
오늘 한줄 요약

오늘 공부한 것
- 백준(10815 숫자카드)
- CSAPP (1.8 ~ 1.9)
- 그래프의 종류와 구현(표현) 방법
새로 배우게 된 것
BOJ(19815, 1966)
- 19815 : 숫자 카드
bisect 모듈로 딸깍 하려고 했지만 모듈 말고 최대한 구현해보라는 누군가의 가르침이 떠올라
반복문을 통해 구현했다.(2012ms)
import sys
input = sys.stdin.readline
N = int(input())
sangeun = sorted(list(map(int, input().split())))
M = int(input())
num_list = list(map(int, input().split()))
start = 0
end = len(sangeun) - 1
def binary_search(arr, start, end, target):
while start <= end:
mid = (start + end) // 2
if arr[mid] > target: # mid 기준 왼쪽에 target 위치
end = mid - 1
elif arr[mid] == target:
return 1
else:
start = mid + 1
return 0
for num in num_list:
print(binary_search(sangeun,start, end, num), end=' ')dict와 Set을 활용한 풀이도 있어서 가져와봤다.(692ms)
아래의 풀이가 빠른 이유는 dict 자료형이 조회연산의 시간 복잡도가 O(1) 시간이며
List의 in 조회 연산은 O(N)의 시간 복잡도가 걸려서 같은 풀이도 list를 썼다면 시간 초과가 발생한다.
import sys
size_a=int(sys.stdin.readline())
deck=list(map(int,sys.stdin.readline().split()))
# dict 자료형 초기화
dict_deck_a={}
# 각 숫자값을 Idx로 하여 그 idx 값을 1로 변경 => 어차피 겹치는 수가 안나오니까
for num in deck:
dict_deck_a[num]=1
size_b=int(sys.stdin.readline())
deck=list(map(int,sys.stdin.readline().split()))
# M개의 정수
for num in deck:
if num not in dict_deck_a:
print('0',end=" ")
else:
print(dict_deck_a[num],end=" ")
리스트 vs 튜플
- 리스트는 인덱스를 지정하여 값 변경이 가능 vs 튜플은 변경 불가
list = [1, 2 ,3, 'python']
tuple_ = (1, 2, 3, 'python')
tuple_[0] = 2 # X
# 수정하기 위해선 2 + tuple_[1:]- Tuple - Unpacking 기능 : 튜플의 값을 차례대로 변수에 대입하는 기능
a. 리스트는 변할 수 있는 mutable 자료형이기때문에 아래처럼 할당이 불가
a, b, c = 100, 200, (100,200)# a, b 값 Swap
a = 4
b = 5
c = a
a = b
b = c
# tuple 쓰면
a, b = b, adict와 set의 차이
- dict의 경우 Key와 value 값이 존재한다
- set은 Key 값만 존재
# 두 데이터 타입 모두 중복값 X
dict_ = {'korea' : 'seoul' , 'japan' : 'tokyo'}
set_ = {1, 2, 3, 4}CSAPP 1.8 ~ 1.9
-
네트워크의 역할
다른 시스템과의 연결 도구로서 또 다른 입출력 장치로 볼 수 있다. -
암달의 법칙
내 작업을 통해 N 만큼 성능개선이 일어났을 때 시스템에 얼마만큼의 임팩트가 있는가? -
동시성 vs 병렬성
- 동시성: 여러 작업을 동시에 수행하는 것 (예: 단일 프로세서에서 빠르게 전환).
- 여러 작업 처리 시 주체가 작업들을 바꾸어가며 동시에 처리
- 병렬성: 여러 작업을 동시에 실행하여 시스템을 더 빠르게 만드는 것 (예: 멀티코어 사용).
- 여러 작업 처리시 처리하는 주체를 늘리는 방법
- 동시성: 여러 작업을 동시에 수행하는 것 (예: 단일 프로세서에서 빠르게 전환).
-
멀티 쓰레딩 vs 하이퍼 쓰레딩
- 멀티쓰레딩 → 여러 스레드 병렬로 동시 실행(하나의 CPU에서 여러 스레드 처리)
- 하이퍼쓰레딩 → 가상의 두번째 CPU를 인식, 단일 CPU 실행유닛에 두 스레드를 번갈아가며 실행 ⇒ 하나의 CPU를 두개의 CPU인 것 처럼… 활용?
그래프의 종류와 표현 방법
-
그래프
노드(정점)과 간선의 집합이며, 관계를 표현하는 자료구조이자 비선형 자료구조 -
Graph vs TREE
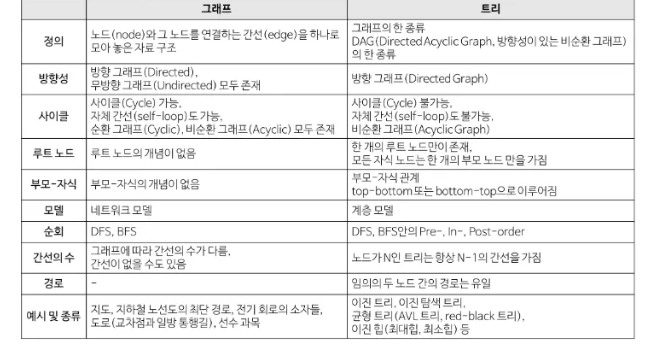
-
인접리스트 vs 인접행렬
graph = [
[0 ,7 ,5],
[7, 0, INF],
[5, INF, 0]
]
graph = [[] for _ in range(3)]
graph[0].append((1,7))
graph[0].append((2,5))
graph[1].append((0,7))
graph[2].append((0,5))
print(graph) # [[(1,7),(2,5)],[(0,7)],[(0,5)]]인접 리스트 vs 인접 행렬
- 인접 리스트: 그래프 내
적은 숫자의 간선만을 갖는 희소 그래프(Sparse Graph)- 장점
- 어떤 노드에 인접한 노드를 쉽게 찾기가 가능
- 그래프에 존재하는 모든 간선 수는 O(N + E) 안에 가능
- 단점
- 간선의 존재 여부와 정점의 차수 만큼 시간이 필요
- 장점
- 인접 행렬 :그래프 내
간선이 많이 있는밀집 그래프(Dense)- 장점
- 두 정잠을 연결하는 간선의 존재여부(
arr[i][j])를 O(1) 안에 즉시 알 수 있다 - 정점의 차수는 O(N) 안에 알 수 있다.
- 두 정잠을 연결하는 간선의 존재여부(
- 단점
- 어떤 노드에 인접한 노드를 찾기 위해선 모든 노드를 전부 순회
- 그래프에 존재하는 모든 간선의 수는 O(N^2) 안에 알 수 있다.
- 장점
공부하면서 아쉬운 점
CSAPP 를 공부하면서 스레드, 프로세스 등의 기초 용어가 제대로 정립되어있지 않아
글을 읽는 데 이해되는 속도가 느렸다...

제 Velog에 오신 모든 분들이 작더라도 인사이트를 얻어가셨으면 좋겠습니다 :)