프로그래밍을 시작하면서 배우는 가장 간단한 자료구조중 하나가 큐이다.
큐
특징
큐는 삐뽀FIFO(First In First Out)로 먼저 들어왔던 놈들이 먼저 나가는 구조이다.
참고로 스택은 반대로 LIFO(Last In First Out)이다.
들어온 순서대로 나가는 특성 때문에 보통 BFS탐색, 캐시 등에 쓰인다.
설명
큐(Queue)가 들어온데로 나간다고 하면 일단 들어오는 기능(push)과 나가는 기능(pop)이 기본적으로 있어야 하며 이게 자료구조상 기본적으로 있는 크기(size)와 비어있는지(empty) 체크하는 기능이 있어야 한다.
- push : 큐(Queue)에 데이터를 집어넣는 함수이다.
- pop : 큐(Queue)에 있는 데이터를 가져오는 함수이다(데이터를 가져오면 해당 위치를 다시 접근 할 수 없다.)
- empty : 큐(Queue)에 데이터가 비었는지 들어있는지 확인하는 함수이다.
- size : 큐(Queue)에 데이터의 개수를 확인하는 함수이다.
코드
public class Queue {
private int front, rear;
private int[] q;
Queue(int max){
q = new int[max];
front = 0;
rear = 0;
}
public boolean isEmpty(){
return front == rear;
}
public int size(){
return rear - front;
}
public void push(int data){
q[rear] = data;
rear++;
}
public int pop(){
int data = q[front];
front++;
return data;
}
}
위 코드는 큐(Queue)를 배열을 이용하여 구현했다. 보통 자바에서는 LinkedList라고하는 리스트로 구현 생성된다.
위 코드에서 보면 front와 rear이라는 변수를 사용하고 있다. 이는 큐를 배열을 가지고 구현하게 되면서 각 위치에 인덱스를 담는 변수이다.
front는 큐의 가장 앞이라는 말이다. 따라서 이제 나가야할 데이터를 가르키는 인덱스이다.
rear는 큐의 뒤쪽을 가르키며, 데이터가 들어올 곳을 가르킨다.
참고로 데이터 초과 및 비어있는 부분에서의 예외처리는 안했다.
push
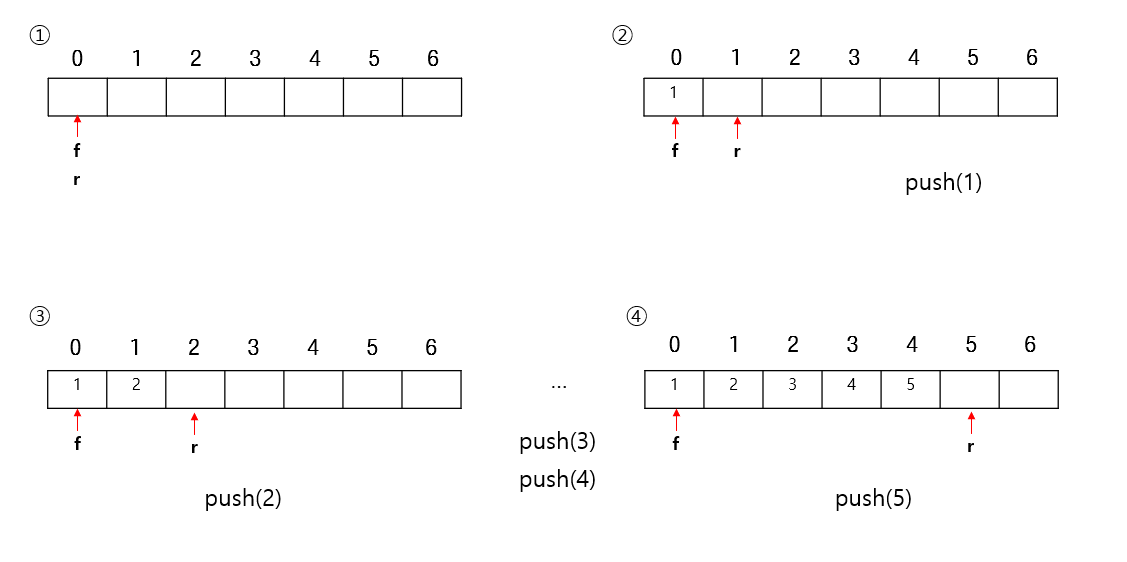
push를 이용해 데이터가 들어오면 rear위치에 데이터를 집어넣고 rear를 +1한다.
pop
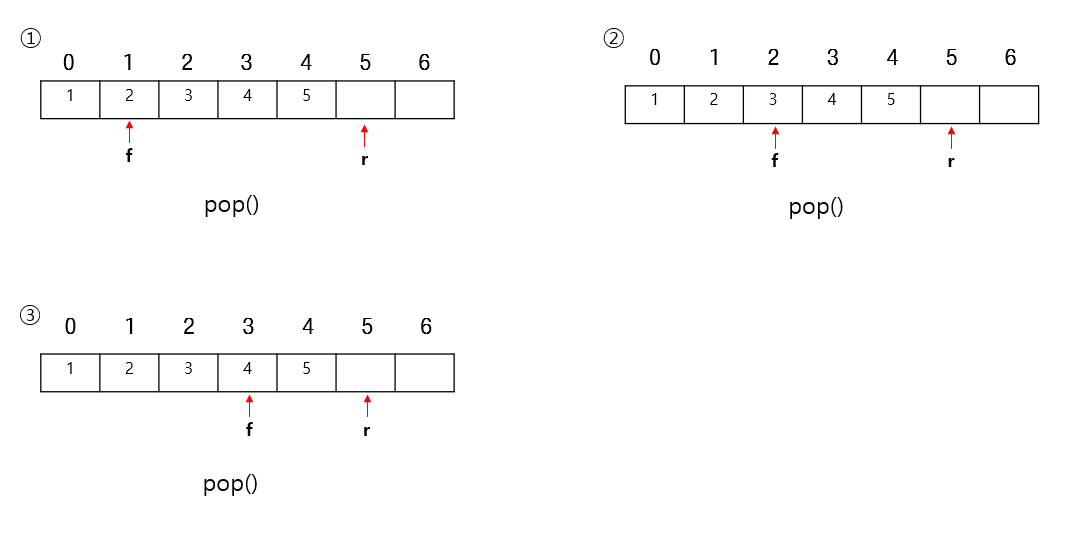
큐(Queue)에서 데이터를 빼낼 때는 front위치에 있는 값을 가져오고 front를 +1한다.
이때 우리가 보기에는 데이터가 삭제되는거 같지만 사실 존재한다. 더이상 접근하지 못할 뿐 데이터가 존재한다는 말이다. 그러면 이게 좋은 상태일까?
문제점
pop 수행 당시 데이터를 사용하고 해당 위치는 더이상 접근하지도, 사용하지도 않는다. 결국 이는 자원 낭비이다. 계속해서 데이터가 들어와야한다면 더 큰 크기가 필요하며, 버려지는 공간도 계속해서 생길 것이다.
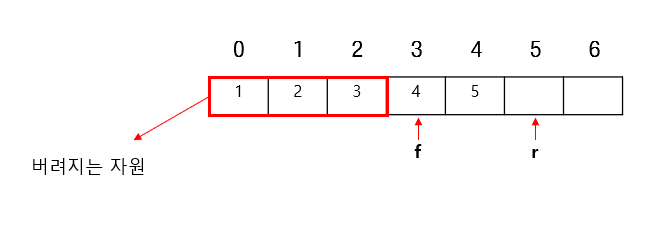
때문에 이를 보완하고자 생긴것이원형 큐이다. 위에서 했던 큐는 선형 큐로, 선형큐의 각 끝의 인덱스를 서로 붙여버린 모양으로 이해를 위해 표현하자면
🍩도넛의 모양을 가진다.
원형 큐(Circular Queue)
위에서 설명한 선형큐의 단점을 보완한 큐이다.
이름에서 알 수 있듯이 표현하자면 원형의 형태를 가진다.
엥 어떻게 보완했지?
선형큐의 단점은 인덱스가 점점 뒤로 밀리면서 앞에 있던 공간을 사용못하고 계속해서 남아있다는 점이였다.
그렇다면 앞에있는 공간을 재활용할 방법만 있으면 된다는것인데 그것이 원형큐가 해결해준다.
설명
일단 기본적인 틀은 선형큐와 똑같다. FIFO의 구조이며, front위치에 데이터를 가져오고 rear에 삽입하는 등의 기능도 똑같다.
다만 다른점이 rear가 계속해서 증가하면 넘어가는 것이 아닌 일정 길이에 도달하면 다시 첫 인덱스로 되돌아 간다는 점이다.
이부분은 rear가 이후에 데이터가 들어올 곳을 가르킨다면, 이 rear가 더이상 안쓰는 공간을 가르키면 데이터를 덮어씌어 다시 사용할 수 있기 때문이다.
그러면 마찬가지로 front도 똑같이 rear을 따라가야한다.
코드
class CirQueue {
int size;
int front = 0, rear = 0;
int[] q;
CirQueue(int size){
this.size = size;
this.q = new int[size+1];
}
public boolean isEmpty(){
return front == rear;
}
public int size(){
if(front > rear){
return (size - front) + rear;
}else{
return rear - front;
}
}
public void push(int data){
q[rear%size] = data;
rear = (rear+1)%(size+1);
}
public int pop(){
int data = q[front%size];
front = (front+1)%(size+1);
return data;
}
}큐와 구조는 거의 비슷하지만 다른 부분이 하나 있다.
기존 rear++ 이 rear = (rear+1)%size로 바뀌고 front역시 바뀌었다.
전체 사이즈에 도달하면 각 인덱스를 맨 처음위치로 되돌리는 것인데 이렇게 한다면 낭비되는 공간을 사용할 수 있게 된다.
마찬가지로 데이터 초과 및 비어있는 부분에서의 예외처리는 안했다.
주의
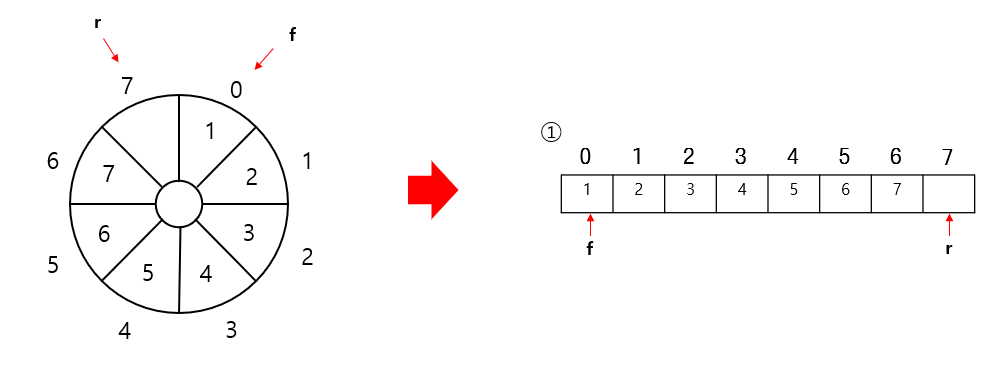
원형 큐라고 했지만 일반적인 배열을 사용하여 구현했다. 때문에 위와 같이 이루어지는데 보면 비어있는 공간이 하나 있다. 이 공간은 원형큐의 치명적인 약점으로 인해 생긴 공간이다.
예를 들어 큐가 가득 차있다고 생각해보자. 그렇다면 rear과 front가 가르키는 곳이 같게 된다.
하지만 rear==front는 큐가 비었는지 안비었는지 확인하는 함수인 empty에서 사용하는 조건문이다.
즉, 데이터가 가득찼는지, 데이터가 비어있는지를 구분할 수 없게 된다는 말이다.
때문에 추가 여유 공간을 하나 주어 rear==front가 오직 비어있는 경우로만 만든다.
push
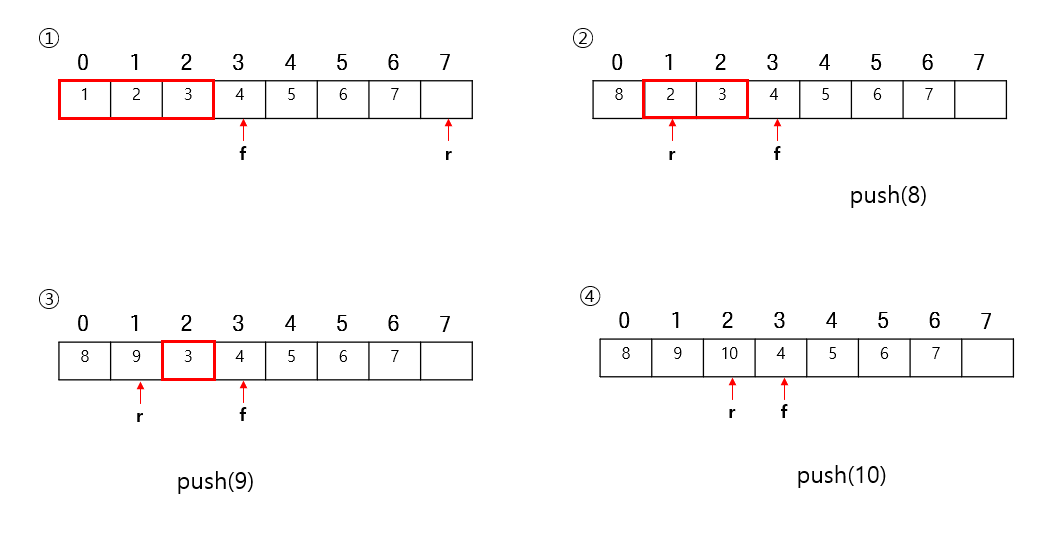
데이터가 들어오고 난 이후에는 %(size+1)를 해서 일부로 빈 공간을 가르키고 이후에 데이터가 들어올 때는 %size로 다시 처음 위치를 가르키게 햇다. 따라서 낭비되는 공간을 rear이 되돌아가서 다시 사용하게 된다.
