
1. 오늘 일정
1) 강의 수강
2) 스탠드업 미팅
3) EDA
4) 베이스라인 코드 살펴보기
5) 스페셜 미션
2. 학습 정리
MRC
3강: Generation-based MRC
Generation-based MRC Overview
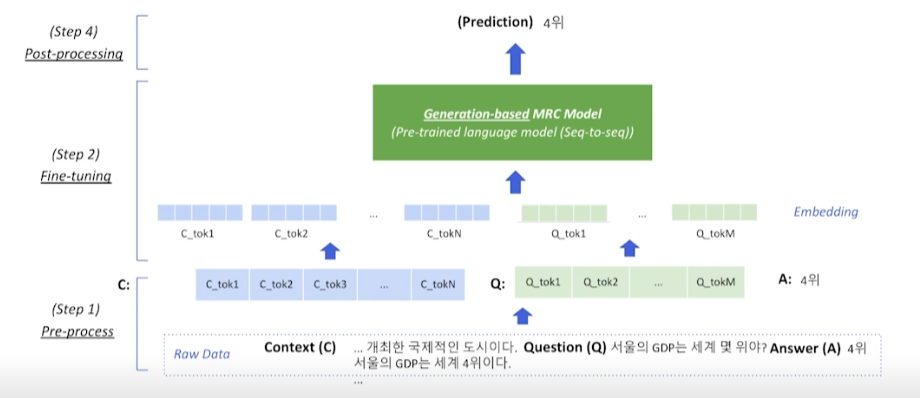
Generation-based MRC & Extraction-based MRC 비교
1) MRC 모델 구조
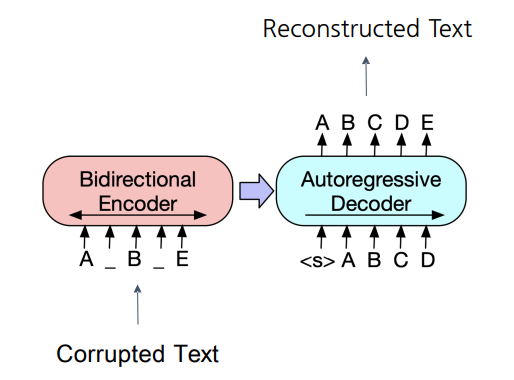
Generation : Seq-to-seq PLM 구조
Extraction : PLM + Classifier 구조
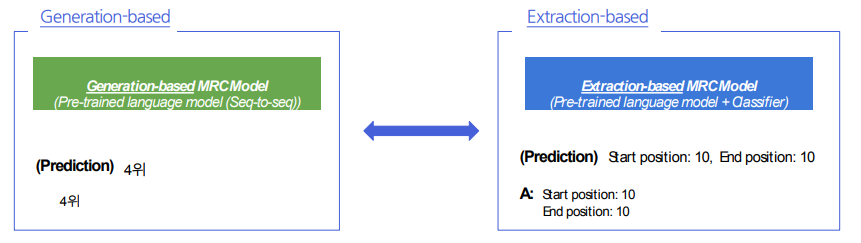
Pre-processing
Extraction에서는 CLS, SEP, PAD 토큰을 사용
Generation에서도 PAD 토큰은 사용. CLS, SEP 토큰 또한 사용할 수 있으나, 대신 자연어를 이용하여 정해진 텍스트 포맷으로 데이터를 생성
입력 표현 - additional information
Attention mask
- Extraction-based MRC와 똑같이 어텐션 연산을 수행할 지 결정하는 어텐션 마스크 존재
Token type ids
- BERT와 달리 BART에서는 입력시퀀스에 대한 구분이 없어 token_type_ids가 존재하지 않음
- 따라서 Extraction-based MRC와 달리 입력에 token_type_ids가 들어가지 않음
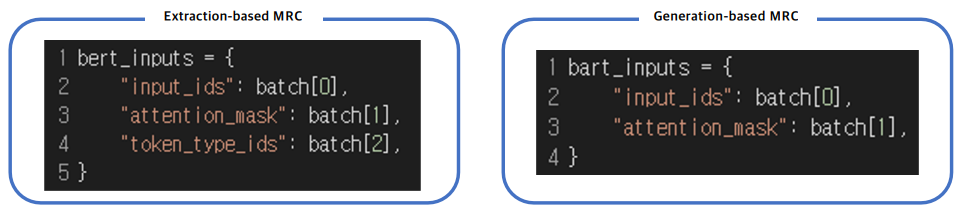
출력 표현 - 정답 출력
- Extraction-based MRC에선 시작/끝 토큰의 위치를 출력하는 것이 모델의 최종 목표
- Generation-based MRC느 ㄴ그보다 조금 더 어려운 실제 텍스트를 생성하는 과제를 수행
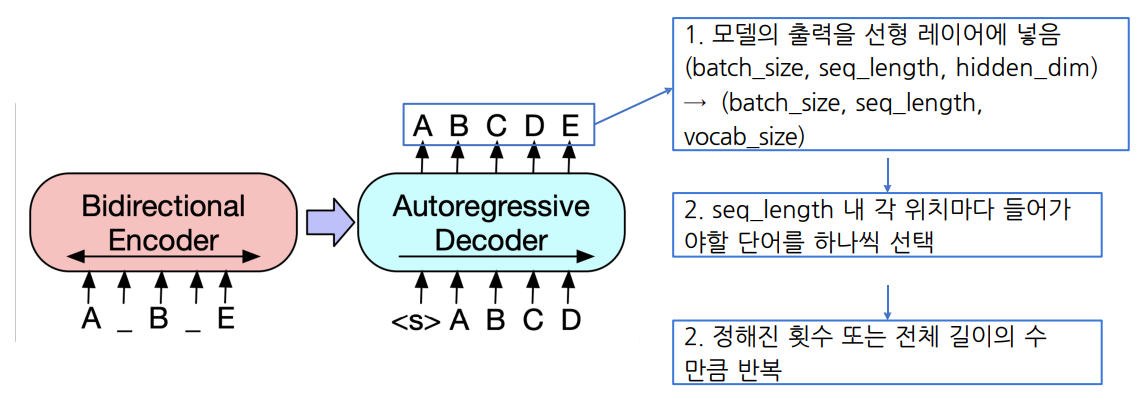
Model
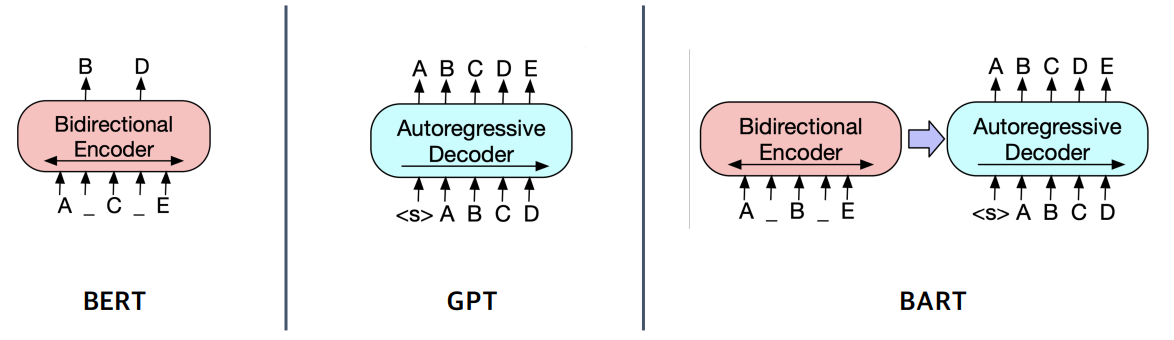
BART
기계 독해, 기계 번역, 요약, 대화 등 sequence to sequence 문제의 pre-training을 위한 denoising autoencoder
- BART의 인코더는 BERT처럼 bi-directional
- BART의 디코더는 GPT처런 uni-directional(autoregressive)
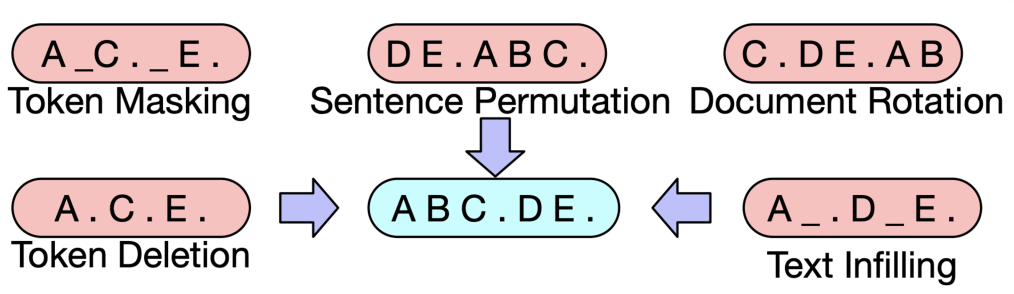
BART는 텍스트에 노이즈를 주고 원래 텍스트를 복구하는 문제를 푸는 것으로 pre-training함
Post-processing
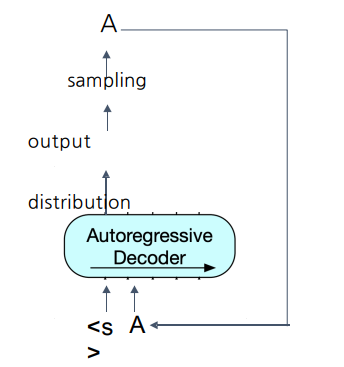
Decoding
디코더에서 이전 스텝에서 나온 출력이 다음 스텝의 입력으로 들어감 (autoregressive)
맨 처음 입력은 문장 시작을 뜻하는 스페셜 토큰
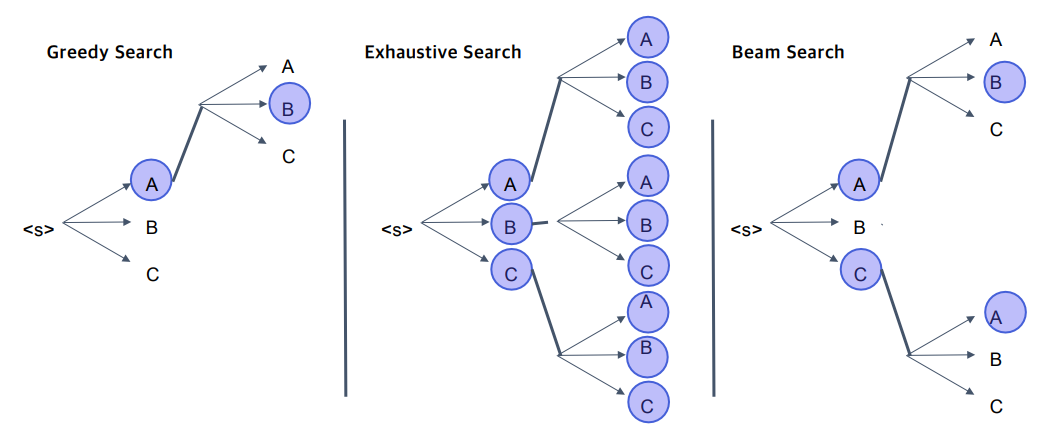
Searching
4강: Passage Retreval - Sparse Embedding
Introduction to Passage Retrieval
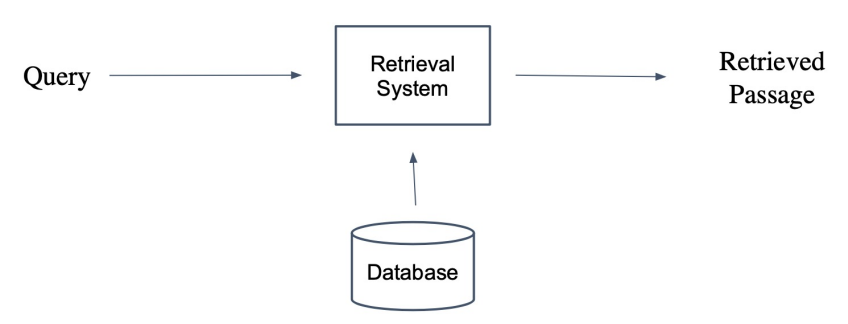
Passage Retrieval
질문(query)에 맞는 문서(passage)를 찾는 것.
Passage Retrieval with MRC
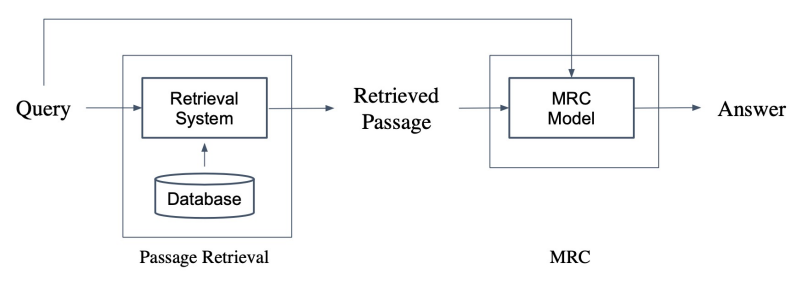
Open-domain Question Answering: 대규모의 문서 중에서 질문에 대한 답을 찾기
- Passage Retrieval과 MRC를 이어서 2-Stage로 만들 수 있음.
Overview of Passage Retrieval
Query와 Passage를 임베딩한 뒤 유사도로 랭킹을 매기고, 유사도가 가장 높은 Passage를 선택함
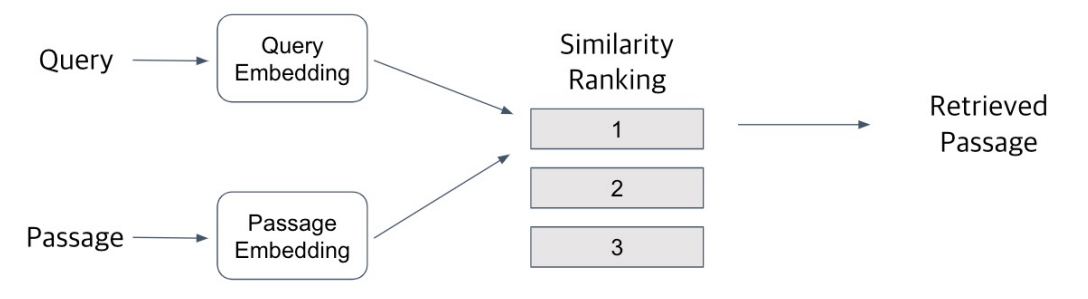
Passage Embedding and Sparse Embedding
Passage Embedding Space
- Passage Embedding의 벡터 공간
- 벡터화된 Passage를 이용하여 Passage간 유사도 등을 알고리즘으로 계산할 수 있음.
Sparse Embedding 소개
1. BoW를 구성하는 방법 -> n-gram
- unigram (1-gram): It was the best of times => It, was, the, best, of, time
- bigram (2-gram): IT was the best of times => It was, was the, the best, best of, of times
- Term value를 결정하는 방법
- Term이 document에 등장하는지 (binary)
- Term이 몇번 등장하는지 (term frequency), 등. (e.g. TF-IDF)

Sparse Embedding 특징
1. Dimension of embedding vector = number of terms
- 등장하는 단어가 많아질수록 증가
- N-gram의 n이 커질수록 증가
- Term overlap을 정확하게 잡아 내야 할 때 유용.
- 반면, 의미(semantic)가 비슷하지만 다른 단어인 경우 비교가 불가
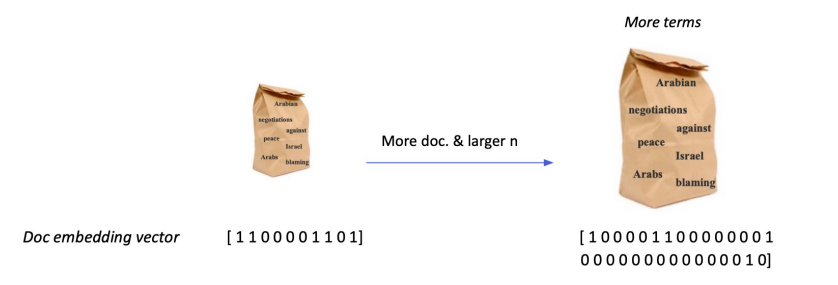
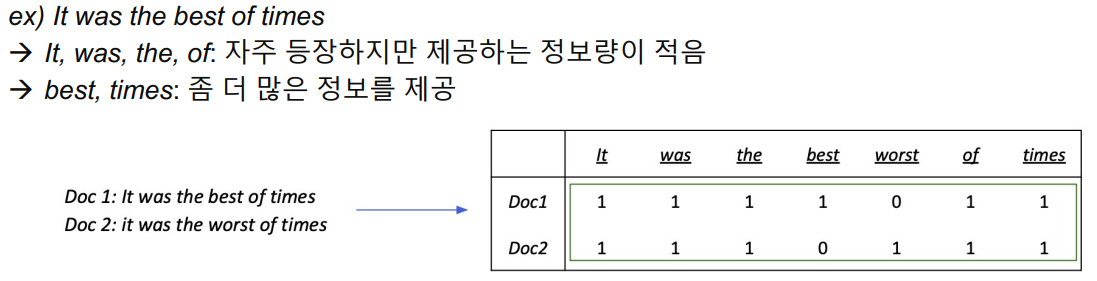
IF-IDF
IF-IDF(Term Frequency - Inverse Document Frequency) 소개
- Term Frequency (TF): 단어의 등장빈도
- Inverse Document Frequency (IDF): 단어가 제공하는 정보의 양
Term Frequency (TF)
해당 문서 내 단어의 등장 빈도
1. Raw count
2. Adjusted for doc length: raw count / num words (TF)
3. Other variants: binary, log normalization, etc.
Inverse Document Frequency (IDF)
단어가 제공하는 정보의 양
Combine TF & IDF
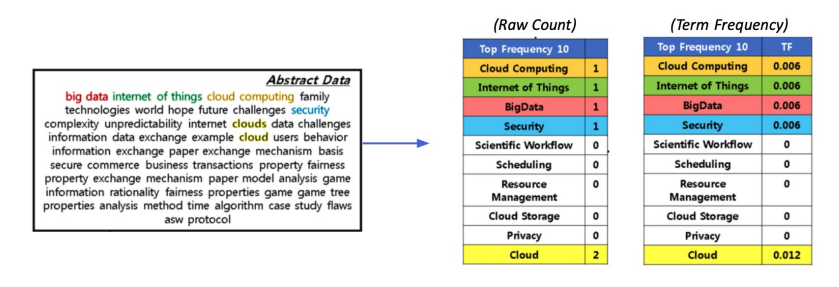

TF-IDF를 이용해 유사도 구해보기
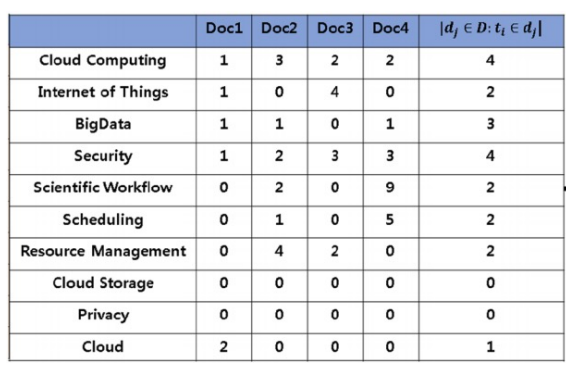
목표: 계산한 문서 IF-IDF를 가지고 질의 TF-IDF를 계산한 후 가장 관련있는 문서를 찾기
1. 사용자가 입력한 질의를 토큰화
2. 기존에 단어 사전에 없는 토큰들은 제외
3. 질의를 하나의 문서로 생각하고, 이에 대한 TF-IDF 계산
4. 질의 TF-IDF 값과 각 문서별 TF-IDF 값을 곱하여 유사도 점수 계산
5. 가장 높은 점수를 가지는 문서 선택

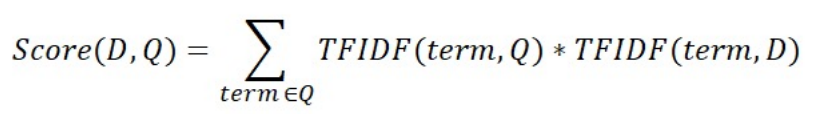
BM25란?
TF-IDF의 개념을 바탕으로, 문서의 길이까지 고려하여 점수를 매김
- TF 값에 한계를 지정해두어 일정한 범위를 유지하도록 함
- 평균적인 문서의 길이보다 더 작은 무서에서 단어가 매칭된 경우 그 문서에 대해 가중치를 부여
- 실제 검색엔진, 추천 시스템 등에서 아직까지도 많이 사용되는 알고리즘
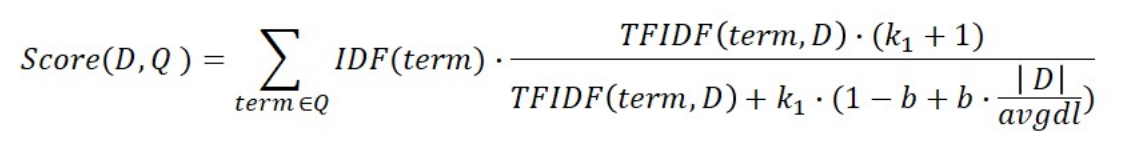
3. 피어세션 정리
- 1~3강 강의 관련 질문
- metric에 대한 논의
4. 회고
- Retriever 첫날.. 아직 코드에 대한 이해가 부족하다.
