Approach

이 연구는 실제 input이미지, output 사이의 pixel당 loss값을 최소화 하는 CNN 훈련 방식에 흥미를 느껴서 진행된 연구입니다.
물론 접근 방식은 조금 달랐다 ㅎㅎ
여기서 feed-forward convolution 에서 optimization 해줄때, 실시간으로 문제가 생기는 style transfor 이야기와 초고해상도 복원 방식에 대한 이야기가 나옵니다.
전에 포스팅 한거 공부할 때 이것저것 찾아보다가 여기까지 와있었다
연구 결과를 보면, 이 시점(2016년이었나?)까지 나온 최적화 기법에 비해 3배 빠르고,
손실값들에 대한 파악을 확실시 할 수 있는 방식은 이미지 결과물이 더 좋게 나온다고 합니다.
말이 이상한데, 본인들의 연구 방식이 손실값 파악이 명확해서 이미지 결과물이 더 좋았다.라고 이해하면 된다.
Introduction
옛날부터 내려온 문제는 저해상도 이미지를 고해상도 컬러 이미지로 변환할 때 부터 나왔습니다.
supervised한 순방향 NN(가장 기초적 신경망) 에서는 픽셀마다의 output이미지와 실제 이미지 사이의 손실값을 측정해서 이미지 변환 문제를 해결합니다.
하지만, 이 이미지는 per-pixel의 실제 이미지, output이미지의 명확한 파악이 불가능합니다.
그래서 요새는 픽셀 별 차이가 아니라, 두개의 이미지 표현에 있어서 이 두개의 차이에 기초한 Loss 함수를 사용합니다.
예시로, 특징 반전, style transfer가 있는데, 결국 이 방식도 최적화에 있어서 속도가 매우 느리다고 합니다.
그래서 이 연구에서는 이 per-pixel방식, 이전의 두 이미지 사이의 loss값 측정 중에서 좋은 점만 가지고 와서 연구를 진행했고, 고퀄리티 feature의 판단 가능한 Loss들을 훈련에 사용했습니다.
그리고,
style transfer에서는 Semantically하게(픽셀들 집합체 여러개 나눠놓은 것)하게 input 이미지와 확연하게 달라야하고, detail한 모든 정보까지 고려해야 합니다.
그냥 쭈욱 본인들 연구 대단하다, 복원 영상, 이미지 변환 결과도 진짜 대박이다, 뭐 이런 이야기 쭈욱 있었다.
Related work
Feed-forward image transformation
semantic segmentation 방식은 밀도 높은 장면 Label을 생성합니다.
결국 이것도 픽셀마다의 손실값을 훈련하는 방식이고,
여기서의 연구는 계층 내에서 다운 샘플링으로 크기를 줄이고, 업 샘플링으로 최종 이미지를 출력합니다.
Perceptual optimization
최근 연구에서는 최적화를 통해서 고퀄리티의 이미지를 뽑아내고 있다고 합니다.
그래서 이 친구들도 썼다는 거겠죠?
이 방식은 실제로, 참 많은 도움이 되는데,
클래스 prediction 점수, 개별 feature 최대화 하는 이미지를 생성 가능 하다는 내용이 적혀 있었습니다.
말이 참 어려운데, 그냥 한마디로 각 이미지마다의 세부 정보 뽑아내는 것이 가능하다 정도로 알아들으면 될거 같다.
이전까지, 이미지 정보를 알기 위해서 Network 특징을 반전(추출된 것을 입력 이미지로 되돌리는 것)시키는 방법도 나왔고, feed-forward 훈련 방식도 나왔는데, 이 연구는 feature 재구성 손실을 직접적으로 최적화 하는 방식을 사용했습니다.
Style Transfer
이 친구들 참고 자료인데, Gatys style transfer 연구는 feature 재구성 손실값과 style 재구성 사이의 손실값을 최소화 하는 방식으로 접근했지만,
이 방식은 최적화 할 때, forward와 backward pass가 필요로 해서, 계산량이 매우 많은 문제가 있다고 합니다.
그래서 이 친구들은 feed-forward Network를 훈련시키는 방법을 사용했습니다.
그냥 단순한 신경망 하나 구성했다를 왜이렇게 구구절절하게 말할까 ㅎㅎ
Image super-resolution
prediction-based methods, edge-based methods, statistical methods, patch-based methods, sparse dictionary methods 라는 것을 소개하고, 평가지표를 위해 위의 친구들을 참고했다고 합니다.
자세한건 찾아보세요.
Method
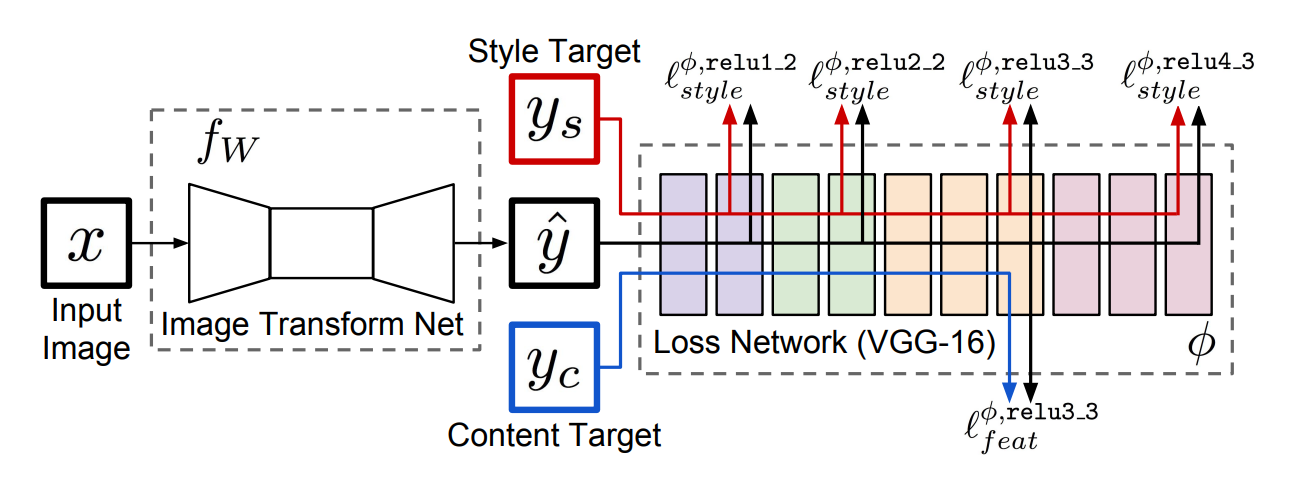
이 파트에서는 위 그림을 설명했습니다.
여기서 y_c는 입력 이미지 x, y^은 y_c의 내용, y_s의 스타일을 결합해야 한다고 합니다.
여기서 전체 흐름은 x를 이미지 변환 Net, 즉 f_w를 거치면 y^을 출력한다는 말입니다.
그래서 이 y^, y_s, y_c들이 φ 라는 Loss network에 들어가게 된다는 내용입니다.
초반에 그림만 뜬금없이 나와서 뭐지? 했는데, 뒤에 설명이 다 있었다.
Image Transformation Networks
pooling계층은 따로 없고,
stride기법으로 다운 샘플링, fractional strided convolution으로 업 샘플링을 해주었습니다.
총 5개의 블록으로 계층 구성이 되어있고, 여기에 안 들어가 있는 건 전부 batch Norm과 ReLU함수를 사용했습니다.
출력 layer만 tanh함수, 첫 계층, 마지막 계층은 9 x 9커널 사이즈, 나머지는 싹다 3 x 3 커널 사이즈를 사용했습니다.
Inputs and Outputs
입출력 모두 3 x 256 x 256 컬러 이미지이고, 입력은 3 x 288/f x 288/f 저해상도 이미지를 입력으로 넣고, 이렇게 내부에서 업 샘플링 작업이 뚝딱뚝딱 이루어지면, 3 x 288 x 288 이미지를 출력하게끔 했습니다.
Downsampling and Upsampling
이 파트에서 그간 궁금했던 다운 샘플링, 업 샘플링 활용 이유에 대해 나옵니다.
두근두근 ㅋㅋ
업 샘플링 요소 f 에서는 residual block들 지난 다음에, stride 값 1/2 가진 log2(f) convolution layer를 사용했습니다.
style transfer의 경우, stride값 2인 계층 2개 썼고, 그 다음에 위랑 똑같이 residual block 거치고, stride 1/2값 넣은 계층 2개로 업 샘플링을 했습니다.
stride쓴 계층이 다운샘플링 파트.
굳이 이렇게 까지 힘들게 해주는 이유는,
계산량이 좀 줄어들 뿐 아니라, 출력 이미지의 각 픽셀값들이 입력 이미지의 어느 부분에 더 큰 영향을 받는지, 이게 파악 가능해서 이렇게 굳이굳이 해주었습니다.
Residual Connections
여기서는 위에 residual 사용 이유에 대해 말을 했습니다.
이 Residual connection이 identity function 학습을 더 쉽게 하게끔 하는데,
이게 transfer에 까지 갖고 오게 되면, 출력 이미지와 입력 이미지가 서로 공유해야하는 구조 때문에, 이 개념을 갖고 왔습니다.
Perceptual Loss Functions
여기서는 전에 φ라고 정의된 loss 네트워크를 이 연구의 두가지 관점에서 설명을 했습니다.
Feature Reconstruction Loss
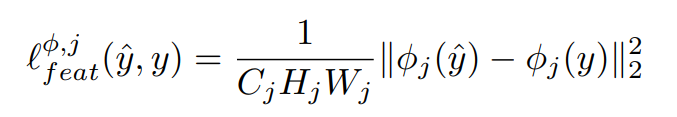
출력 이미지를 y^ 이라고 두고,
j가 convolution 계층이라고 하면, 손실 네트워크를 거친 전체 값을
C_j x H_j x W_j = φ_j(x)라고 할 수 있습니다.
손실값은 유클리디안 거리로 측정했다고 합니다.
물론 이게 정확하게 일치하지는 못하다고 한다.
Style Reconstruction Loss
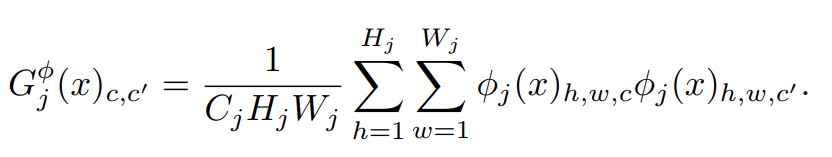
위랑 비슷한 구조인데,
출력 이미지 y^이 y(입력 이미지)에서 벗어나면 패널티를 부여하는 구조 입니다.
여기서 쓰는 식은 Frobenius norm이라는 것인데,
L1, L2와 다르게 Matrix 구조에 적용 가능한 식이다. 근데 결국 일렬로 늘여뜨려놓고 보면 L2와 똑같은 식이다.
여기서 중요한 점은, 공간 전체를 보존하는 느낌이 아닌, 스타일 적인 요소만 보존하는 느낌이라는 것입니다.
Simple Loss Functions
여기서는 Loss 측정 함수에 대해 정의를 했습니다.
Pixel Loss
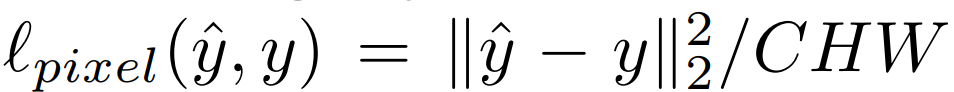
픽셀 정보만 갖고도 손실값 측정이 가능한데,
y^과 y 사이의 loss값 측정은 유클리디안 식을 갖다가 썼습니다.
만약에 두 Data가 이미지 데이터라면,
위 식을 적용하면 되는데,
C는 채널 수, H는 이미지 높이, W는 width를 뜻합니다.
이 방식은 아쉽게도 target y값이 존재할때만 가능하다.
Total variation Regularization
y^의 smooth함을 위해서 'total variation regularizer' 라는 것을 갖다가 썼다는데,
간단히 찾아보고 정리해보면,
'이미지의 인접한 픽셀간 차이 합을 나타내는 방법 중 하나'
라고 할 수 있습니다.
그래서 그냥 이런걸 갖다가 측정했다~ 라는 정도로 이해하고 넘어갔다.
Experiments
여기도 반복되는 말, 'style transfer', 'super resolution' 이렇게 두가지 실험을 했다~ 의 내용입니다.
per-pixel loss가 아닌, 인지 가능한 loss를 사용하는 feed-forward방식 덕분에 3배정도 빠른 속도를 보였다고 합니다.
Style transfer
Baseline:
gatys 방식에 대한 설명이 나왔는데, 이것을 baseline으로 잡았습니다.
이 방식은 레이어 i,j가 주어지면, y^은
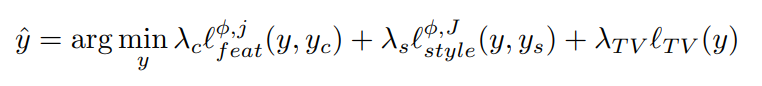
의 식을 해결하면서 생성됩니다.
여기서 y는 흰색잡음(random하게 생성된 픽셀값)으로 초기화되고,
최적화(optimization)은 L-BFGS를 사용하였습니다.
L-BFGS는 규모가 큰 최적화 문제를 해결해주는 반복적 최적화 방법이라고 한다.
입력 이미지 y를 [0, 255] 범위로 조정하고, L-BFGS를 사용해서 계산을 최소화 합니다.
근데 결국 이것도 forward, backward pass 방식이 필요해서 느리다는 단점이 있다고 합니다.
그래서 이 단점을 보완하는 방식으로 연구를 진행했다는 거겠죠? ㅎㅎ
Training Details:
MS-COCO 데이터셋을 사용했고, 80000개 이미지를 256 x 256 사이즈로 조정.
40000번 반복동안 batch_size 4로 훈련했습니다.
Adam optimization을 사용, total variation regularization 로 규제를 했습니다.
total variation regularization은 인접 픽셀간의 차이, 이미지 변동성을 최소화 한다는 것인데... 이해 못했다. 그냥 넘어가자.
Loss Network φ에서 feature, style transfer loss값을 계산하고, 훈련은 GTX Titan X GPU상에서 4시간이 걸렸다고 합니다.
Qualitative Results:
모델이 256 X 256 이미지로 훈련되었지만, 실제 테스트에서는 어느 사이즈이든 다 적용 가능하고,
위의 그림처럼, 일부 이미지는 기존 방식과 비슷한 결과를 보여주지만, 일부 이미지는 또 반복적인 패턴이 더 많이 보입니다.
Quantitative Results:
baseline 잡은거로 함수 계산(baseline 식)을 최소화 하려고 했습니다.
baseline 방식은 출력 이미지에 대한 최적화에 있어서 직접적인 느낌의 접근법을 보여주었지만,
이 연구는 single forward pass 방법으로 어떤 이미지든 다 받아들일 수 있도록 훈련했습니다.
그래서 결국 Qualitative, Quantitative에서도 baseline을 뛰어넘었다로 요약할 수 있다.
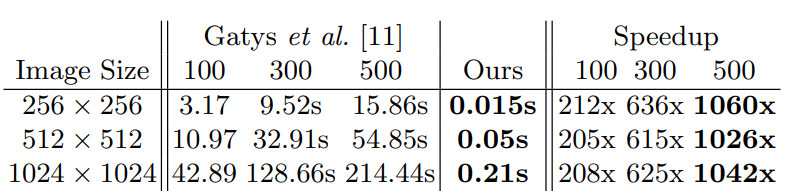
속도도 참 많이 빨라졌습니다.
Single-Image Super-Resolution
배율이 커지면 커질수록, 저해상도 버전의 이미지에서 특징을 찾기 힘듭니다.
그래서 이 연구는 픽셀별(per-pixel) loss 대신에 feature reconstruction 손실로 학습합니다.
즉, 이렇게 하면 입력 이미지의 더 큰 추론이 필요한 요소에 초점을 맞출 수 있게 됩니다.
이 연구에서의 평가는 PSNR, SSIM은 픽셀별 손실값에 어울리는 측정법이기 때문에, 따로 이 지표를 갖다가 쓰지는 않았고, qualitative difference 차이를 보여준다고 합니다.
PSNR, SSIM에 대한 내용은 전의 포스팅 찾아보세요 ㅎㅎ
Model Details:
X4, X8 초고해상도를 위해 Loss 네트워크에서 relu2_2계층에서 feature 재구성 loss값 최소화 해서 모델 학습시켰습니다.
MS-COCO 데이터의 10000개의 288 x 288 패치를 써서 학습하였고,
학습은 총 200000회 반복 수행하였습니다.
BaseLine:
per pixel 손실 최소화한 계층 3개의 CNN 네트워크인 SRCNN을 기준으로 잡았습니다.
X8 초고해상도에 대한 학습은 안돼서 X4에 대해서만 평가했다고 합니다.
Evaluation:
Set5, Set14, BSD100 데이터셋으로 평가했고,
여기서는 image transfer와 다르게 PSNR, SSIM 지표를 썼다고 합니다.
Set5, Set14, BSD100 데이터셋은 여기서 처음 들어봤는데, 적은 수로 이루어진 초고해상도 이미지 데이터셋이라고 한다.
Results:

먼저 그림에 대해서 간단히 설명하자면,
가장 왼쪽 그림은 원본 이미지, 그리고 각각의 방식으로 복원된 이미지들 입니다.
왼쪽 숫자는 PSNR, 오른쪽 숫자는 SSIM을 뜻하고,
PSNR은 이미지 품질 측정하는 값, 즉 높으면 높을 수록 복원이 매우 잘된거고,
SSIM은 밝기, 대비 차이를 측정하는 값, 즉 1에 가까우면 가까울 수록, 이미지가 더 유사한 것입니다.
가장 오른쪽 모델은 그림에서도 보이듯이, 가장자리가 선명하게 잘 나온것을 알 수 있습니다.
이는 세부 정보를 재구성하는데 매우 효과적이라는 뜻을 가지고 있습니다.
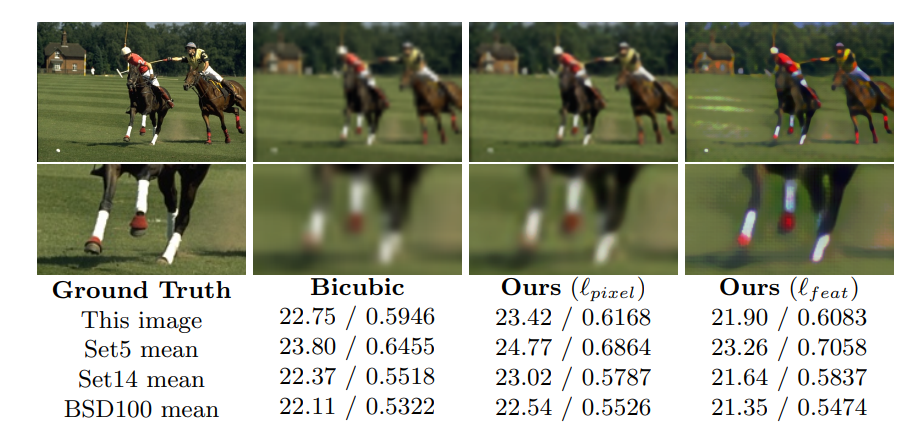
여기서도 마찬가지로, 가장 오른쪽 모델의 결과가 가장 잘 나왔는데,
쫌 뿌연 부분이 마음에 걸립니다.
이는 외곡된 것이다.
예, 그냥 성능이 쫌 떨어지는 결과물을 보여준 것입니다.
그래도 이 모델이 가장 가장자리 부분과 세부적인 정보는 잘 뽑아내는 것 같습니다.
감사합니당 ~ 🦾
자료
https://cs.stanford.edu/people/jcjohns/papers/eccv16/JohnsonECCV16.pdf
