MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications - Approach 2nd
딥러닝
저번 MobileNet 글에 이어서 쭉 가겠습니다.
Test & Validation
일반적인 Convolution(분리 안하는)과 이 MobileNet처럼 Depthwise Seperable Convolution(분리 했을 때)의 차이는, 정확도는 아주 미세하게 줄어들었지만, 연산량과 Parameter 값은 대폭 감소했다는 것입니다.
대부분의 Network는 layer 몇개를 없애는 방식을 택했지만, MobileNet처럼, thinner하게 만드는 방식이 3% 정도 더 나은 성능을 보여줬습니다.
더 thinner 하게 만들기 위해, 대부분의 Net에 들어가있는 필터층을 제거했다.
(14 x 14 x 512) * 5 filter layer 제거.
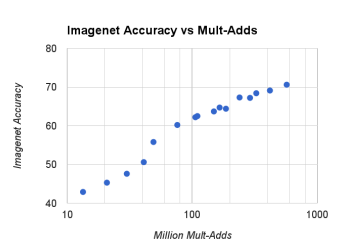
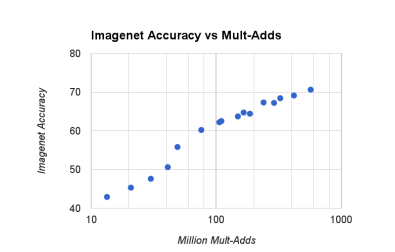
위의 그래프는 이전 포스팅의
width multiplier α와 resolution multiplier ρ의 trade off를 보여줍니다.
그래프를 보면, α값이 0에 가까워 질 때, 정확도가 매우 Linear 하게 서서히 감소하는게 보입니다.
그만큼, α 규모를 줄였다고 정확도가 그만큼 대폭 감소하지 않아,
참 좋은 Network라고 그래프를 통해 설명 하고 있습니다.
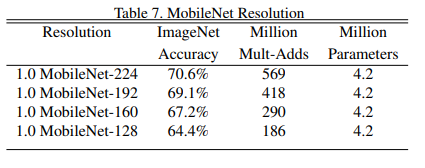
또한 위 table은 resolution multiplier ρ 값의 차이를 말하는 것인데,
ρ 값이 감소함에 따라 연산량이 점점 줄어드는 것을 확인할 수 있습니다.
정확도는 연산량 감소에 비해 아주 조금씩 줄어드니 이정도면 괜찮은가 보다.
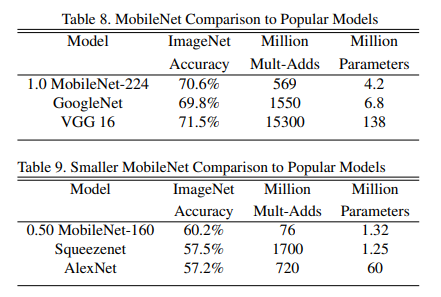
그리고 GoogleNet과 VGGNet-16, SqueezeNet, AlexNet의 비교를 볼 수 있는데, 또 이만큼의 이점을 갖고 있다는 것을 table을 통해서 보여주고 있습니다.
여기서 주목할 부분은 α 입니다.
위의 표는 α값이 1.0, 아래 표는 0.5로 조정하였는데, 규모를 작게해도 유명 Model을 뛰어넘었다는 것을 확인할 수 있습니다.
How to use DataSet
Stanford Dogs Dataset을 사용했다고 하고,
웹 상에서 Noise큰 trainset 수집 후, 이걸 사용해서 pretrain,
그리고 Stanford에서 뿌린 강아지 데이터셋을 사용해서 Finetuning 했다고 합니다.
이 부분 읽으면서 처음에 Noise 큰 데이터로 학습했다는 것에 좀 놀랐는데, 이렇게 하면 모델이 좀 더 견고하게 되고,
애초에 Labeling 안된걸로 데이터 막 때려박고 학습하더라도,
어쨋든 이걸로 초기 가중치 값은 가질 수 있으니,
잘 만들어진(쓰기 편한) 데이터셋이 그렇게 많이 없을 때,
참 효율적인 방법이라고 합니다.
어쨋든 이것도 대규모 작업을 거쳤구나 하는게 느껴진다.
그리고 face classification에서 75만개의 parameter값과 16억 연산량 가진걸 축소합니다.
이 classifier는 YFCC100M와 유사한 데이터셋으로 train 했다고 합니다.
유사한? similar라는 표현이... 참 애매하다
여기서 주목할 부분은 distillation(증류) 기법입니다.
이는 크고 복잡한 model 에서 더 작은 model로 값들을 전달하는 기법인데,
이 Network에서 이 방식을 들여와서 매우 크고 Label 없는 데이터셋에서의 Train도 가능하게 했습니다.
이 distillation train 방식,
그리고 MobileNet의 parameter 획기적 감소 방식을 sum 해서
최종적으로 regularization과 early-stopping도 필요 없다고 합니다.
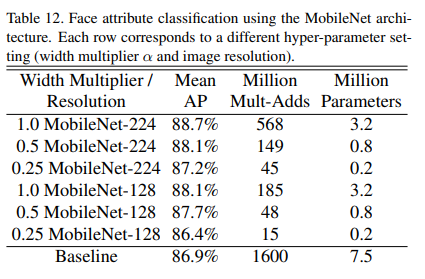
이렇게 정신나간 행위를 하니, mAP도 나름 잘 나왔다는 것을 확인할 수 있습니다.
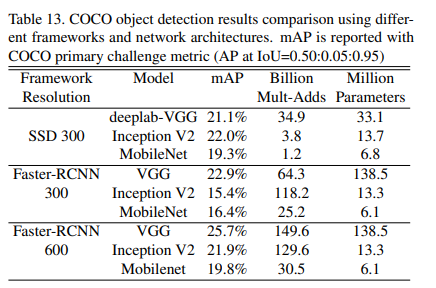
그리고 Object detection에서 유명한 Faster R-CNN과 SSD 프레임워크랑 또 비교를 했을 때,
연산량은 대폭 감소하고, mAP는 별반 차이 없는거를 확인할 수 있습니다.
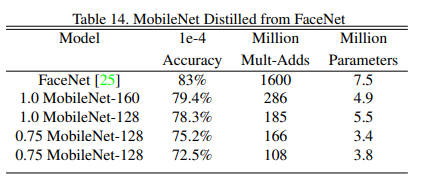
이건 FaceNet이라고, 처음 들어보는 것인데,
쫌 찾아보니,
Triplet loss방식으로, Face Embedding 구축한거로 참 유명한 연구라고 합니다.
여기서 Triplet Loss는
Anchor, Positive, Negetive 이렇게 세 개의 이미지로 구성되어 있다고 하면,
Anchor: 기준 되는 Image
Positive: 다른 이미지에서의 동일 인물
Negetive: 다른 인물의 이미지
이런 의미를 가지게 되고,
이를 Anchor와 Positive 사이의 유클리디안 거리가 가까워지게끔 학습하는 방식입니다.
그리고 Face Embedding은 이미지를 고차원에서 저차원의 벡터 공간으로 매핑하는 과정을 말합니다.
NLP에만 있는 과정이 이 분야에도 있는걸 처음 알았다.
뭐 아무튼, Table 14 는 이 FaceNet의 성능을 뛰어넘었다는 것을 보여줍니다.
다음에는 이 연구 쫌 흉내내보는 코드로 찾아뵙도록 하겠습니다.
감사합니당 ~ 🦾
참고자료
https://arxiv.org/abs/1704.04861
