수업 때 강사님께서 제시해주신 버섯 분류 모델 실습을 수업이 끝나고서야 성공,,
복습이 아닌 나머지 학습은 참 오랜만이다.
나머지 학습이 끝났으니 복습을 다시 해야겠지.
데이터 준비
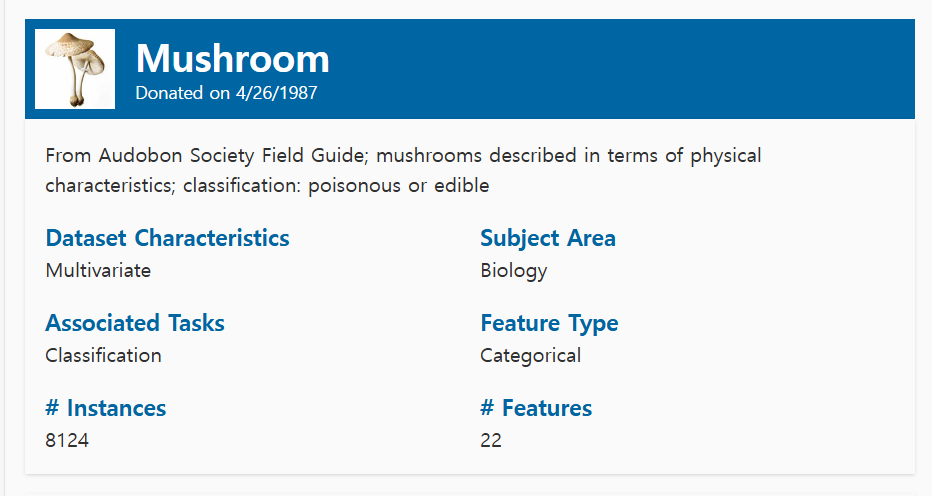
데이터 다운로드
데이터링크: 버섯데이터
링크에서 제공하는 버섯 데이터를 받아서 .data 파일을 .csv 파일로 변경 후 ?로 되어 있는 누락값들을 공백으로 처리해주었다.

데이터 업로드
Azure ML Studio에 업로드. 헤더값이 없는 상태로 업로드하였다.
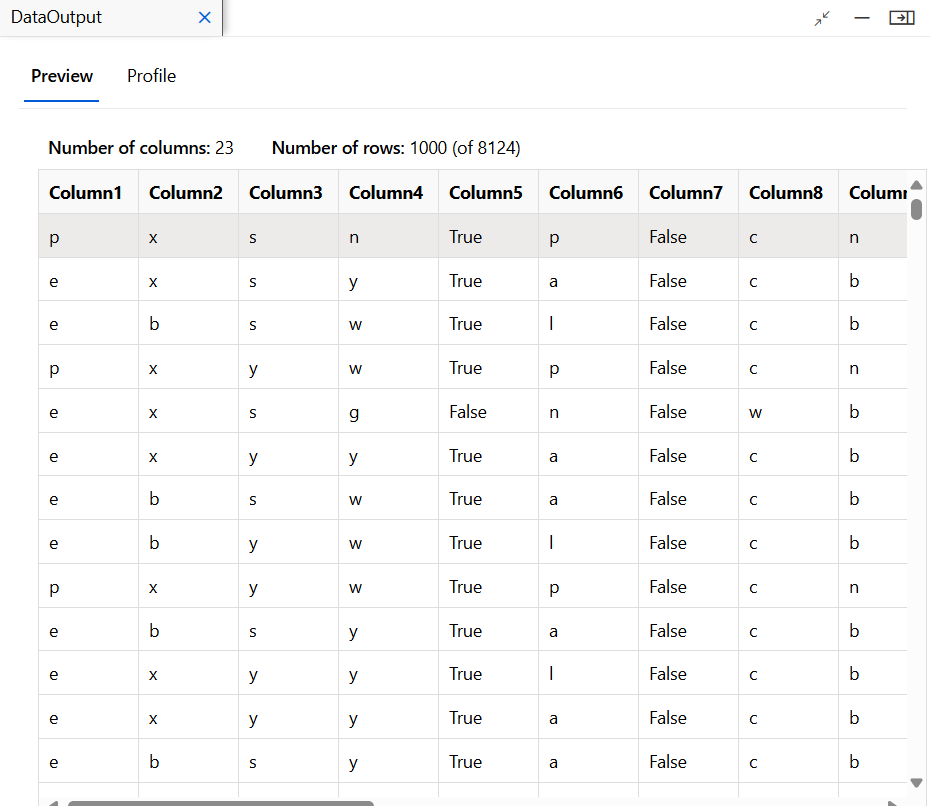
데이터 전처리
헤더 추가
Edit Metadata 컴포넌트를 이용해 헤더를 추가해주었다.
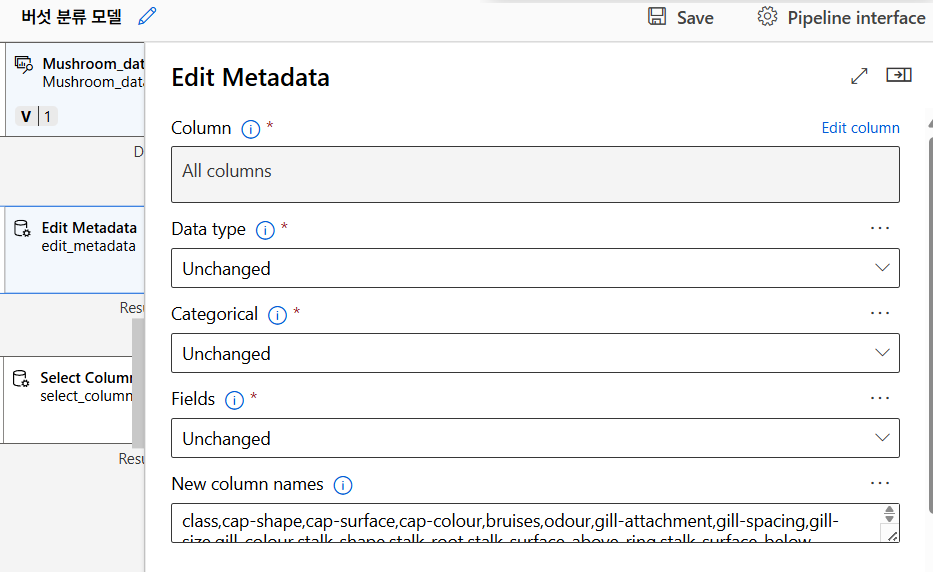
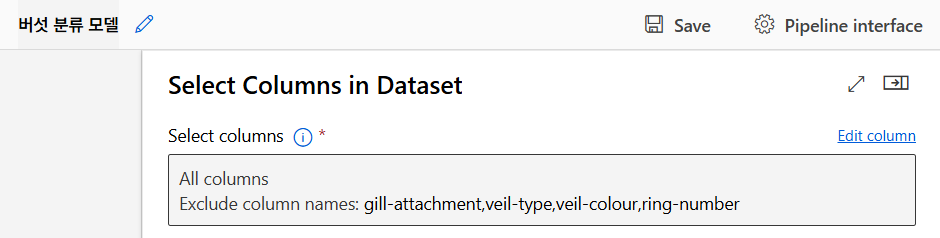
사용하지 않는 컬럼 제거
극단적인 값이 많은 컬럼을 Select Columns in Dataset 컴포넌트를 이용해 제거하였다. 불필요한 정보를 제거해서 데이터의 노이즈를 줄이는 데에 목표가 있었다.
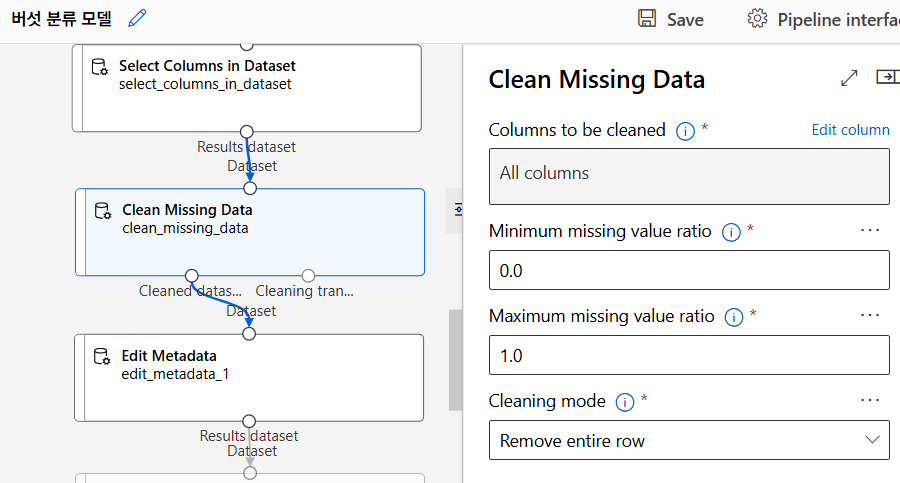
누락값 처리
Clean Missing Data를 통해 누락값 처리. 머신러닝 모델은 누락된 데이터를 처리할 수 없다고 들었다. 아닌가 미리 누락값을 대체해줌으로써 모델 학습과 예측 정확도를 높이자는 목표.
데이터 변환
String to Categorial
Edit Metadata 컴포넌트를 이용하여 문자형 변수를 범주형 변수로 변환. 머신러닝 알고리즘은 수치형 데이터에 최적화되어 있으므로 문자형 변수를 범주형으로 변환해서 모델이 데이터를 더 잘 이해할 수 있도록 작업하였다.
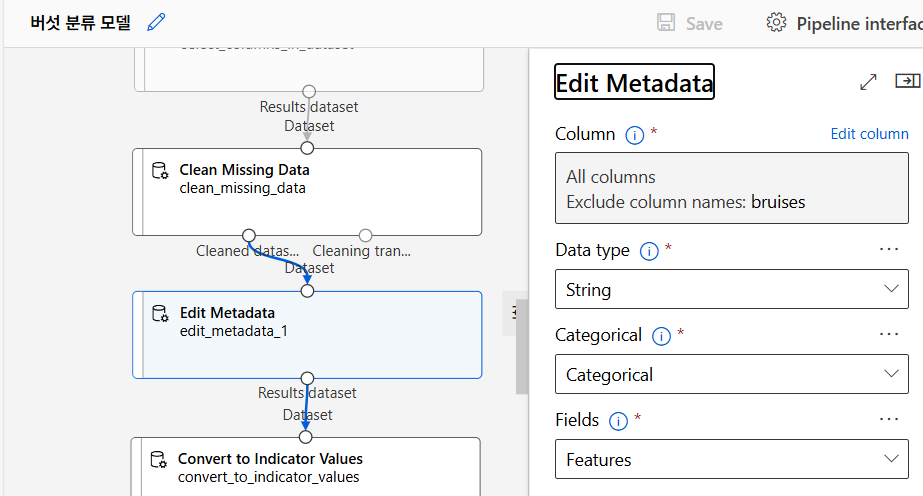
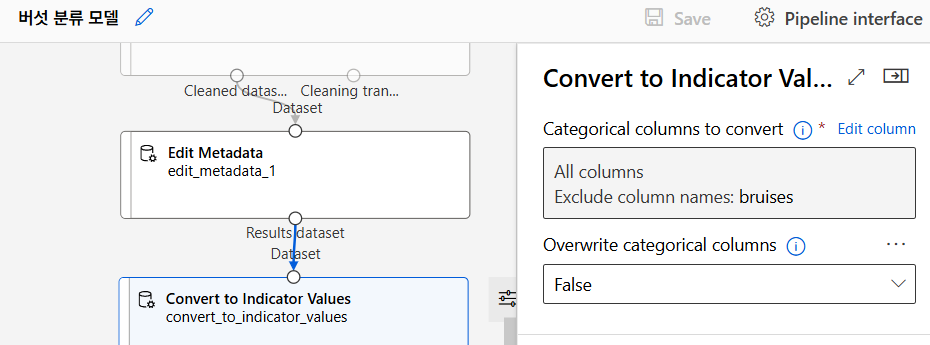
Categorial to Indicator Values
Convert to Indicator Values 컴포넌트를 사용하여 범주형 변수를 이진 변수로 변환. 머신러닝 모델이 이진 변수를 통해 각 범주를 독립적으로 처리할 수 있도록 작업하였다.
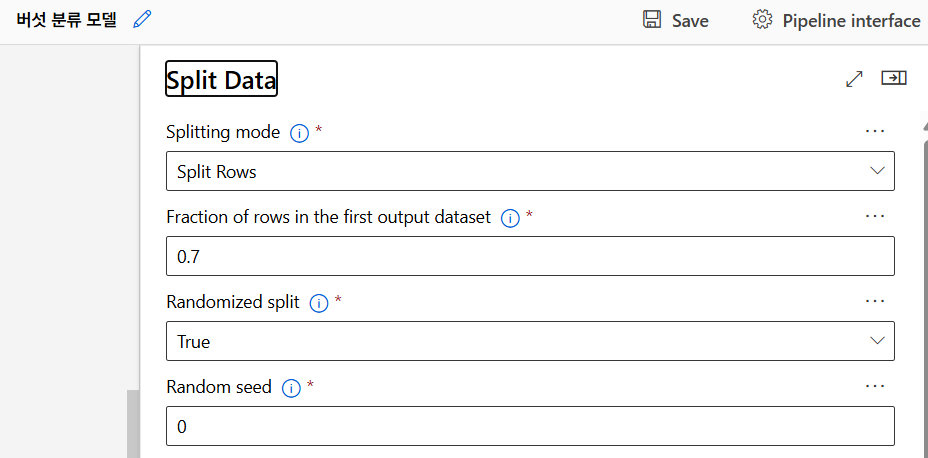
데이터 분할
Split Data 모듈을 사용해 데이터를 학습용과 테스트용으로 분리. (학습용 70, 테스트용 30)
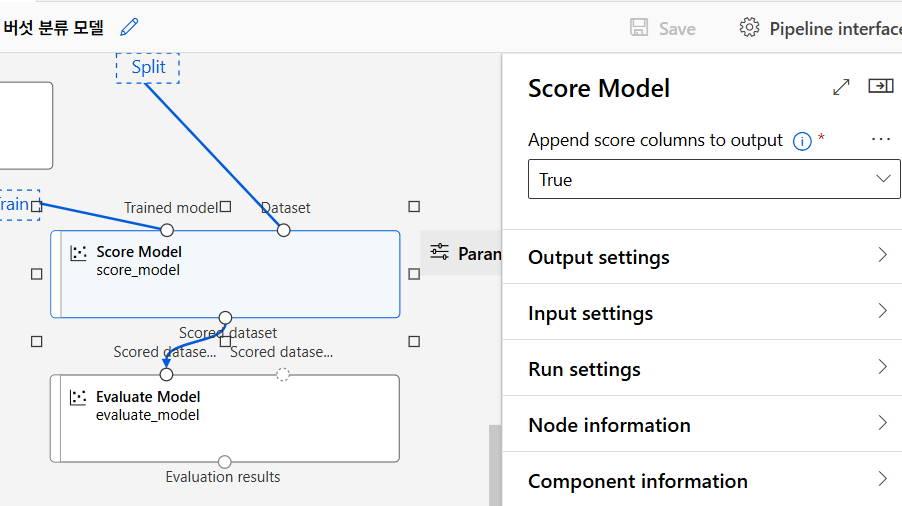
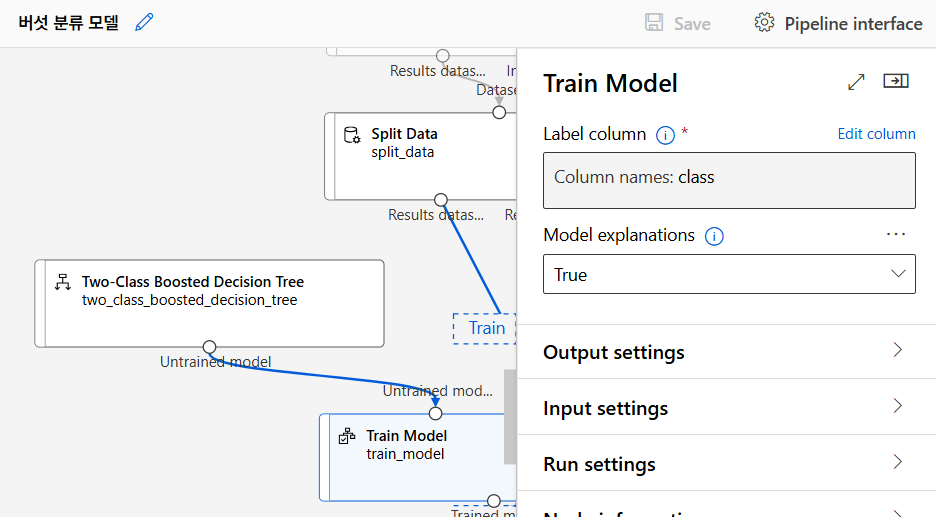
모델 구축
Two-Class Boosted Decision Tree 모델 선택. Train Model로 훈련. Two-Class Boosted Decision Tree 모델은 이진 분류 문제에 적합하고, 여러 weak learner를 결합하여 strong learner를 만드는 방식으로 작동한다.
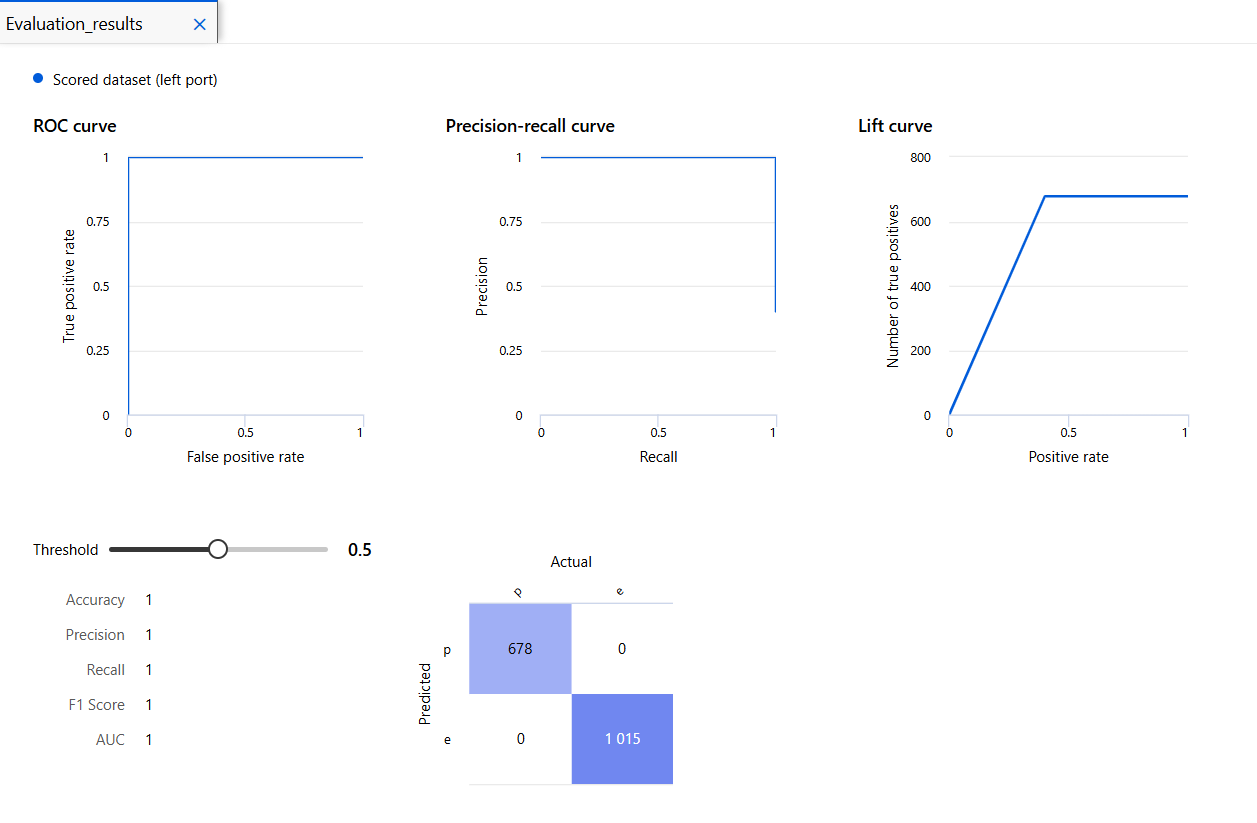
모델 평가
Score Model과 Evaluate Model을 통해 모델 성능 평가.