
1. 오늘 일정
1) 강의 수강
2) 마스터 클래스
3) 피어 세션
2. 학습 정리
MRC
6강: Scaling up with FAISS
복습: Retrieval with dense embedding
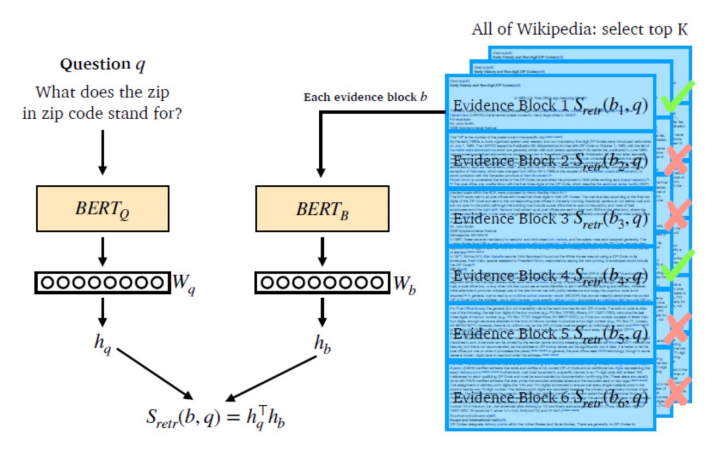
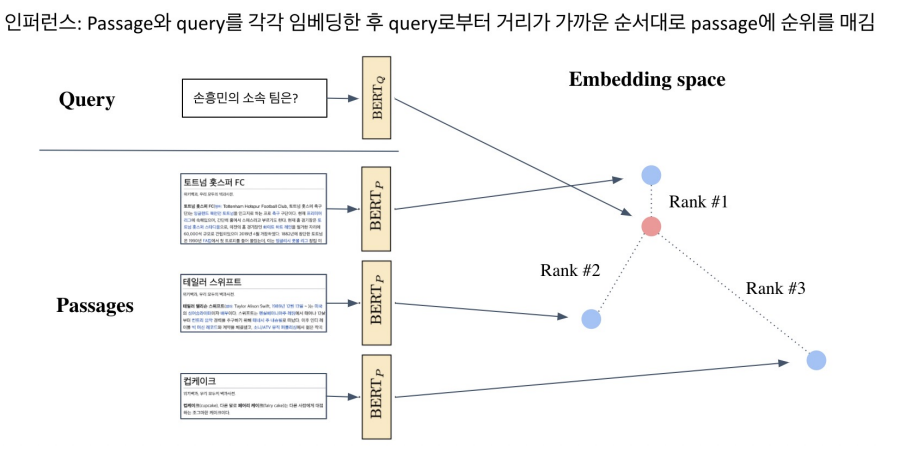
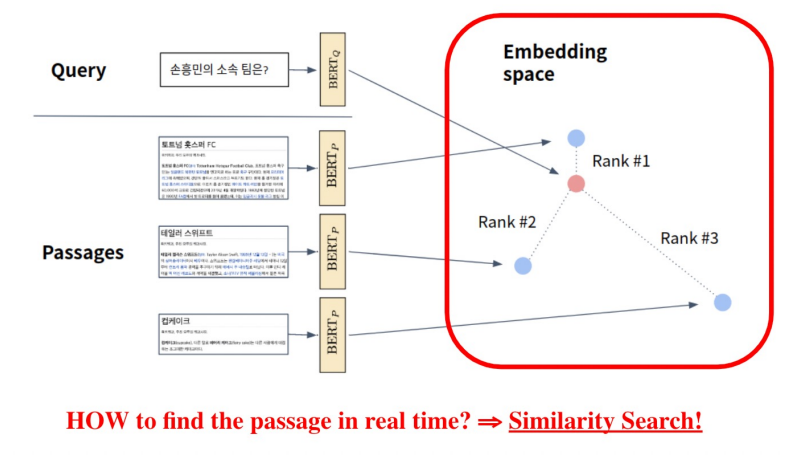
Passage Retrieval and Similarity Search
MIPS(Maximum Inner Product Search)
주어진 질문(query) 벡터 q에 대해 Passage 벡터 v 들 중 가장 질문과 관련된 벡터를 찾아야 함
- 여기서 관련성은 내적(inner product)이 가장 큰 것
4, 5강에서 사용한 검색 방법: brute-force(exhaustive) search
- 저장해둔 모든 Sparse/Dense 임베딩에 대해 일일이 내적값을 계산하여 가장 값이 큰 passage를 추출
- MIPS & Challenges: 실제로 검색해야할 데이터는 훨씬 방대함
- 5백만 개(위키피디아)
- 수십 억, 조 단위까지 커질 수 있음
=> 따라서 더이상 모든 문서 임베딩을 일일이 보면서 검색할 수 없음
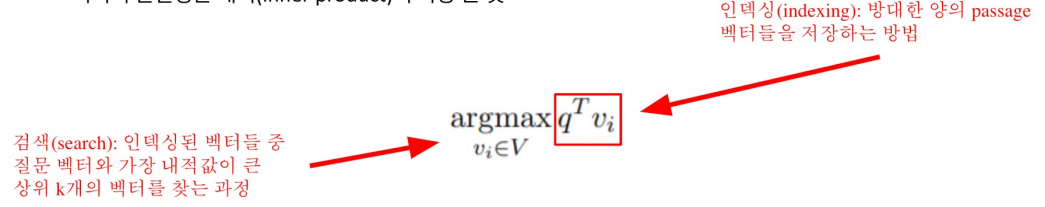
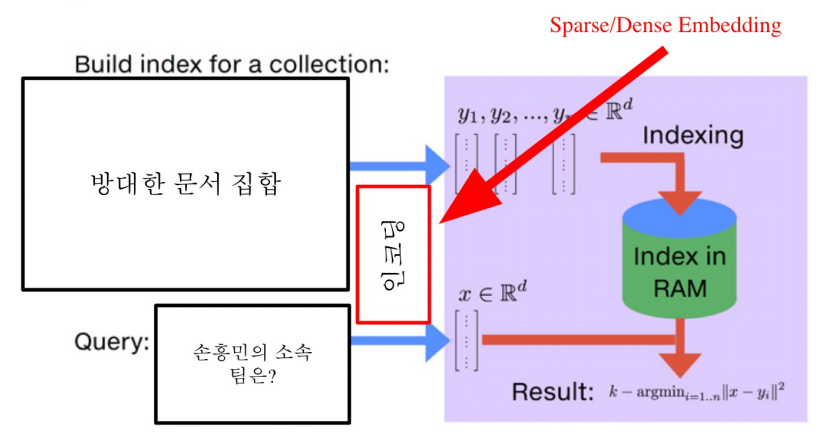
Tradeoffs of similarity search
1) Search Speed
쿼리 당 유사한 벡터를 k개 찾는데 얼마나 걸리는지?
-> 가지고 있는 벡터량이 클수록 더 오래 걸림
2) Memory Usage
벡터를 사용할 때, 어디에서 가져올 것인지?
-> RAM에 모두 올려둘 수 있으면 빠르지만, 많은 RAM 용량을 요구랗ㅁ
-> 디스크에서 계속 불러와야한다면 속도가 느려짐
3) Accuracy
brute-force 검색 결과와 얼마나 비슷한지?
-> 속도를 증가시키려면 정확도를 희생해야하는 경우가 많음
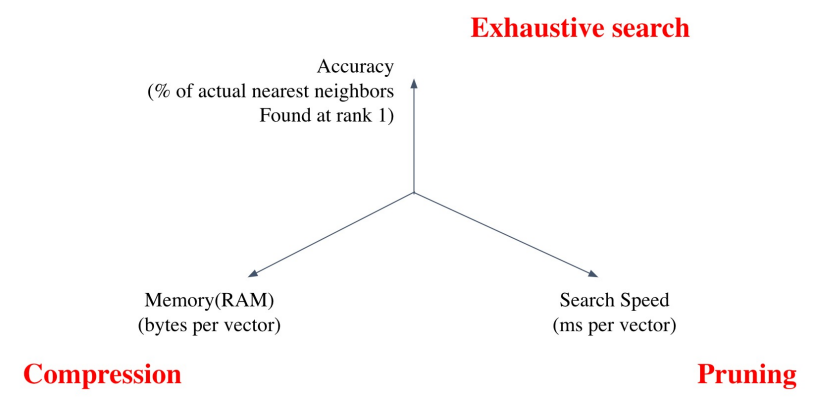
Tradeoff of search speed and accuracy
속도(search time)와 재현율(recall)의 관계
- 더 정확한 검색을 하려면 더 오랜 시간이 소모됨
Increasing search space by bigger corpus
코퍼스(corpus)의 크기가 커질 수록
- 탐색 공간이 커지고 검색이 어려워짐
- 저장해 둘 Memory space 또한 많이 요구됨
- Sparse Embedding의 경우 이러한 문제가 훨씬 심함
Approximating Similarity Search
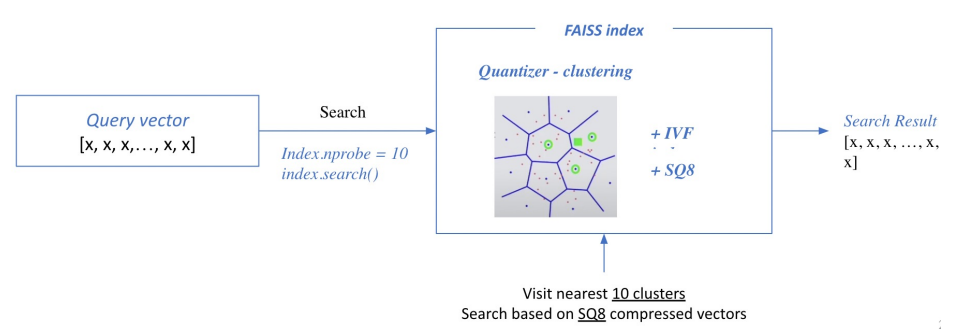
Pruning - Inverted File (IVF)
Pruning: Search space를 줄여 search 속도 개선 (dataset의 subset만 방문)
=> Clustering + Inverted file을 활용한 search
1) Clustering: 전체 vector space를 k개의 cluster로 나눔 (ex. k-means clustering)
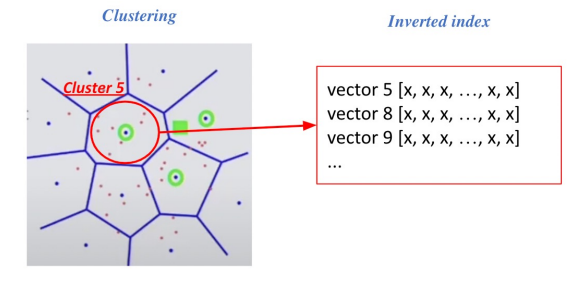
2) Inverted file (IVF)
: Vector의 index - inverted list structure
=> (각 cluster의 centroid id)와 (해당 clustter의 vector들)이 연결되어있는 형태
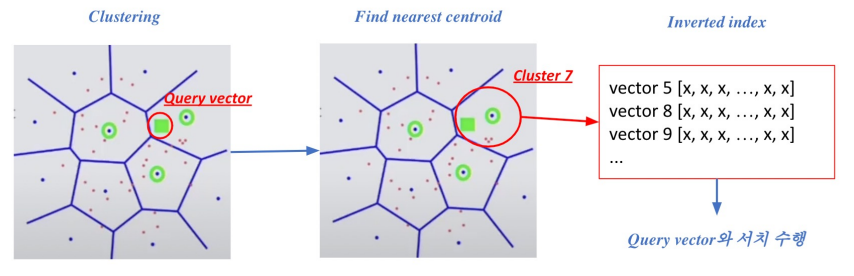
3) Searching with clustering ad IVF
- 주어진 query vector에 대해 근접한 centroid 벡터를 찾음
- 찾은 cluster의 inverted list 내 vector들에 대해 서치 수행

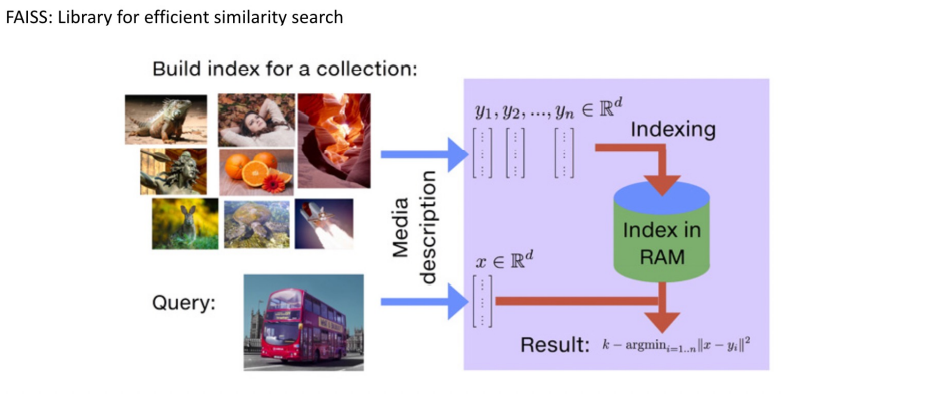
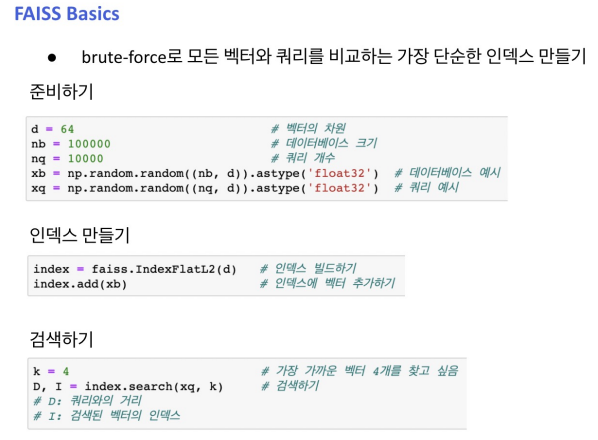
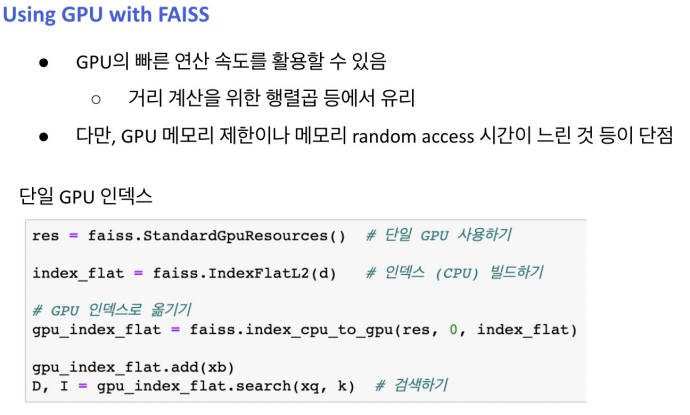
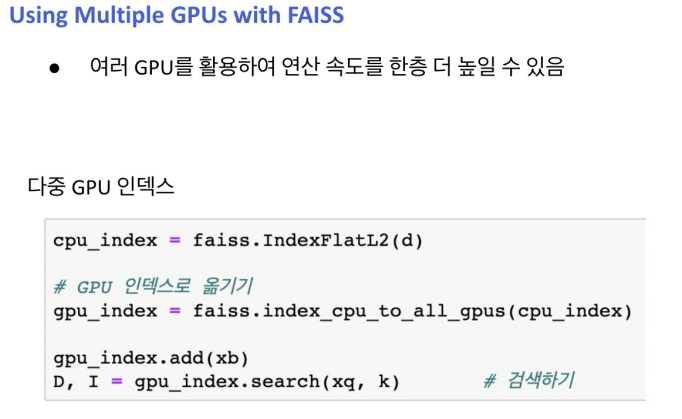
Introduction to FAISS

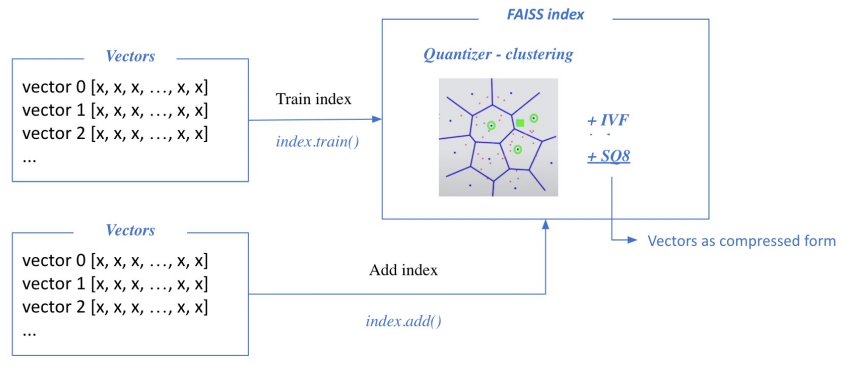
Passage Retrieval with FAISS
1) Train index and map vectors
2) Search based on FAISS index
*nprobe: 몇 개의 가장 가까운 cluster를 방문하여 search 할 것인지
Scaling up with FAISS


7강: Linking MRC and Retrieval
Introduction to Open-domain Question Answering (ODQA)
Linking MRC and Retrieval: Open-domain Question Answering (ODQA)
MRC: 지문이 주어진 상황에서 질의응답
ODQA: 지문이 따로 주어지지 않음. 방대한 World Knowledge에 기반해서 질의응답
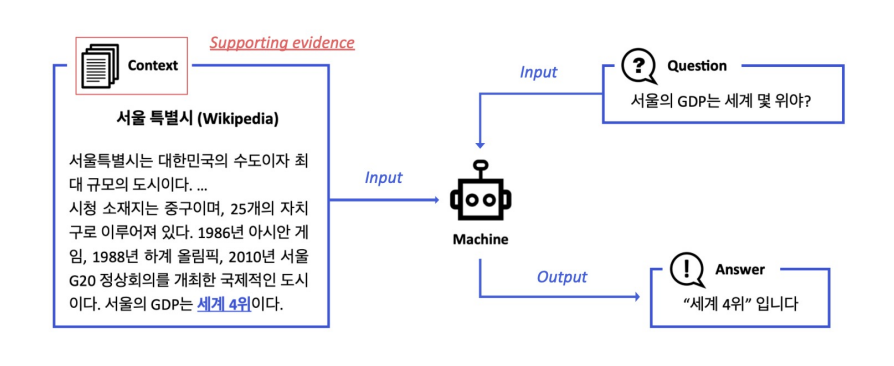
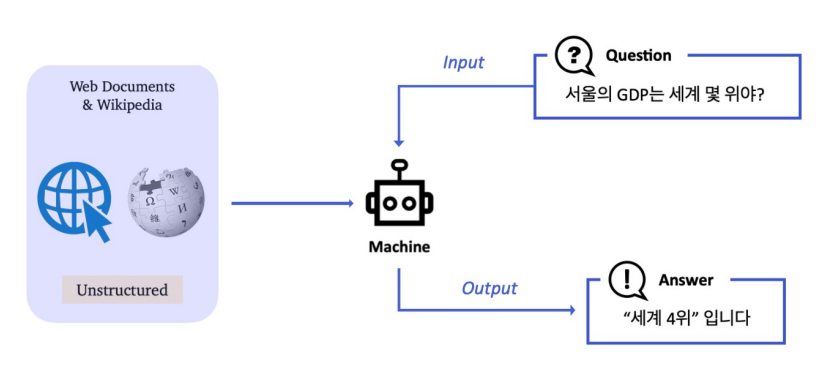
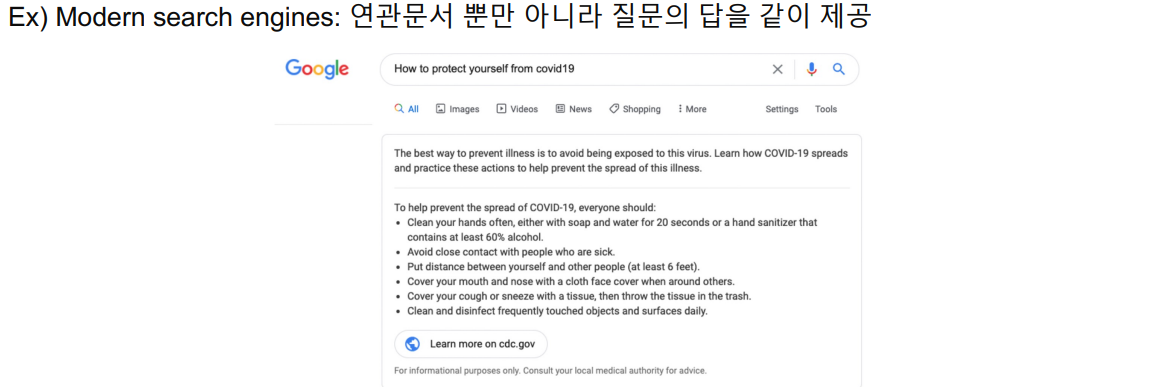
History of ODQA
Text retrieval conference (TREC) – QA Tracks (1999-2007): 연관문서만 반환하는 information
retrieval (IR)에서 더 나아가서, short answer with support 형태가 목표
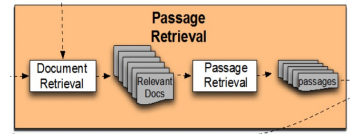
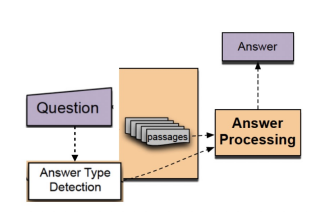
1) Question processing + 2) Passage retrieval + 3) Answer processing1) Question processing
Query formulation: 질문으로부터 키워드를 선택 / Answer type selection (ex. LOCATION:
country)
2) Passage retrieval: 기존의 IR 방법을 활용해서 연관된 document를 뽑고, passage 단위로 자른
후 선별 (Named entity / Passage 내 question 단어의 개수 등과 같은 hand-crafted features 활용)
3) Answer processing
Hand-crafted features와 heuristic을 활용한 classifier
주어진 question과 선별된 passage들 내에서 답을 선택
IBM Watson (2011)
- The DeepQA Project
- Jeopardy! (TV quiz show) 우승
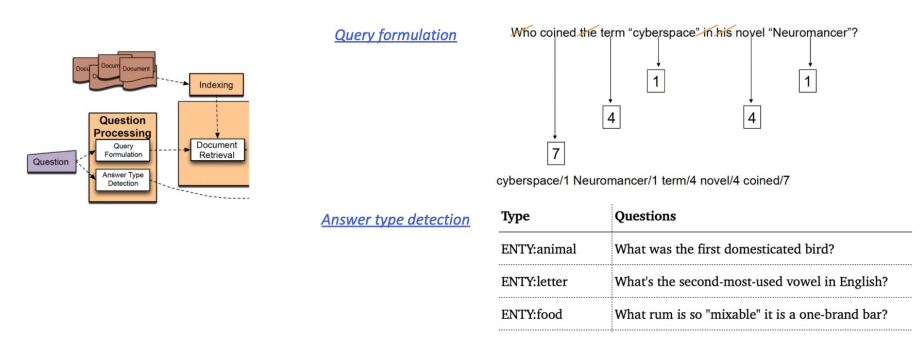

Recend ODQA Research
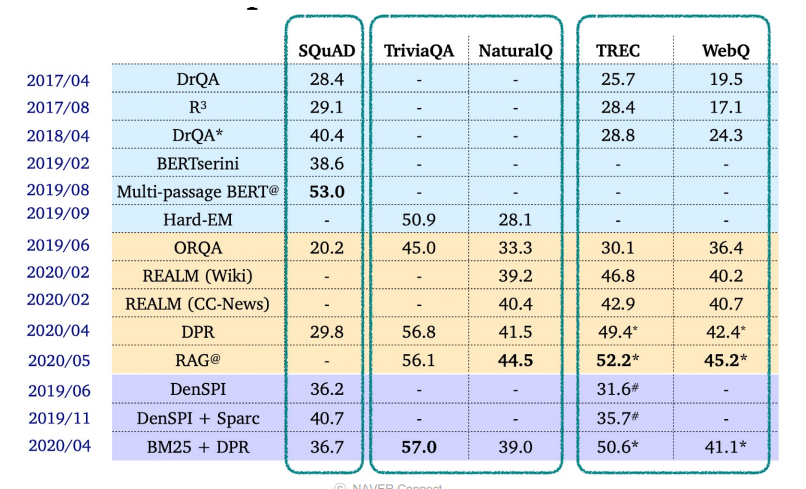
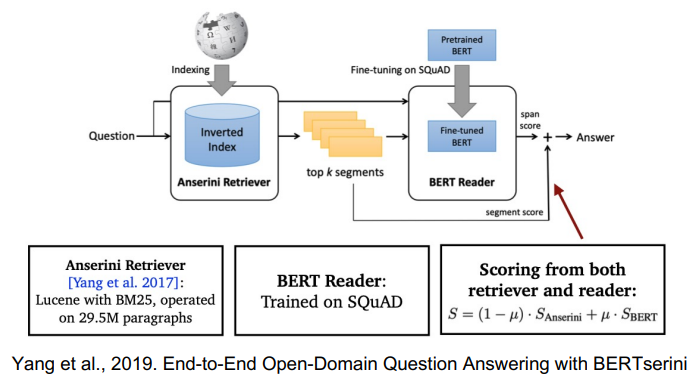
Retriever-Reader Approach
Retriever-Reader 접근 방식
- Retriever: 데이터베이스에서 관련있는 문서를 검색(search) 함
- Reader: 검색된 문서에서 질문에 해당하는 답을 찾아냄

Retriever
- 입력
- 문서셋 (Document corpus)
- 질문(query)
- 출력
- 관련성 높은 문서(document)
Reader
- 입력
- Retrieved된 문서(document)
- 질문(query)
- 출력
- 답변(answer)
학습 단계
Retriever
- TF-IDF, BM25 -> 학습 없음
- Dense -> 학습 있음
Reader
- SQuAD와 같은 MRC 데이터셋으로 학습
- 학습 데이터를 추가하기 위해서 Distant supervision 활용
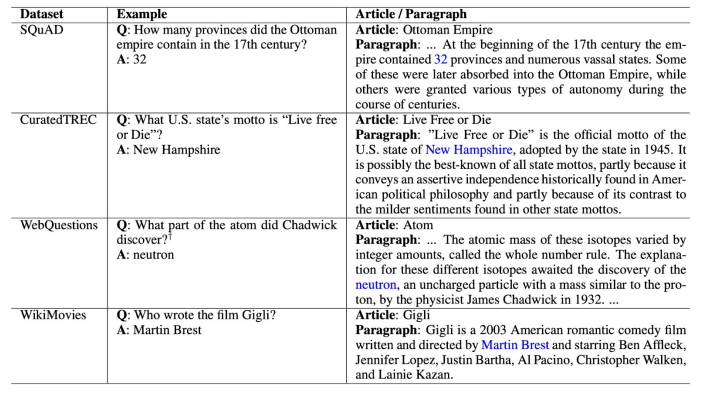
Distant supervision
질문-답변만 있는 데이터셋 (CuratedTREC, WebQuestions, WikiMovies)에서 MRC 학습 데이터 만들기. Supporting document가 필요함
1. 위키피디아에서 Retriever를 이용해 관련성 높은 문서를 검색
2. 너무 짧거나 긴 문서, 질문의 고유명사를 포함하지 않는 등 부적합한 문서 제거
3. answer가 exact match로 들어있지 않은 문서 제거
4. 남은 문서 중에 질문과 (사용 단어 기준) 연관성이 가장 높은 단락을 supporting evidence로 사용함
- 각 데이터셋 별 distant supervision을 적용한 예시
Inference- Retriever가 질문과 가장 관련성 높은 5개 문서 출력
- Reader는 5개 문서를 읽고 답변 예측
- Reader가 예측한 답변 중 가장 score가 높은 것을 최종 답으로 사용함
Issues & Recent Approaches
Different granularities of text at indexing time
위키피디아에서 각 Passage의 단위를 문서, 단락, 또는 문장으로 정의할지 정해야 함.
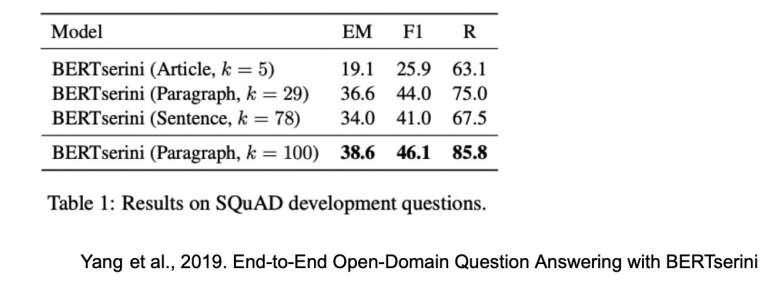
- Article: 5.08 million
- Paragraph: 29.5 million
- Sentence: 75.9 million
Retriever 단계에서 몇개(top-k)의 문서를 넘길지 정해야 함
Gnanularity에 따라 k가 다를 수 밖에 없음
(e.g. article -> k=5, paragraph -> k=29, sentence -> k=28)
Single-passage training vs Multi-passage training
(Single-passage): 현재 우리는 k 개의 passages 들을 reader이 각각 확인하고 특정 answer span에 대한 에측 점수를 나타냄. 그리고 이 중 가장 높은 점수르 ㄹ가진 answer span을 고르도록 함
=> 이 경우 각 retrieved passages 들에 대한 직접적인 비교라고 볼 수 없음
-> 따로 reader 모델이 보는 게 아니라 전체를 한번에 보면 어떨까?(Multi-passage): retrieved passages 전체를 하나의 passage로 취급하고, reader 모델이 그 안에서 answer span 하나를 찾도록 함
Cons: 문서가 너무 길어지므로 GPU에 더 많은 메모리를 할당해야함 & 처리해야하는 연산량이 많아짐
Importance of each passage
Retriever 모델에서 추출된 top-k passage들의 retrieval score를 reader 모델에 전달
3. 피어세션 정리
- 강의는 주말까지 다 듣자.
- 각자 EDA 세부분야 맡아서 주말에 진행
4. 회고
MRC 첫 주가 지나갔다. EDA의 경우 다음주까지 지속적으로 진행해야 할듯하다. 주말내로는 베이스라인 코드를 이해하고 다음주부터 많은 실험을 하도록 하자!
