
오늘 한줄 요약
알고리즘도 머슬메모리!
오늘 공부한 것
- 트리 & 그래프(순회)
- DFS/BFS
- 위상 정렬
새로 배우게 된 것
트리 vs 그래프
“모든 트리는 그래프이지만, 모든 그래프가 트리는 아니다.”
| 구분 | 트리 (Tree) | 그래프 (Graph) |
|---|---|---|
| 정의 | 사이클이 없는 연결된 비순환 그래프 | 노드와 엣지로 구성된 일반적인 자료구조 |
| 구조 | 계층적 구조 (부모-자식 관계) | 네트워크 구조 (모든 노드가 연결될 수 있음) |
| 경로 (Path) | 두 노드 간 유일한 경로 존재 | 두 노드 간 여러 경로 가능 |
| 사이클 (Cycle) | 존재하지 않음 (비순환) | 존재할 수 있음 (순환 허용) |
| 루트 노드 (Root Node) | 존재함 (트리의 시작점) | 존재하지 않을 수 있음 |
| 연결성 (Connectivity) | 모든 노드가 연결됨 (하나의 컴포넌트) | 다수의 컴포넌트로 나뉠 수 있음 |
| 엣지 수 (Edges) | 노드 개수 - 1 (N - 1) | 일반적으로 노드 개수보다 많거나 적을 수 있음 |
| 방향성 (Direction) | 일반적으로 방향이 있음 (단방향) | 방향 그래프 또는 무방향 그래프 모두 존재 가능 |
핵심 차이점
트리와 그래프의 가장 중요한 차이는 사이클의 존재 여부와 부모-자식 관계 유무이다.
트리는 사이클이 없고 계층 구조를 가지며, 모든 노드가 루트로부터 연결되어 있다.
반면, 그래프는 사이클을 허용하고 네트워크 형태로 모든 노드가 자유롭게 연결될 수 있다.
Arc vs Edge
- Arc (아크): 방향 그래프에서 두 정점을 연결하는 경로.
- Edge (엣지): 무방향 그래프에서 두 정점을 연결하는 경로.
그래프 표현 방식 (인접 행렬 vs 인접 리스트)
그래프를 구현할 때 사용하는 대표적인 방식은 인접 리스트와 인접 행렬이다. 두 방식은 그래프의 특성에 따라 성능 차이가 크게 발생한다.
인접 리스트 (Adjacency List)
- 그래프 내 적은 숫자의 간선만을 갖는 희소 그래프 (Sparse Graph) 에 유리하다.
- 장점
- 어떤 노드에 인접한 노드를 쉽게 찾을 수 있다.
- 그래프의 모든 간선을 탐색하는 데 O(N + E)의 시간 복잡도를 갖는다.
- 단점
- 간선의 존재 여부를 확인하거나 정점의 차수를 찾는 데 시간이 필요하다.
인접 행렬 (Adjacency Matrix)
- 그래프 내 간선이 많이 있는 밀집 그래프 (Dense Graph) 에 유리하다.
- 장점
- 두 정점 간 간선 존재 여부를
arr[i][j]로 O(1)에 즉시 확인 가능. - 특정 정점의 차수를 찾는 데 O(N) 안에 알 수 있다.
- 두 정점 간 간선 존재 여부를
- 단점
- 어떤 노드에 인접한 노드를 찾기 위해 모든 노드를 전부 순회해야 한다.
- 그래프의 모든 간선을 탐색하는 데 O(N^2)의 시간 복잡도를 갖는다.
예제 코드
# 인접 행렬 방식
graph = [[0] * (N + 1) for _ in range(N + 1)]
for i in range(M):
a, b = map(int, input().split())
graph[a][b] = graph[b][a] = 1
# 인접 리스트 방식
graph = [[] for _ in range(N + 1)]
for i in range(M):
start, end = map(int, input().split())
graph[start].append(end)
graph[end].append(start)성능 비교
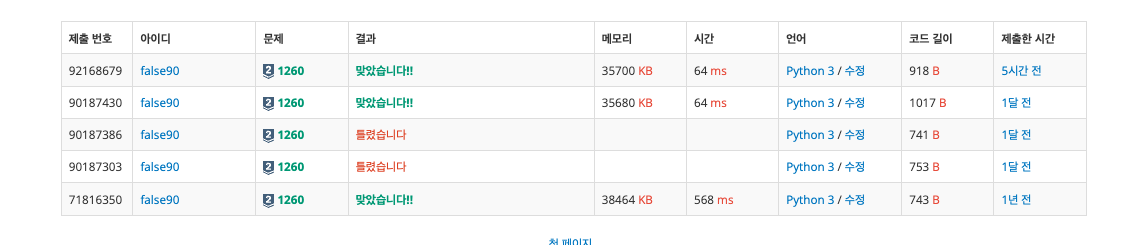
인접 행렬 방식으로 구현한 그래프는 568ms가 소요된 반면,
인접 리스트 방식은 64ms로 훨씬 빠르게 동작하였다.
그래프 구현 방식의 차이에 따라 성능 차이가 크게 발생한다는 점이 인상적이다.
DFS - Depth First Search (깊이 우선 탐색)
DFS는 루트 노드(또는 임의의 노드) 에서 시작하여 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방식입니다.
특징
- 미로 탐색 방식: 한 방향으로 갈 수 있을 때까지 이동하다가 더 이상 진행할 수 없으면 되돌아와 다른 경로 탐색.
- 사용 목적: 모든 노드를 방문하고자 할 때 적합.
- 구현 방식: 재귀 또는 명시적 스택 활용.
- 특징: 단순한 구현, 느린 속도, 최단 경로 보장 불가.
- 시간 복잡도:
- 인접 리스트:
O(N + E) - 인접 행렬:
O(N^2)
- 인접 리스트:
구현 방법 (순환 호출)
def dfs(graph, v, visited):
visited[v] = True # 방문 처리
print(v, end=' ') # 방문한 노드 출력
for i in graph[v]: # 인접 리스트 방식일 경우
if not visited[i]:
dfs(graph, i, visited)- 사용 예시:
visited = [False] * 9 # 방문 체크 리스트
dfs(graph, 1, visited)구현 방법 (스택 활용)
def dfs_stack(graph, start, visited):
stack = [start] # 스택에 시작 노드를 추가
while stack:
v = stack.pop() # 스택의 최상단 노드 꺼내기
if not visited[v]:
print(v, end=' ') # 방문한 노드 출력
visited[v] = True # 방문 처리
# 연결된 노드를 스택에 추가 (역순으로 추가)
for i in reversed(graph[v]):
if not visited[i]:
stack.append(i)BFS - Breadth-First Search (너비 우선 탐색)
BFS는 시작 정점으로부터 가까운 정점을 먼저 방문하고, 멀리 떨어진 정점을 나중에 방문하는 방식입니다.
특징
- 사용 목적: 두 노드 사이의 최단 경로 또는 임의의 경로를 탐색할 때 사용.
(예: 친구 관계 탐색에서 가까운 친구부터 찾기) - 구현 방식: 큐를 이용하여 FIFO 방식으로 탐색.
- 특징: DFS보다 복잡한 구현, 재귀적으로 동작하지 않음.
- 시간 복잡도:
- 인접 리스트:
O(N + E) - 인접 행렬:
O(N^2)
- 인접 리스트:
구현 방법 (Python Code)
def bfs(graph, start, visited):
# deque 모듈 활용한 큐 구현
queue = deque([start])
visited[start] = True # 현재 노드 방문 처리
while queue:
v = queue.popleft() # front 에서 원소 하나 뽑기
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True위상 정렬 (Topological Sort)
위상 정렬은 비순환 방향 그래프 (DAG: Directed Acyclic Graph) 에서 정점들을 순서대로 나열하는 알고리즘이다. 보통 사건 간의 순서를 나타내는 문제에서 활용된다.
특징
- 여러 가지 정답이 존재할 수 있다.
- 모든 원소를 방문하기 전에 큐가 비면 사이클이 존재한다고 판단할 수 있다.
- 보통 큐 (BFS) 를 사용하여 구현하지만, 스택 (DFS) 으로도 구현할 수 있다.
진입차수와 진출차수
- 진입차수 (Indegree): 특정 노드로 들어오는 간선의 개수.
- 진출차수 (Outdegree): 특정 노드에서 나가는 간선의 개수.
위상 정렬 알고리즘 (BFS 방식)
- 진입차수가 0인 노드를 큐에 넣는다.
- 큐가 빌 때까지 다음 과정을 반복한다.
a. 큐에서 원소를 꺼내어 결과 리스트에 추가한다.
b. 해당 노드에서 나가는 모든 간선을 제거한다.
c. 간선이 제거된 후, 새롭게 진입차수가 0이 된 노드를 큐에 추가한다.
의사코드 (Pseudo Code)
Topology_sort(G)
1. 각 정점 v에 대해 종료시간 v.finish 계산 위해 DFS(G) 호출
2. 각 정점이 종료될 때마다 연결리스트 맨 앞에 삽입
3. return 정점들의 연결 리스트파이썬 구현 (BFS 방식)
import sys
from collections import deque
input = sys.stdin.readline
# 노드의 개수와 간선의 개수 입력
v, e = map(int, input().split())
# 모든 노드에 대한 진입차수는 0으로 초기화
indegree = [0] * (v + 1)
# 각 노드에 연결된 간선 정보를 담기 위한 연결 리스트
graph = [[] for _ in range(v + 1)]
# 그래프 입력 받기
for _ in range(e):
a, b = map(int, input().split())
graph[a].append(b)
indegree[b] += 1 # 진입차수 증가
# 위상 정렬 함수
def topology_sort():
result = [] # 정렬 결과를 담을 리스트
q = deque() # 큐를 사용
# 처음 시작할 때 진입차수가 0인 노드를 큐에 삽입
for i in range(1, v + 1):
if indegree[i] == 0:
q.append(i)
# 큐가 빌 때까지 반복
while q:
now = q.popleft()
result.append(now)
# 해당 노드와 연결된 노드들의 진입차수에서 1 빼기
for g in graph[now]:
indegree[g] -= 1
if indegree[g] == 0:
q.append(g)
# 결과 출력
for node in result:
print(node, end=' ')시간 복잡도
- 그래프의 노드 수를 V, 간선 수를 E라고 할 때,
- 모든 노드를 확인하는 데 O(V)
- 모든 간선을 제거하는 데 O(E)
- 따라서, 시간 복잡도는 O(V + E) 가 된다.
공부하면서 어려웠던 점
위상정렬의 과정을 직접 그려보며 공부했는데,
그것이 코드를 이해하는데 많은 도움이 되었던 것 같다.
트리의 후위 순회 순서가 여전히 헷갈리는데, 이것도 여러번 손으로 많이 써봐야할 것 같다.

제 Velog에 오신 모든 분들이 작더라도 인사이트를 얻어가셨으면 좋겠습니다 :)