이전 포스팅에서는 페이지에서 Json데이터를 받고 이를 가공하여 표시하는 법까지 했다. 이는 서버에서 데이터를 받고 표시할 준비가 되었다는 것인데, 그렇다면 데이터를 보내줄 서버가 필요하다는 뜻이다. 하지만 그전에 데이터를 수집하고 저장하는 부분을 진행하고자 한다.
크롤링(Crawlig)
크롤링은 웹페이지 내에 있는 데이터를 긁어오는 것을 말한다.
그렇다면 크롤링을 왜할까?
원래는 페이지에 있는 데이터를 수집하고자 한다면 직접 페이지에 들어가서 원하는 데이터의 위치를 기억하고 이를 필요할때마다 꺼내다 쓴다. 하지만 이 양이 많아지면 많아질 수록 기록해야 하는 양도 많아질 것이고 피로도 피로데로 쌓일것이다. 때문에 페이지에 있는 내용들을 긁어올 수만 있다면 이를 처리하는 과정은 일도 아니기 때문에 우리는 크롤링한다.
이전에 페이지를 만들었으면 알다시피 웹 페이지는 기본적으로 html의 구조띄고 있는데 이를 크롤링하여 데이터를 가공하여 필요 부분을 쓸 수 있다.
Python
갑자기 파이썬이 나왔는데 이는 데이터를 다루는데 있어서 파이썬이 압도적으로 편리하기 때문이다. BeautifulSoup라는 크롤링 라이브러리도 있기 때문에 이를 사용한다.
변수
파이썬도 프로그래밍 언어이다. 그전에 파이썬은 다른 언어에 비해 매우 편리한데 그중 하나가 이 변수 선언이다.
num = 3
alphabet = ["a", "b", "c", "d"]위 예시처럼 파이썬은 자료형을 쓰지 않아도 된다!
다른 언어에 있는 마침표 역할을 하는 ;도 따로 넣지 않는다. 대신 줄내림으로 이를 구분한다.
숫자, 문자, Boolean
n = 3
s = 'three'
b = True말했듯이 자료형을 따로 명시하지 않아도 데이터를 집어넣으면 해당 데이터의 자료형을 자동으로 띈다.
차례로 문자, 숫자, boolean의 형태로 각 형태에 따라 사용되는 함수가 있기 때문에 현재 어떤 자료형인지는 알고 있어야 한다.
리스트(List)
arr = [2, 3, 1, 5, 4]
arr.append(1) #1 데이터 삽입
arr.remove(5) #5번째 데이터 삭제
arr.sort() #오름차순 정렬
arr[-1] #마지막 인덱스에 있는 데이터
arr[1:3] #1번째 인덱스부터 2번째 인덱스까지의 데이터
arr.clear() #list 초기화
마치 주머니처럼 데이터를 계속해서 집어넣을 수 있는 변수이다.
딕셔너리(Dictionary)
dic = {'name':'김범준', 'age':27}
dic['email'] = 'faulty337@gmail.com'
user = []
user.append(dic)말하자면 각 속성에 맞는 데이터를 보유하고 있는 형태이다. 이를 리스트에 넣을 수 있는데 어디서 본듯한 형태일 것이다. Json이라던가
조건문
if 조건문 :
조건문 내용1
else if 조건문 :
조건문 내용2
else :
조건문 내용3위 예시는 파이썬에서 사용하는 조건문의 구조이다.
타 언어와의 차이점이라고는 괄호로 구분하지 않는다는 점인데 그렇다면 괄호의 원래 기능인 구별을 파이썬에서는 들여쓰기로 한다.
때문에 이 들여쓰기가 파이썬에서는 매우 중요하다.
반복문
for문
arr = [1, 2, 3, 4, 5, 6]
for i in arr:
print(i)반복문중 하나인 for문이다.
사실 python에 for문은 타언어의 for문보다 foreach문에 더 가깝다.
while문
while true:
print('go up')while문의 경우에도 if문과 같게 괄호가 아닌 들여쓰기로 안에 내용을 구분한다.
BeautifulSoup4
줄여서 bf4라고 부르겠다. bf4 라이브러리는 파이썬의 기본제공이 아니기때문에 따로 설치가 필요하다.
아래 명령어를 통해 설치가 가능하다.
pip install beautifulsoup4파이참을 사용한다면
파일 → 설정 → 프로젝트:플젝트명 → Python 인터프리터 → + → bf4입력 → 패키지설치이후
from bs4 import BeautifulSoup로 사용 여부를 명시한다.
import requests #requests를 이용해 응답 요청
from bs4 import BeautifulSoup
# 요청을 보낼 때 브라우저에서 보낸것처럼 해야 하는데 이를 우리는 헤더에 따로 넣는다.
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
url = '크롤링할 url문자열' #이후 이용시 따로 url작성해줘야함
data = requests.get(url,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
print(soup.text)위 코드를 통해 해당 url에 있는 html을 문자형으로 가져 올 수 있다.
url을 'http://naver.com' 으로 작성하여 실행해보면 온갓 이상한 것들이 뜬것을 알 수 있을 것이다.
이는 우리가 이전에 작성했던 태그를 포함한 모든 내용이 다 들어가 있기 때문이다.
때문에 이를 가공하는 방법이 필요하다.
Select
bs4에서 원하는 데이터만을 가져오기 위해서는 해당 태그와 부모자식관계, 클래스이름, id명등을 select에 집어넣어 찾을 수 있다.
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
soup.select('태그명[속성="값"]')위 함수를 사용하여 해당 태그에 포함된 모든 내용들을 가져올 수 있으며 select_one()함수를 이용하여 값 하나만 가져올 수도 있다.!
해당 태그 가져오기
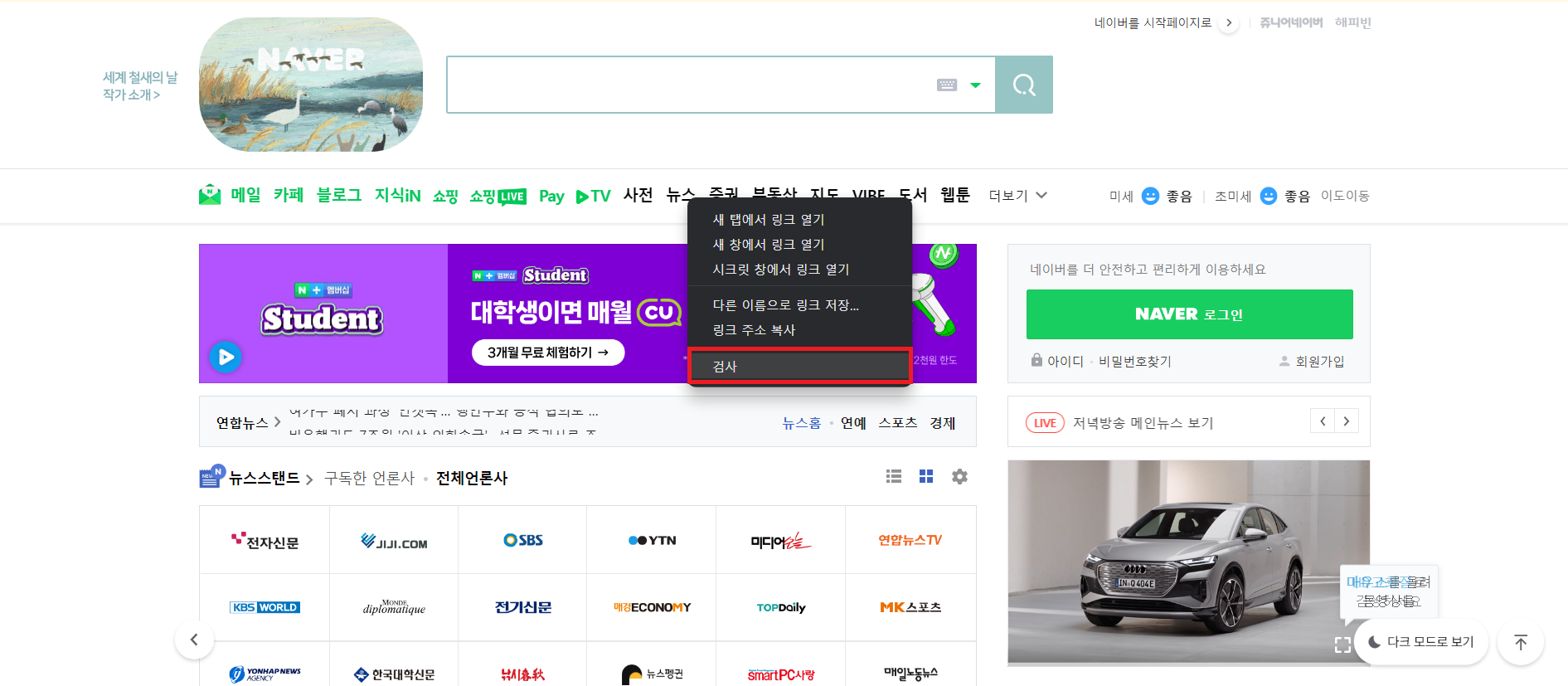
원하는 데이터에 마우스 우클릭후 검사를 통해 해당 데이터의 소스코드를 볼 수 있다.
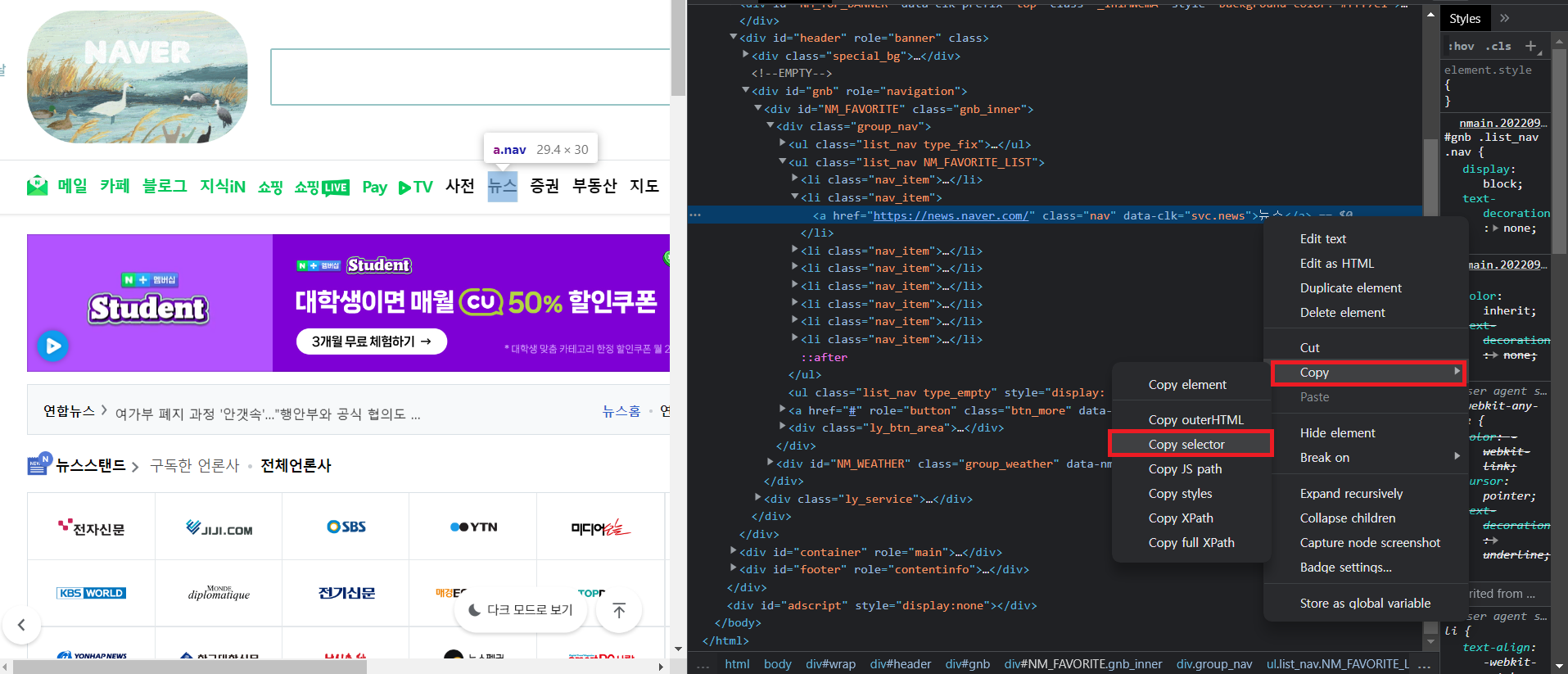
해당 태그에 우클릭 후 Copy → Copy selector 을 통해 해당 태그의 위치를 복사 할 수 있다.
이후
soup.select_one('#NM_FAVORITE > div.group_nav > ul.list_nav.NM_FAVORITE_LIST > li:nth-child(2) > a'select_one()함수를 이용해 해당 태그를 가져올 수 있고 text를 이용해 해당 태그에 있는 text속성만 따로 가져올 수 있다.
예시
지니 뮤직에 있는 랭킹 음악목록 크롤링
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 랭킹
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
# 제목
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
#아티스트
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
songList = soup.select('#body-content > div.newest-list > div > table > tbody > tr');
for song in songList:
rank = song.select_one('td.number').text[0:2].strip()
temp = song.select_one('td.info > a.title.ellipsis')
artist = song.select_one('td.info > a.artist.ellipsis').text
if(temp.span != None) : #.span.extract()을 바로쓰면 span태그가 없는 데이터에서 AttributeError가 남
limit = temp.span.extract().text #extract() 해당 태그를 제외하고 이를 limit에 저장
title = temp.text.strip()
print(rank, limit, title, artist)
else:
title = temp.text.strip()
print(rank, title, artist)DB(DataBase)
흔히 DB라는 말은 많이 들어봤을 것이다. DB 즉, 데이터베이스는 데이터의 조직화된 모음이다. 데이터들이 각 필드에 맞게 레코드로 들어간다.
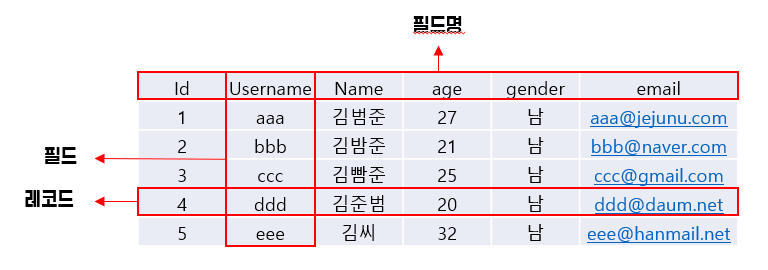
이런 DB는 한개만 존재할 수도 있지만 보토 여러개로 각 데이터에 맞는 DB끼리의 관계를 가지는 것이 보통이다.
이렇게 되면 각 ID에 맞는 값을 따로 검색할 수도, Username에 맞는 값을 검색할 수도 있으, 나이별로 정렬, 나이에 제한을 둬서 검색하는 등 여러 조작이 가능하다.
이를 이용해 우리가 이전에 배운 데이터를 받았을 때의 페이지의 반응에서 정해진 형태로 데이터를 뽑아 가공할 데이터를 저장할 수 있게 되며 이를 걸러낼 수 있게 된다.
여기서 우리가 쓸것은 NOSQL이다.
NOSQL
NOSQL은 NO SQL이 아닌 Not Only SQL이라는 뜻이다. 즉, SQL을 안쓴다는 말이 아닌 이외에 여러 SQL만 쓰는 데이터베이스가 아니라는 말이다.
대표적으로 FireBase, MongoDB가 있는데 여기서는 MongoDB를 다뤄본다.
MongoDB
MongoDB에 Mongo는 humongous(거대한)의 줄임말이다.
이 MongoDB를 Python에 연결하여 진행해볼건데, 그전에 Python에 이 MongoDB와 연결하기 위해서는 이전에 한 BeatifulSoup4에서 했던것처럼 따로 설치가 필요하다.
명령어로는
pip install pymongo파이참에서는
파일 → 설정 → 프로젝트:플젝트명 → Python 인터프리터 → + → bf4입력 → 패키지설치설치가 마쳤으면 MongoDB에서도 생성을 해줘야 하는데 가입이 되었다는 가정하에 진행한다.
MongoDB 생성
-
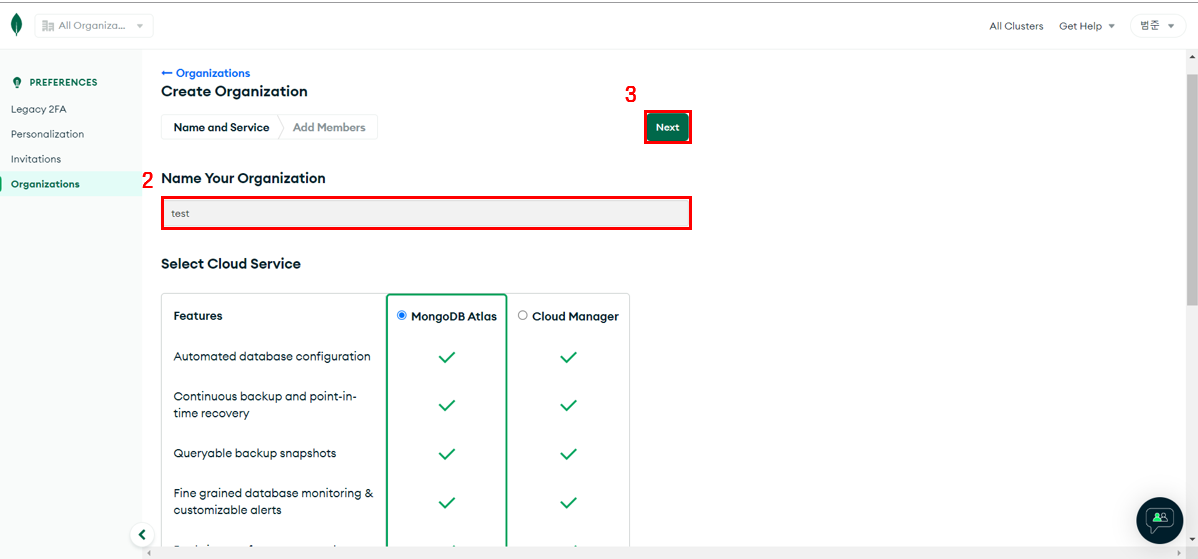
Create New Organization
-
Organization 이름 입력
-
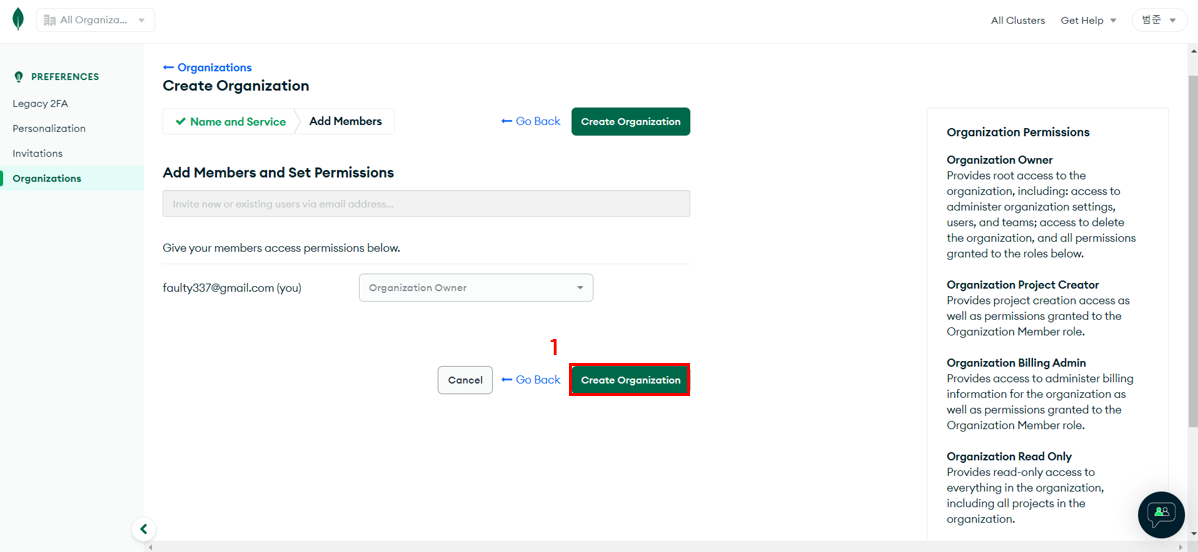
멤버 초대 후 생성(같이할 멤버가 없으면 따로 추가 안해도 된다)
-
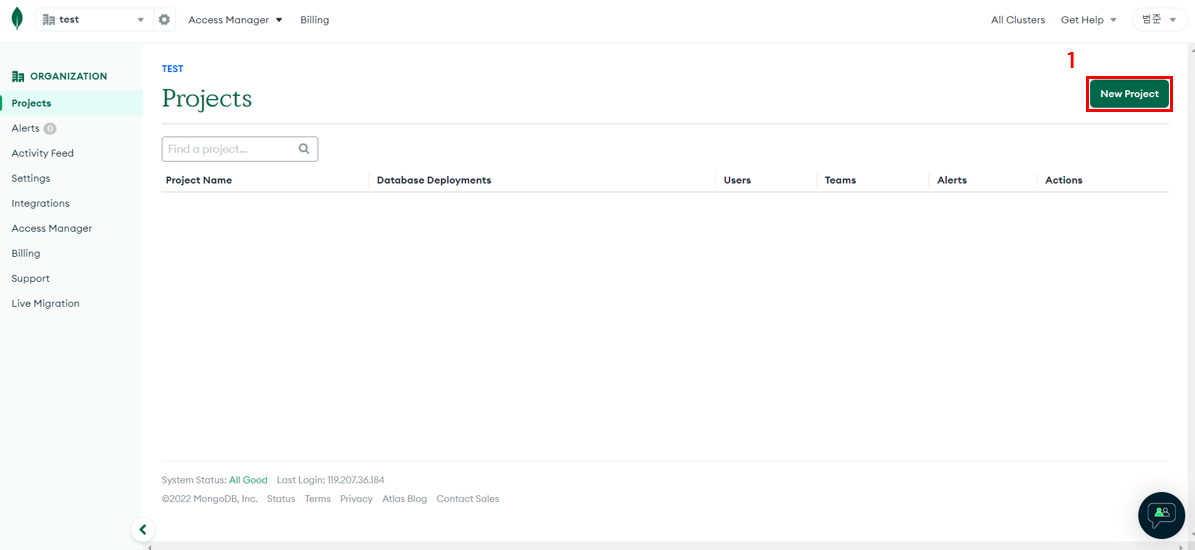
프로젝트 생성
-
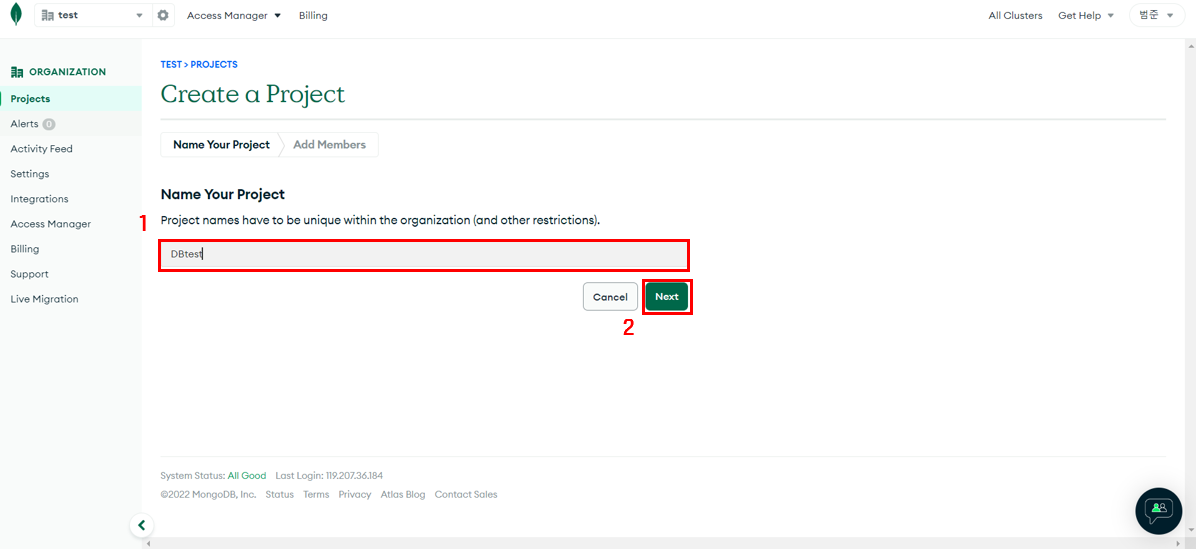
프로젝트 이름 입력
-
멤버 초대 후 생성
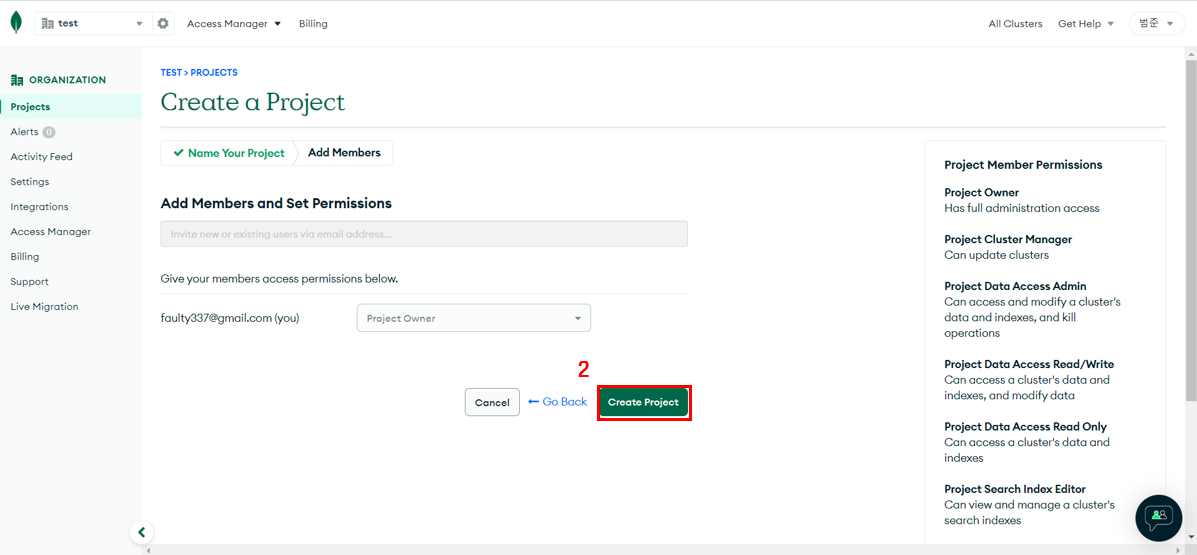
-
DB생성
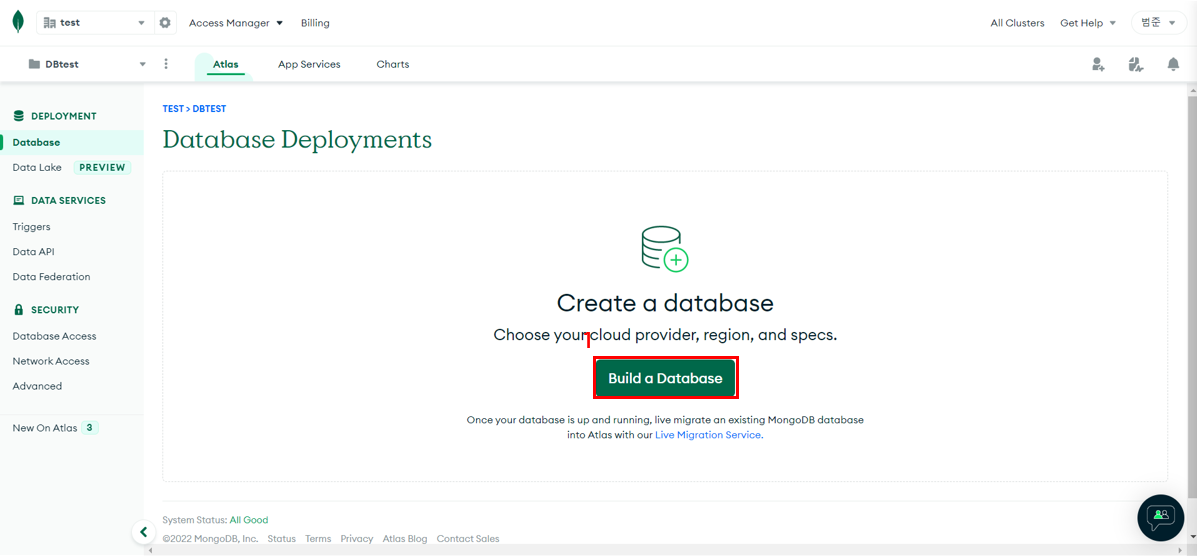
-
요금 선택
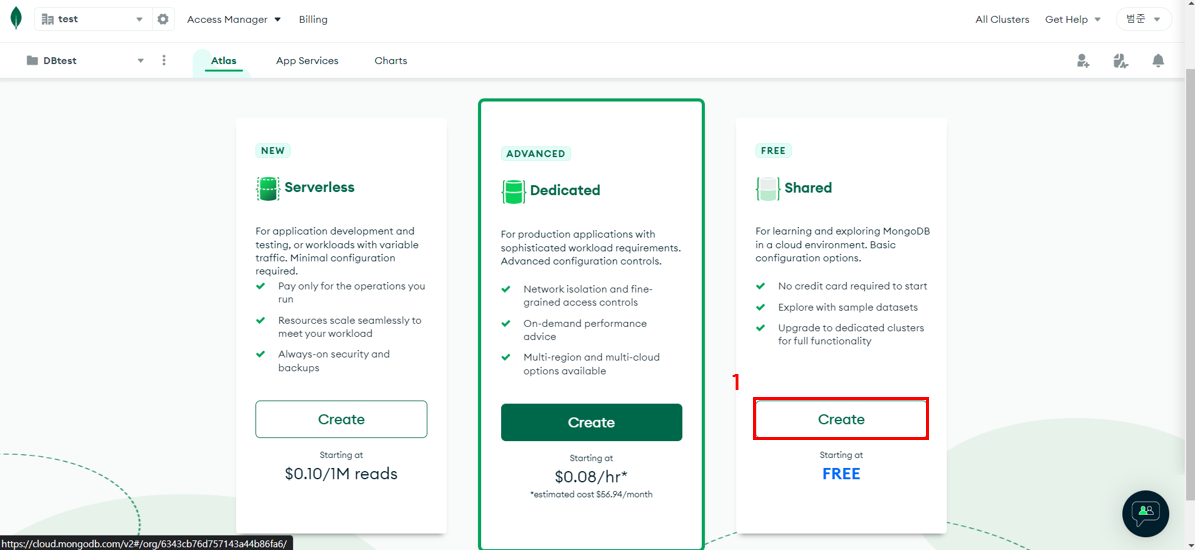
-
서버 선택
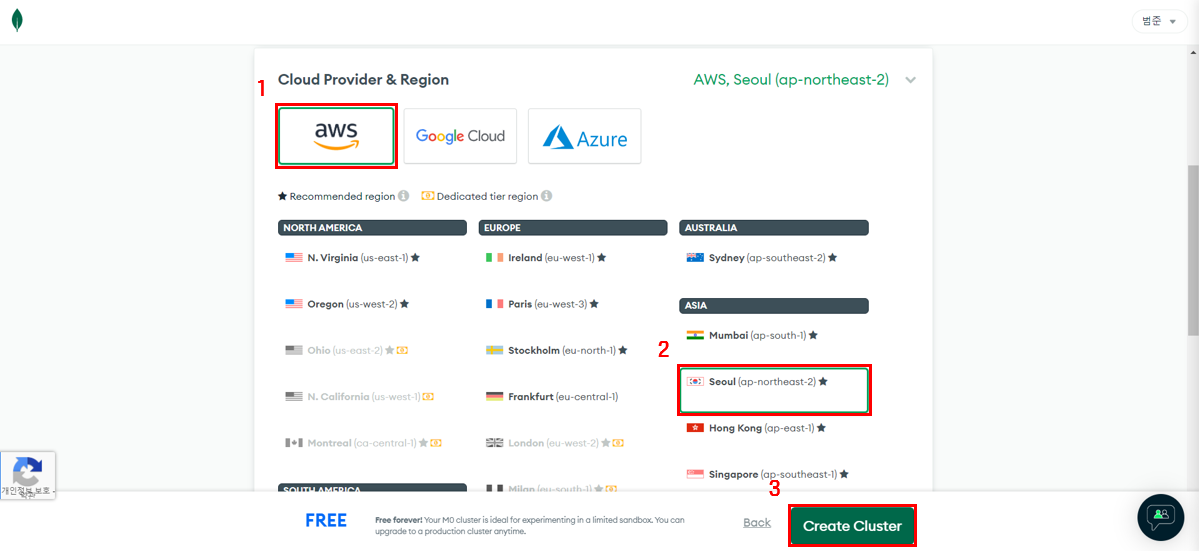
-
Connect 생성
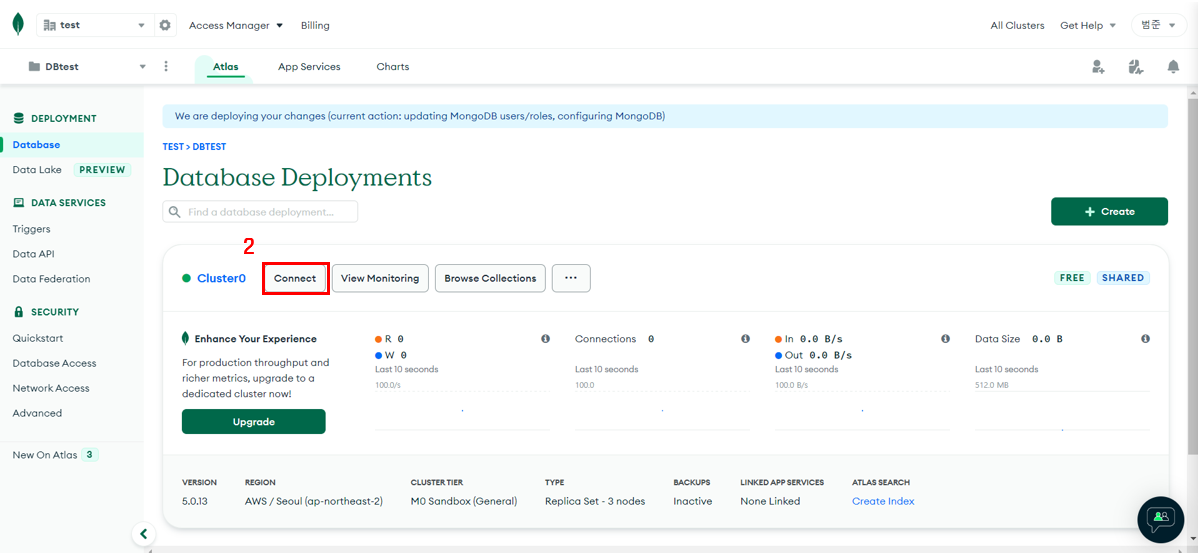
-
어디서든 접근 가능하게 생성한다.
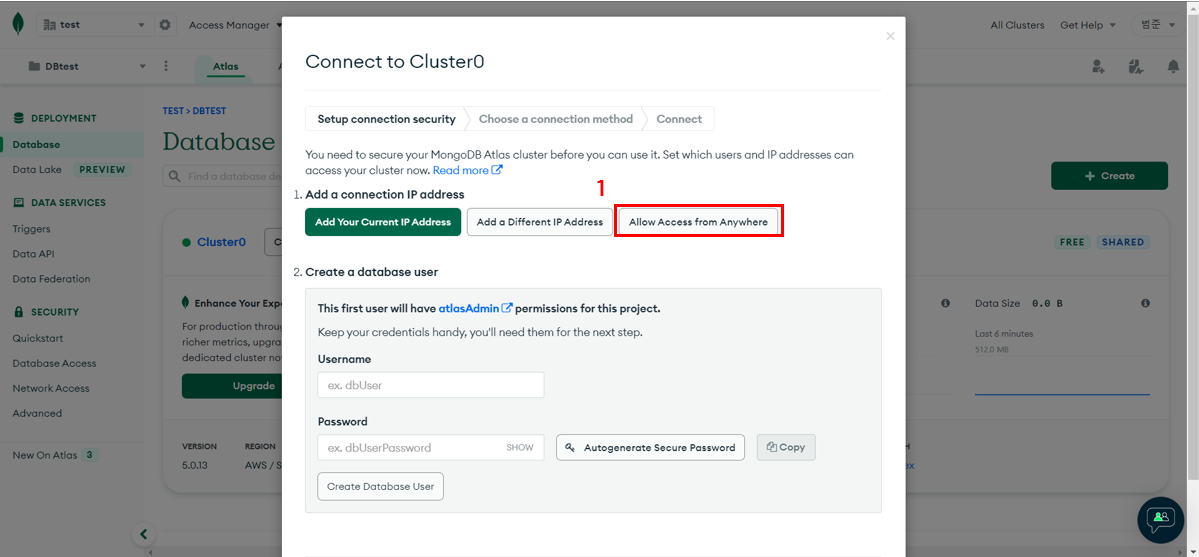
-
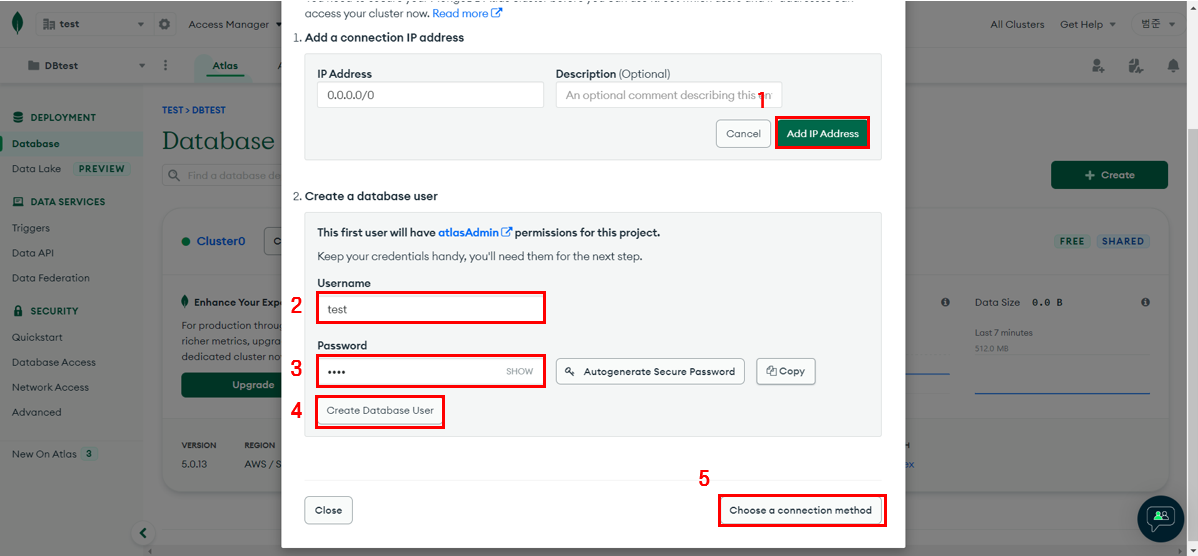
0.0.0.0/0으로 추가하고 접속할 user를 만들어준다.(이는 나중에 접속할 때 써야하니 기억해야한다.)
-
Python을 설정하고 자신의 버전에 맞게 버전을 설정한다. 그리고 저 링크, 저거 때문에 이제까지 이짓을 계속한것이니 저걸 복사하고 닫는다.
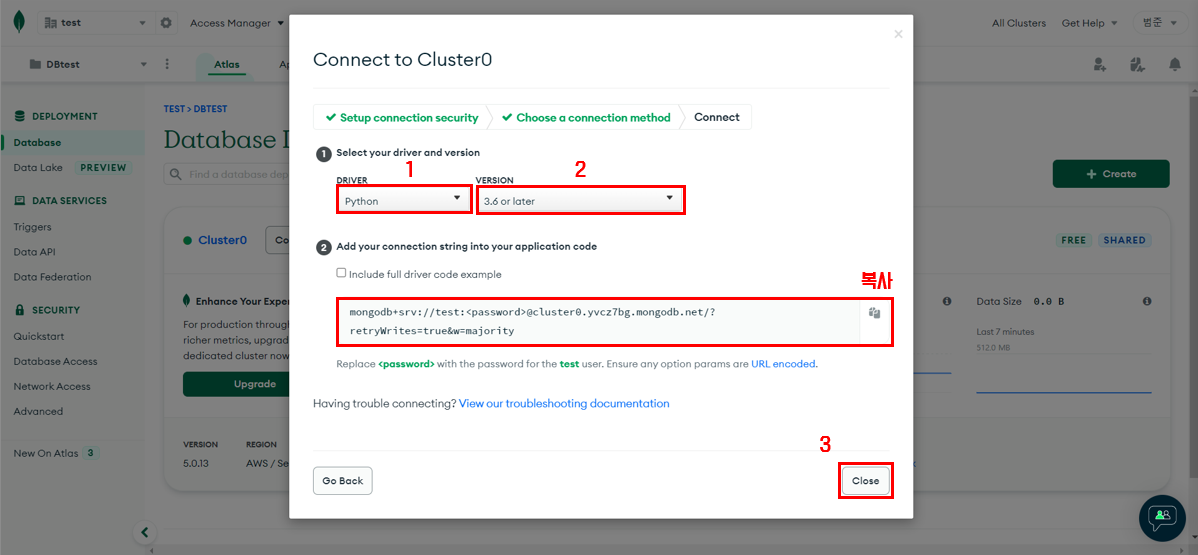
Python과 연결
MongoDB와 연결할 준비가 다되었다. 이제 Python에서 접속하여 데이터를 만져볼 예정이다.
from pymongo import MongoClient
client = MongoClient('mongodb+srv://접속ID:접속비밀번호@cluster0.yvcz7bg.mongodb.net/?retryWrites=true&w=majority')
db = client.NameSpace위 코드는 아래 예시 코드 진행시 꼭 있어야하는 기본 세팅 코드이다 예시에 없더라도 일단 위에 적어놓고 실행하자
여기서 3곳을 바꿔줘야 하는데 위에 보이는 접속ID, 접속비밀번호, NameSpace 이다.
접속ID와 접속비밀번호는 MongoDB 계정이 아닌 우리가 만들 때 입력했던 username과 password이다.
나는 만들당시 test와 1234로 진행했으니 이걸로 바꿔줬고, NameSpace 이름은 알아서 지어서 넣으면 된다.
데이터 저장
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:1234@cluster0.yvcz7bg.mongodb.net/?retryWrites=true&w=majority')
db = client.testDB
doc = {
'name':'김범준',
'age':27
}
db.users.insert_one(doc)데이터에 집어넣을때는 insert_one()함수를 이용하는데 지금 보면 doc의 자료형이 딕셔너리형태라는 거을 알 수있다.
하지만 지금 insert_one()함수 이전에 적힌 users가 있는데 이는 컬랙션이라고 한다.
한마디로 앞에 db는 MongoDB에 접속해 testDB라는 NameSpace를 의미하는 것이고,
db.users.insert_one()는 Users라는 컬랙션에 데이터 doc를 집어넣겠다.
위와같이 작성 후 실행하면 데이터가 Collections에 들어간 것을 알 수 있다.
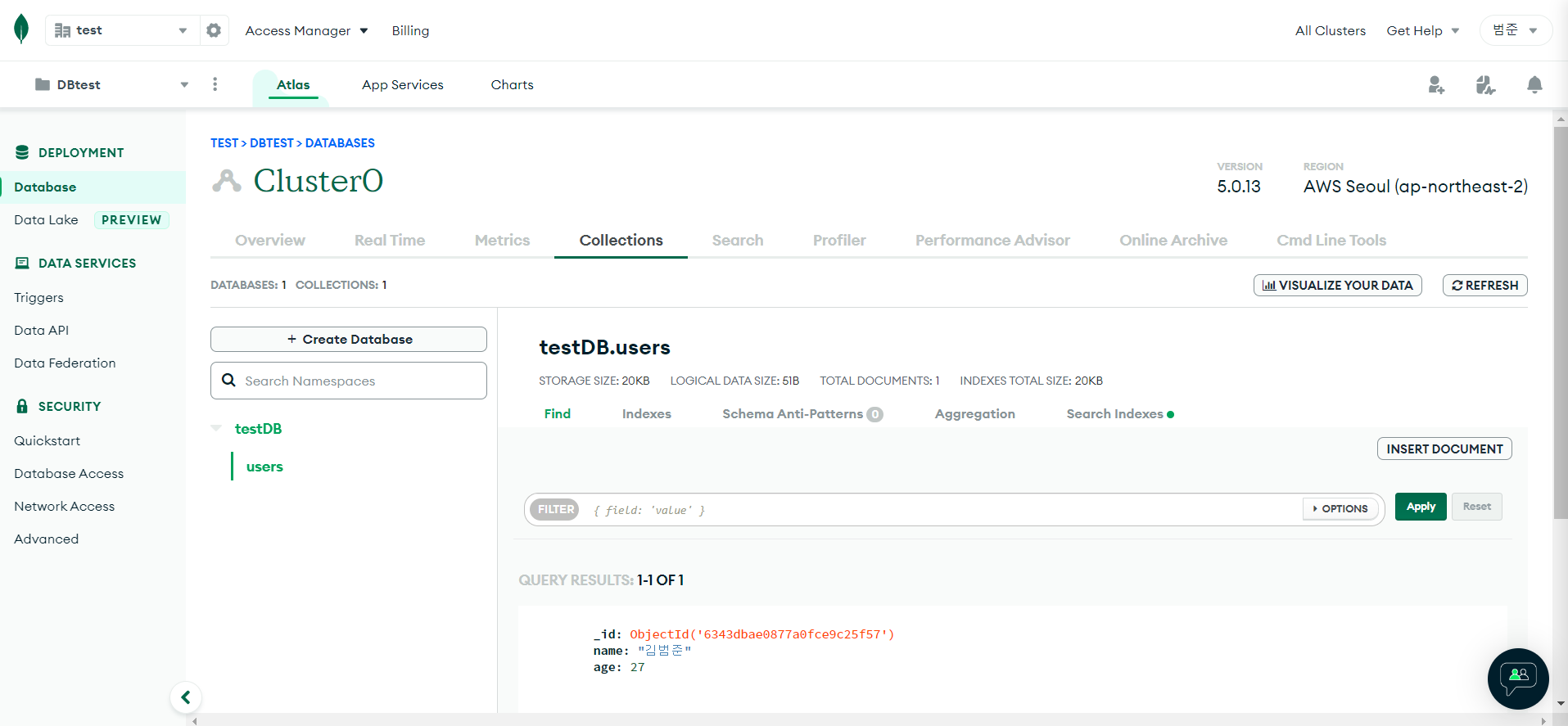
데이터 확인
데이터를 확인할 시 find()라는 함수를 사용하는데 단 한개만 찾을때는 find_one()을 사용한다.
user = db.users.find_one({'name':'김범준'})
userlist = list(db.users.find({}, {'_id':False}))
for u in userlist:
print(u['name'])
print(user)
print(user['age'])집어넣을때 딕셔너리 형태라면 꺼낼때도 딕셔너리처럼 꺼내서 확인하면 되는데 []를 활용하여 안에 우리가 집어넣을 당시 사용했던 키값을 넣어주면 해당 키값에 맞는 값이 나오게 된다.
데이터 수정
db.users.update_one({'name':'김범준'},{'$set':{'age':19}})
user = db.users.find_one({'name':'김범준'})
print(user['age]])데이터 수정은 update_one()를 사용하여 파라미터로 먼저 넣을 데이터, 바꿀 데이터를 지정하여 넣어준다.
데이터 삭제
db.users.delete_one({'name':'bobby'})
user = db.users.find_one({'name':'bobby'})
print(user)삭제의 경우 find_one()함수와 비슷하게 파라미터를 넣으면 해당 조건에 맞는 데이터 하나가 삭제된다.
