vanishing gradient problem 해결
-> 지름길 제공
4. Attention은 해석 가능성을 제공한다.
-> attention distribution을 분석하면 어떤 단어에 집중했는지 알 수 있다.
6강: Beam Search and BLEU score
Greedy decoding

- 뒤로 돌아갈 수 없는 문제점이 있다.
Exhaustive search
-
-
모든 경우의 수를 계산하는 방법.
-
시간복잡도가 로 너무 크다!
Beam search
- greedy와 exhausitive의 절충안
- Core idea: 매 time step마다 가장 유망한 k개의 partial translation을 추적한다.
- k는 beam size로 보통 5 to 10
- log를 통해 덧셈으로 변환
- score는 모두 음수이고 높을수록 좋은 score이다.
- beam search는 global optimal solution을 보장하지는 않지만 exhaustive search보다는 더욱 효율적으로 계산한다.
Beam search: Example
- Beam size: k = 2
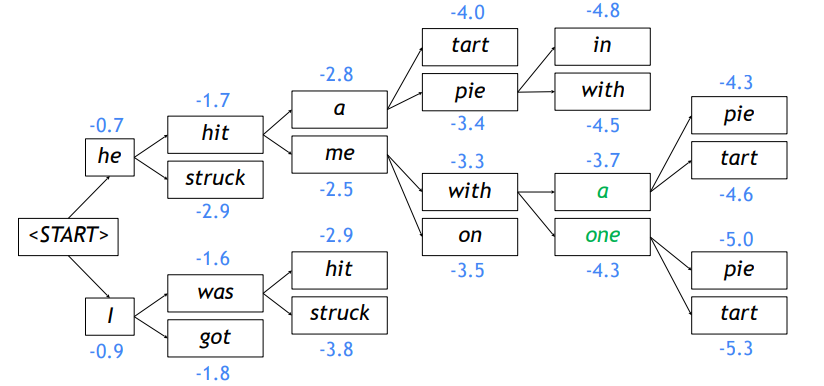
Beam search: Stopping criterion
- greedy decoding의 경우 < END > token까지 decode하게 된다.
- For example: < START > he hit me with a pie < END >
- beam search decoding의 경우 각기 다른 가설들이 다른 timestep에 < END >를 생산한다.
- < END >가 나온 경우, 해당 가설은 complete된 것임.
- beam search를 진행하면서 다른 가설 탐색을 계속한다.
- beam search 멈추는 기준
- timestep 에 도달 시
- 사전에 정의된 cutoff를 통해 적어도 n개의 가설이 완성되는 경우
Beam search: Finishing up
- 각각 가설에 대하여 다음과 같이 score를 매길 수 있음.
- 하지만 가설이 길어질 수록 score가 낮게 되는 문제가 발생
- 따라서 다음과 같이 정규화를 해준다.
BLEU score
단순히 Precision과 Recall을 사용하는 경우
- 순서를 고려하지 못하는 문제가 발생!
-> 따라서 BLEU score가 등장!
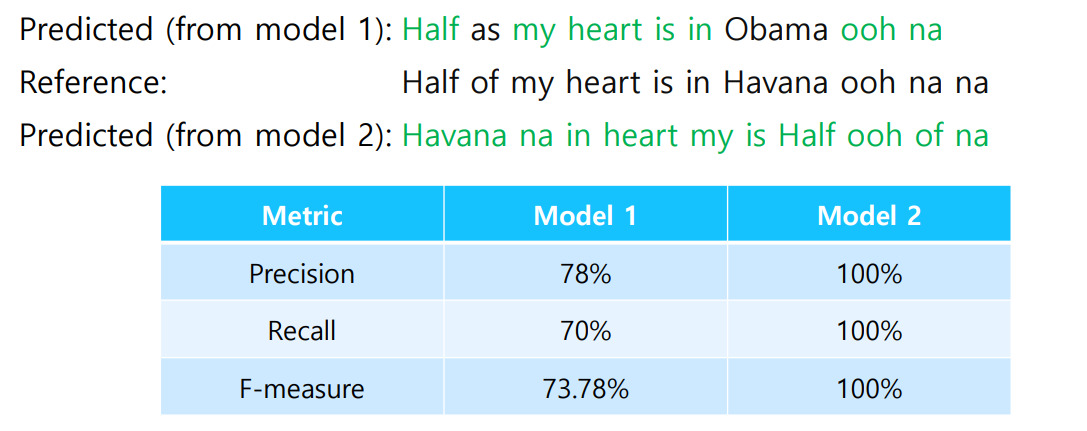
BiLingual Evaluation Understudy (BLEU)
- N개의 연속된 단어가 ground truth와 얼마나 겹치는가?
- n이 4라면 1~4까지 n-grams에 대한 precision을 계산한다.
- brevity penalty를 추가한다. (길이가 너무 짧은 경우 고려)
- 단일 문장이 아닌, 전체의 corpus에 대해 계산된다.
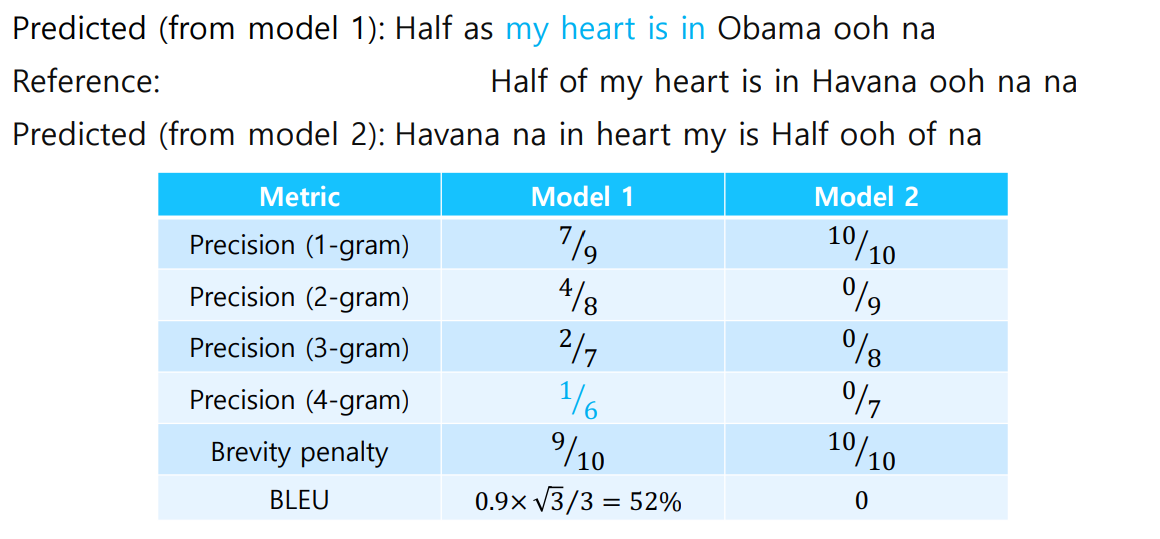
- 다음은 BLUE를 적용한 예시이다.
3. 피어 세션 정리
- 추천 시스템관련 얘기
- 강의 관련 토의 (zero_grad, optimizer)
4. 과제 수행 과정
- 무난하게 완료
- 자연어 전처리 혹은 모델이 적용되는 과정은 나중에 다시 봐야겠다.
5. 회고
- 코딩 테스트 재활 훈련 시작했는데,,, 감을 빨리 찾자.
6. 내일 할일
- 복습
- 코딩 테스트 준비

AI가 세상을 바꾼다. 열심히 AI를 배워서 선한 영향력을 펼치는 개발자가 되고싶다. 인생은 Gradient Descent와 같지.