
1. 오늘 일정
1) 강의 학습
2) 피어 세션
3) 오피스 아워
2. 학습 정리
MRC
5강: Passage Retrieval – Dense Embedding
Introduction to Dense Embedding
Passage Embedding
구절(Passage)을 벡터로 변환하는 것
TF-IDF 벡터는 Sparse하다.

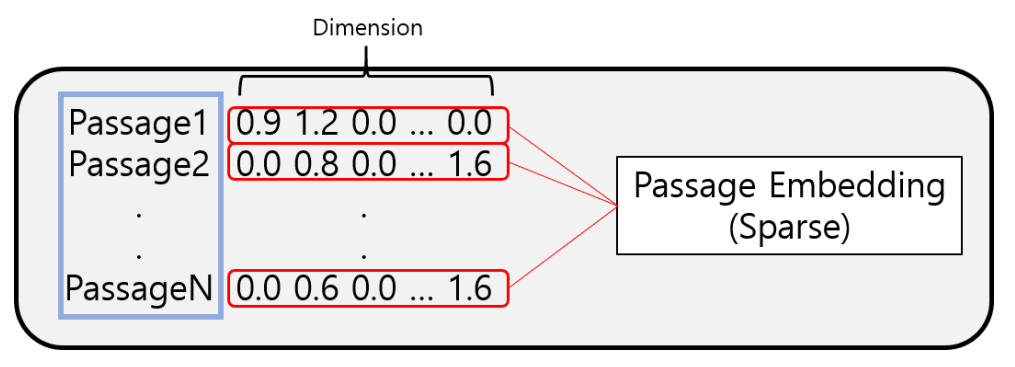
Limitations of sparse embedding
1. 차원의 수가 매우 크다 -> compressed format으로 극복 가능
2. 유사성을 고려하지 못한다.
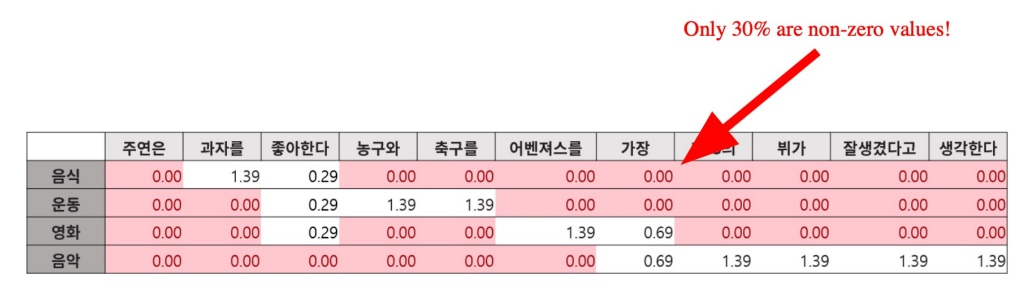
Dense Embedding 이란?
Complementary to sparse reperesentations by design
- 더 작은 차원의 고밀도 벡터 (length = 50-1000)
- 각 차원이 특정 term에 대응되지 않음
- 대부분의 요소가 non-zero값


Retrieval: Sparse vs Dense
Sparse Embedding
1. 중요한 term들이 정확히 일치해야 하는 경우 성능이 뛰어남
2. 임베딩이 구축되고 나서는 추가적인 학습이 불가능함
Dense Embedding
1. 단어의 유사성 또는 맥락을 파악해야 하는 경우 성능이 뛰어남
2. 학습을 통해 임베딩을 만들며 추가적인 학습 또한 가능=> 최근 사전학습 모델의 등장, 검색 기술의 발전 등으로 인해 Dense Embedding을 활발히 이용
Overview of Passage Retrieval with Dense Embedding
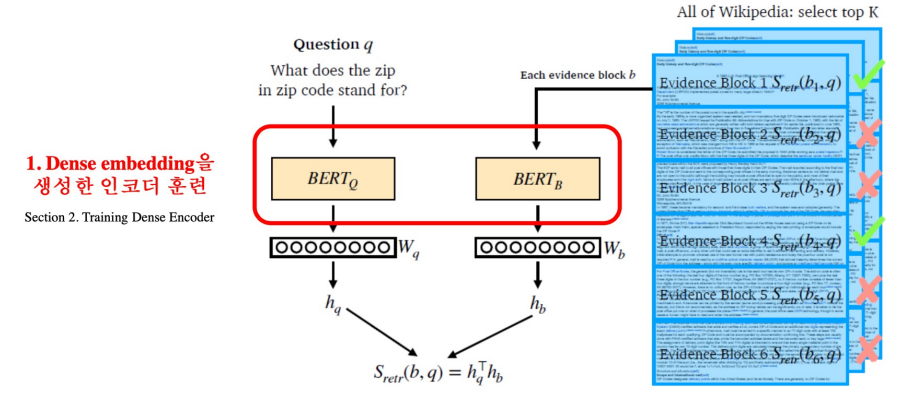
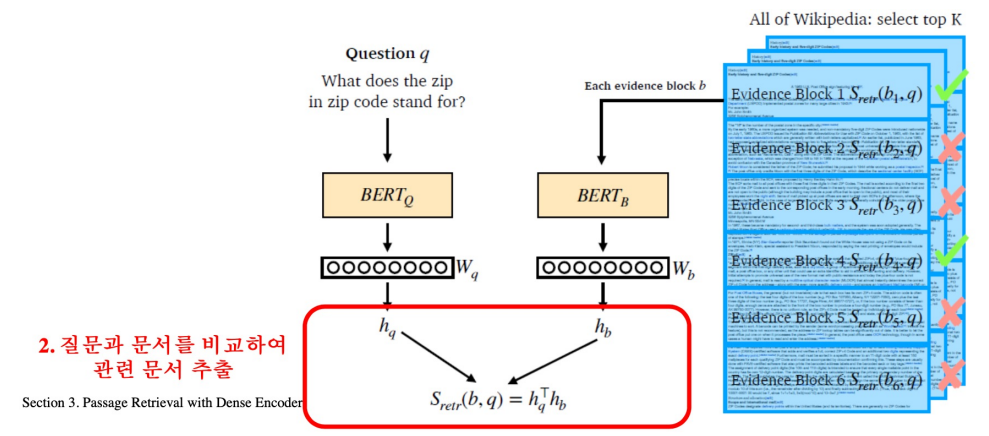
Training Dense Encoder
What can be Dense Encoder?
BERT와 같은 Pre-trained language model (PLM)이 자주 사용
그 외 다양한 neural network 구조도 가능
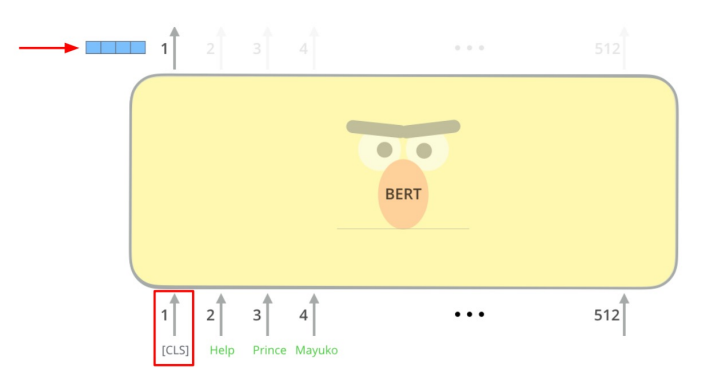
BERT as dense encoder -> [CLS] token의 output 사용
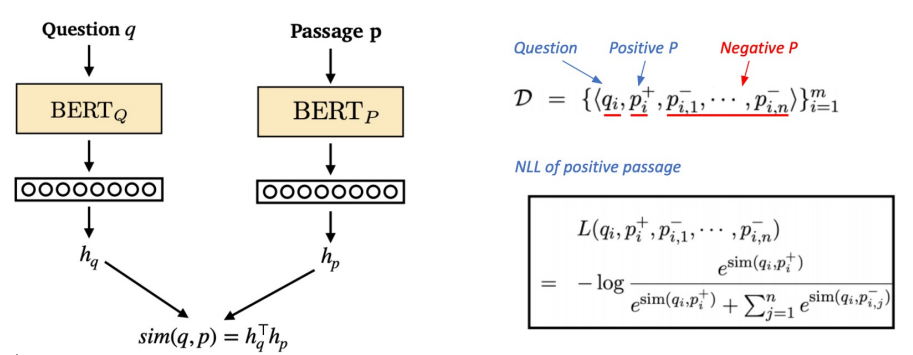
Dense Encoder 구조
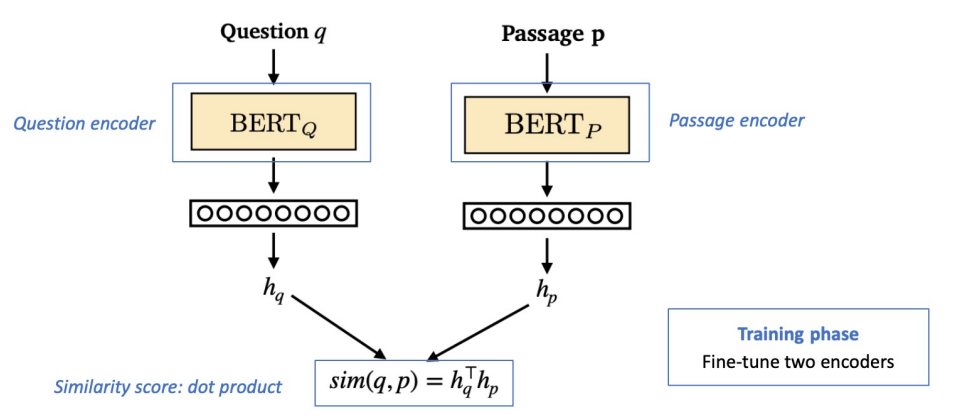
Dense Encoder 학습 목표와 학습 데이터
학습목표: 연관된 quention과 passage dense embedding 간의 거리를 좁히는 것 (또는 inner product를 높이는 것). 즉 higher similarity.
Challenge: 연관된 quention / passage를 어떻게 찾을 것인가?
-> 기존 MRC 데이터셋을 활용
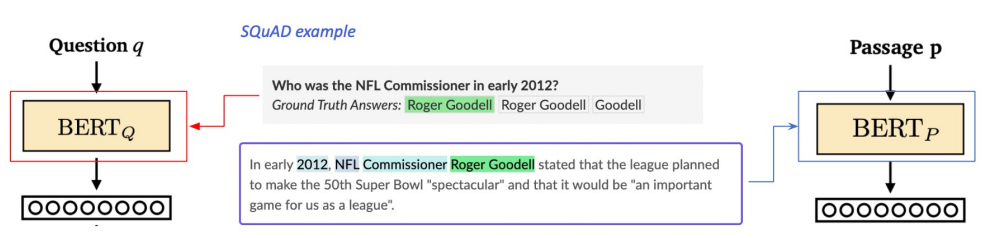
Negative Sampling
1) 연관된 question과 passage간의 dense embedding 거리를 좁히는 것 (higher similarity) => Positive
2) 연관 되지 않은 question과 passage간의 embedding 거리는 멀어야 함 => NegativeChoosing negative examples:
1. Corpus 내에서 랜덤하게 뽑기
2. 좀 더 헷갈리는 negative 샘플들 뽑기 (ex. 높은 TF-IDF 스코어를 가지지만 답을 포함하지 않는 샘플)Objective function
Positive passage 에 대한 negative log likelihood (NLL) loss 사용
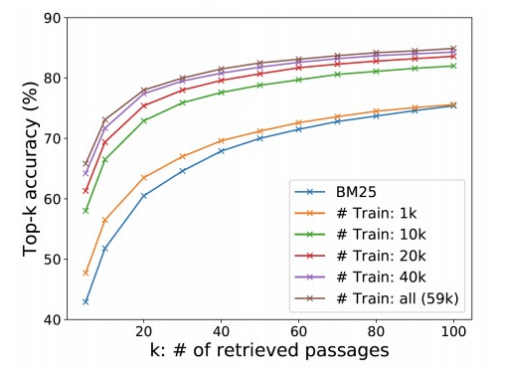
Evaluation Metric for Dense Encoder
Top-k retrieval accuracy: retrieve 된 passage 중에 답을 포함하는 passage의 비율
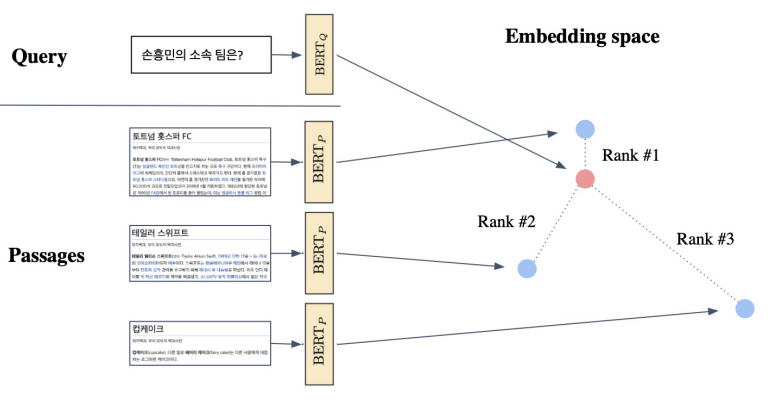
Passage Retrieval with Dense Encoder
From dense encoding to retrieval
Inference: Passage와 query를 각각 embedding한 후, query로부터 가까운 순서대로 passage의 순위를 매김
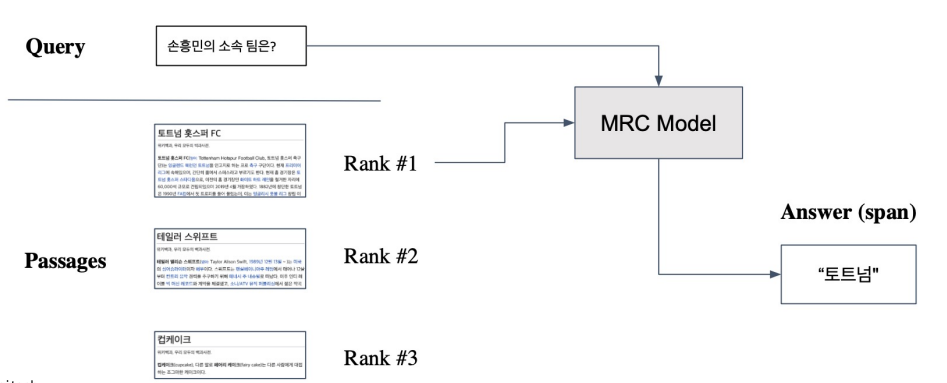
From retrieval to open-domain question answering
Retriever를 통해 찾아낸 Passage를 활용, MRC (Machine Reading Comprehension) 모델로 답을 찾음.
How to make better dense encoding
학습 방법 개선 (e.g. DPR)
인코더 모델 개선 (BERT보다 큰, 정확한 Pretrained모델)
데이터 개선 (더 많은 데이터, 전처리, 등)
3. 피어세션 정리
- 4~5강 강의관련 질문
- DPR에 대한 논의
4. 회고
- 오피스아워때 들은 베이스라인 코드 설명을 바탕으로 이번주내에 코드 이해를 해야겠다.
- dense embedding으로 좀 더 생각해볼 점이 많아진 것 같다.
