이번 포스팅은 GAN에 대한 것입니다.
그래서 도대체 GAN이 무엇인가?
제가 이해한 GAN을 간략히 하자면...
가짜 데이터와 실제 데이터를 통해 여러 가짜 데이터를 생성하는 신경망
입니다.
쉽게 말하자면, 가짜 영상, 가짜 사진(딥페이크)를 예시로 들 수 있습니다.
윤리적인 문제도 거론되고 있는데, 이는 건너띄도록 하겠다.
GAN(Generative Adversarial Network)
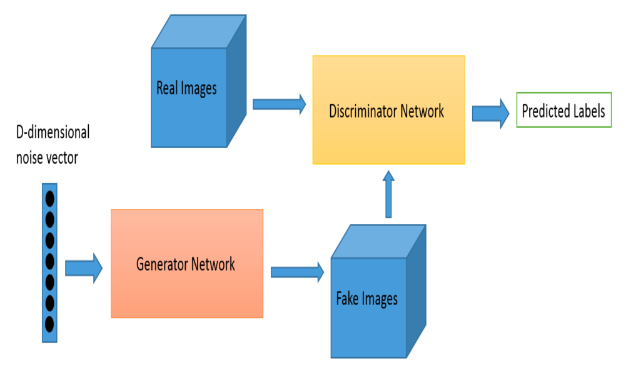
GAN은 일반적인 NN과는 달리, 좀 특이한 형태를 띄는데,
Generator Network, Discriminator Network
이렇게 두개의 네트워크로 구성이 됩니다.
Generator Network(생성기)는 데이터를 넣고, 이 네트워크를 거쳐서 가짜 데이터를 출력하고,
Discriminator Network(판별기)는 이렇게 생성기에서 뽑아낸 데이터와 실제 데이터를 판별, 구별하는 역할을 하게 됩니다.
최종적으로 에측값을 출력하게 되는데,
그래서 이게 어떻게 가능한지? 정리하자면, 아래와 같습니다.
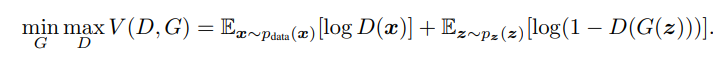
여기서 D는 Discriminator, G는 Generator를 뜻합니다.
D, 그러니까 실제 데이터 x를 입력하게 되면, log값은 커지게 됩니다.
그러면 V(D,G)의 확률값은 커지게 되는데,
여기서 G(z), 가짜 데이터를 입력받게 되면, 앞에 1 - 의 역할 때문에, log값은 작아지게 됩니다.
그래서 D(G(z))의 값이 높다는 것은, Discriminator가 실제 데이터를 판별할 확률이 높다는 것이고,
자연스레 log(1 - D(G(z)))의 값은 작아집니다.
결국 전체 값 즉, V(D,G)의 값은 자연스레 감소하게 되고,
이는 Generator 훈련이 잘 되어서 Discriminator를 더 잘 속이고 있음을 의미합니다.
GAN을 찾아보면, 어떤 균형점, 게임, 싸움 이라는 표현이 나오는데, 이는 두 데이터, 즉 가짜 데이터, 실제 데이터 사이의 계산 과정을 거쳐 위와같은 확률값이 나오기 때문에 그렇습니다.
가짜 이미지가 실제 이미지를 얼마나 잘 속이는지에 대한 확률값을 도출하기 때문에, 0.5의 확률값이 가장 이상적인 값입니다.
처음에 일반적인 신경망의 정확도 개념을 생각했을 때, 이해가 가지 않았다. 참 신기한 개념이다.
cGAN(Conditional Generative Adversarial Network)
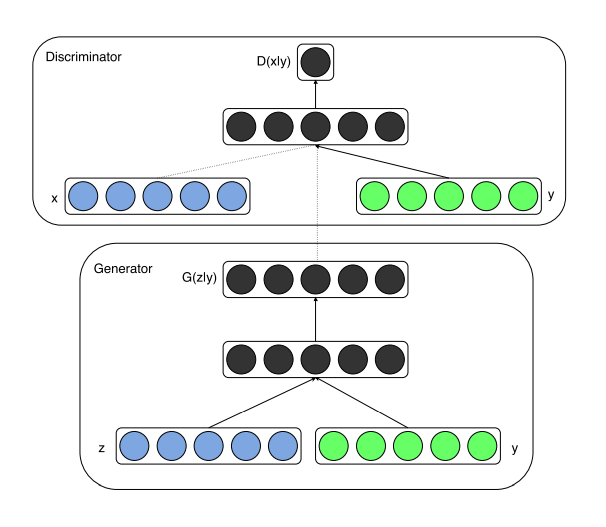
위에서 나왔던 GAN과 비슷한 개념의 cGAN이라는 것도 있습니다.
좀 특이한 차이라고 하면,
GAN의 Generator, Discriminator에 어떤 condition 이라는 것을 붙인건데,
그냥 각각에 어떤 조건을 추가해준 것입니다.
뭐... 뭔말이고
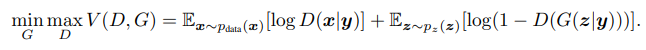
여기서 y는 condition을 의미하고,
예를 들면, 논문에서는 원핫 인코딩을 거친 데이터를 Generator에 넣었는데,
이 원핫 인코딩을 거친 과정이 y를 뜻하게 됩니다.
쫌 거창한건 줄 알았는데, 조건이 그냥 전처리 해준, 이런걸 의미하는 거였다.
감사합니당 ~ 🦾
참고자료
https://arxiv.org/pdf/1406.2661.pdf
https://arxiv.org/pdf/1411.1784.pdf
https://pseudo-lab.github.io/Tutorial-Book/chapters/GAN/Ch1-Introduction.html
