
1. 오늘 일정
1) 스탠드업 미팅
2) 강의 수강
3) 피어세션 & 멘토링
2. 학습 정리
MRC
1강: MRC Intro & Python Basics
1. Introduction to MRC
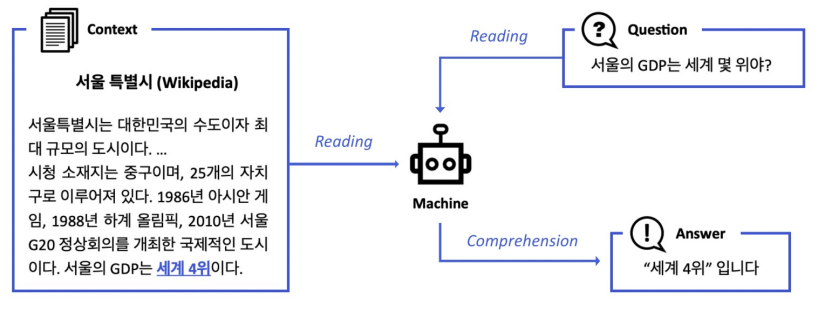
MRC의 개념
기계 독해 (Machine Reading Comprehension)
: 주어진 지문(Context)를 이해하고, 주어진 질의 (Query/Question)의 답변을 추론하는 문제
MRC의 종류
1) Extractive Answer Datasets: 질의에 대한 답이 항상 주어진 지문에 존재
2) Descriptive/Narrative Answer Datasets: 답이 지문 내에서 추출한 span이 아니라, 질의를 보고 생성 된 sentence의 형태
3) Multiple-choice Datasets: 질의에 대한 답을 여러 개의 answer candidates 중 하나로 고르는 형태



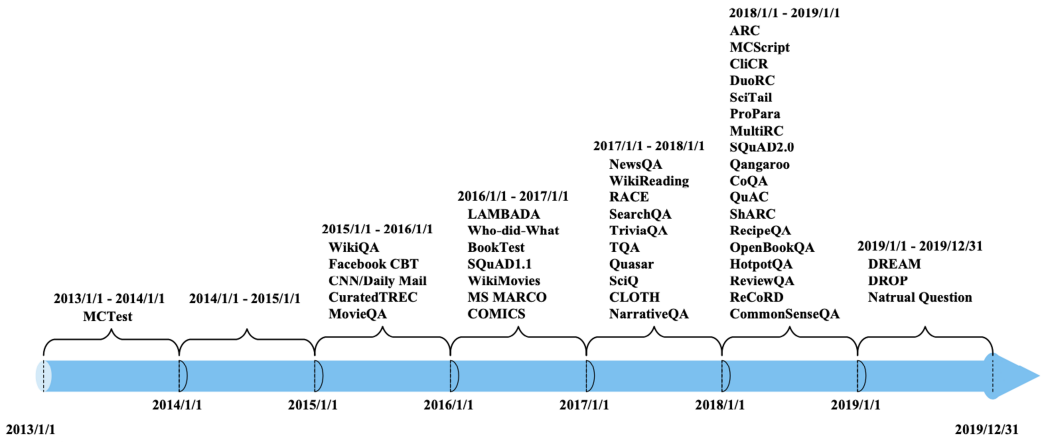
MRC Datasets
Challenges in MRC
Paraphrasing: 단어들의 구성이 유사하지는 않지만 동일한 의미의 문장을 이해
Unanswerable questions: 주어진 지문에서는 질문에 대한 답을 찾을 수 없는 경우
Multi-hopreasoning: 여러 개의 document에서 질의에 대한 supportingfact를 찾아야지만 답을 찾을 수 있는 경우
MRC 평가방법
EM/F1

ROUGE-L/BLUE
2. Unicode & Tokenization
Unicode란
전 세계의 모든 문자를 일관되게 표현하고 다룰 수 있도록 만들어진 문자셋
각 문자마다 숫자 하나에 매핑한다.
토크나이징
텍스트를 토큰 단위로 나누는 것
단어(띄어쓰기 기준),형태소,subword등 여러 토큰 기준이 사용된다.
2강: Extraction-based MRC
1. Extraction-based MRC
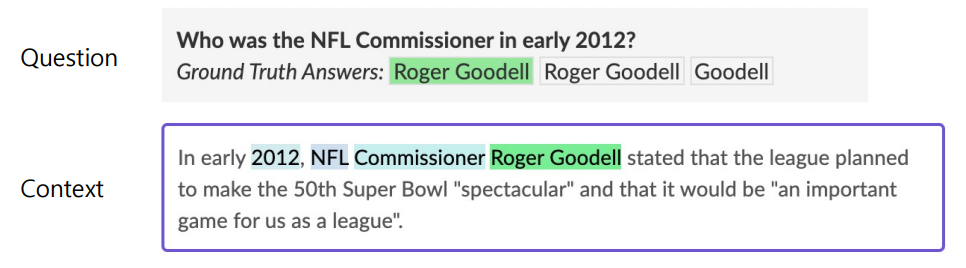
Extraction-based MRC 문제 정의
질문(question)의 답변(answer)이 항상 주어진 지문(context)내에 span으로 존재
e.g.SQuAD,KorQuAD,NewsQA,NaturalQuestions,etc
2. Pre-processing
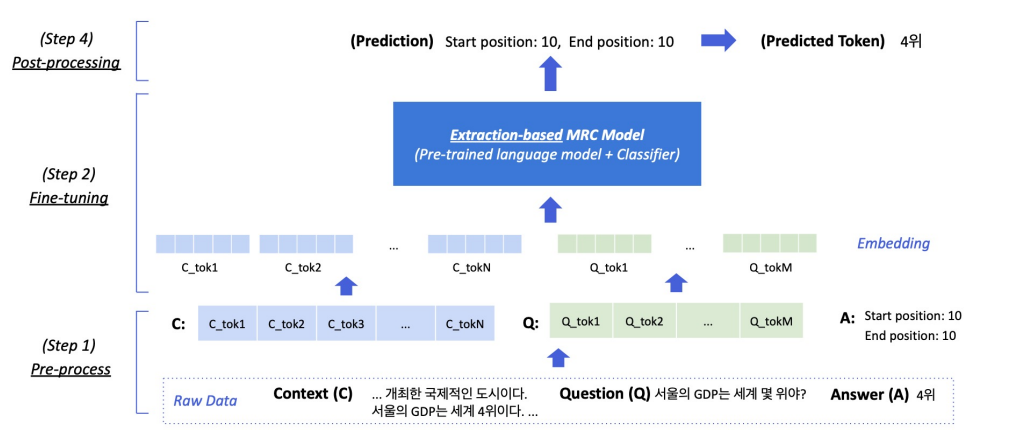
Tokenization, Special Tokens, Attention Mask, Token Type IDs, 모델 출력값
3. Fine-tuning
Extraction-based MRC Overview
4. Post-processing
불가능한 답 제거하기
다음과 같은 경우 candidatelist에서 제거
• Endposition이 startposition보다 앞에 있는 경우 (e.g.start=90,end=80)
• 예측한 위치가 context를 벗어난 경우 (e.g.question위치쪽에 답이 나온 경우)
• 미리 설정한 max_answer_length 보다 길이가 더 긴 경우
최적의 답안 찾기
1. Start/endpositionprediction에서 score(logits)가 가장 높은 N개를 각각 찾는다.
2. 불가능한 start/end조합을 제거한다.
3. 가능한 조합들을 score의 합이 큰 순서대로 정렬한다.
4. Score가 가장 큰 조합을 최종 예측으로 선정한다.
5. Top-k가 필요한 경우 차례대로 내보낸다
3. 피어 세션 정리
- 일일 목표 작성하기
- 베이스라인 코드 리뷰 (목, 금)
- 이번 대회부터는 강의 리뷰!!
4. 내일 할일
- 최소 3강은 수강
- 스페셜 미션 & 실습
- EDA
