
MobileNet 논문 리딩 내용입니다.
내용도 많고, 이걸 한번에 다 머릿속에 넣으려니 정리도 안 되어서 그냥 두번에 나누어서 올리도록 하겠습니다.
Approach
MobileNet은 embedded 플렛폼에 넣기 위해서 고안된 Network 입니다.
기존의 Network는 높은 정확도만 생각하다보니, 크기, 속도는 그렇게 효율적이지 못했습니다.
그렇다 보니, 마냥 무거운 모델을
작디 작은 핸드폰, 웨어러블 시계 이런 곳에는 안들어가니 이런 연구들이 나오게 되었습니다.
단순 Image classification 대회들이 이미 역사속으로 사라진게 위의 주장을 대변하는 것 같다.
여기서 또 최적화 방식에 대해 좋은 설명을 해줬는데,
Network를 작게 만드는 방식은
축소
분해
압축
Huffman Coding
Bigger Network가 Smaller한 Network를 가르치는 방식
이런 방식들이 있다고 합니다.
여기서 MobileNet이 채택한 방식은 축소 방식의 한 범주라고 보면 됩니다.
Network Flow
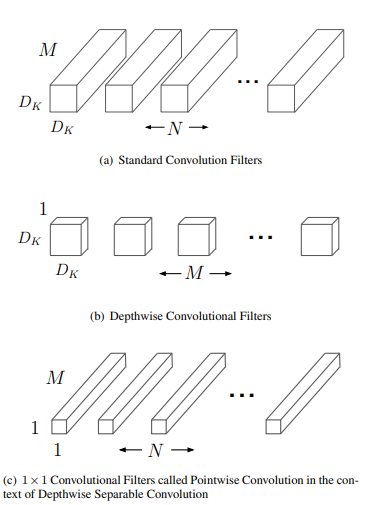
이 Network는 위 그림에서 (a)를 (b)와 (c)로 분리를 한 구조 입니다.
(a)는 기존의 신경망 구조이고, MobileNet은 이 기존 신경망 구조를 (b)와 (c)와 같이 분리를 했습니다.
(b)가 Depthwise Convolution(깊이별 합성곱) 이고, (c)가 Pointwise(1x1) Convolution 인데,
기존 신경망은 입력 데이터의 모든 채널에 걸쳐서 필터(커널)를 적용하여 새로운 특징을 생성한다면,
Depthwise Convolution은 각 입력 채널에 대해 독립적으로 필터를 적용합니다.
이는 입력 채널마다 별도의 필터가 있어서 각각의 입력 채널 내에서만 Conv연산을 수행하게 됩니다.
뭔가 느낌이 기존 신경망보다 연산량이 확 늘어날거 같은 느낌이 드는데,
입력 특성 맵의 차원 D_F x D_F x M,
출력 특성 맵의 차원 D_F x D_F X N,
필터 크기 D_K x D_K
입력 채널 수 M
출력 채널 수 N
이라고 하면,
기존 Convolution 연산량은 D_K × D_K × M × N × D_F ×D_F,
Depthwise Convoltion의 연산량은 D_K × D_K × M × D_F × D_F
이 됩니다.
이는 기존 Convolution은 필터를 여러개 적용해서 여러 출력 채널을 생성하지만,
Depthwise Convolution은 각 입력 채널에 독립적 필터가 적용되어 출력 채널은 입력 채널수와 동일하므로, 연산량이 확 줄어듦을 알 수 있습니다.
그렇게 3x3 depthwise 를 거치게 되고, 이를 통해서 딴것보다 8~9배 정도 적은 계산량에 도달했다고 합니다.
이렇게 Depthwise Convolution에서 뱉은 출력값을 Pointwise convolution에 넣어서 새로운 특성을 생성하게 됩니다.
1x1이 나오는데, 이 논문에서도 Inception에서 착안했다고 말했다.
Network Structure
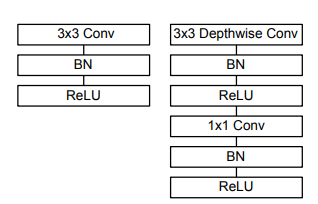
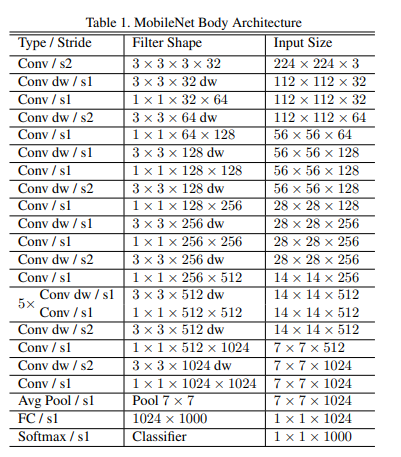
MobileNet은 첫 계층에서만 일반적인 Convolution을 적용했고, 이후의 계층에서는 Depthwise Convolution을 적용했습니다.
전체 계층에 BN(Batch Normalization)을 적용했고, Activation Funtion으로 ReLU함수를 썼습니다.
그리고 다운 샘플링을 위해 첫 계층(일반적 Conv계층)과 Depthwise Conv계층에서 stride 기법을 사용했고, Average Pooling을 통해 최종 FC(Fully Connected)계층에 가기 전에 1 by 1 사이즈로 만듭니다.
또한 GEMM 방식을 써서 최적화를 했다고 하는데, General Matrix Multiply의 약자로, 일반적인 행렬 곱셈을 의미합니다.
95% 정도를 1 by 1 계산에 썼다고 하고, Parameter 조정에 75% 정도 GEMM에 맞춰져 있다고 하니, 얼마나 이 연산이 중요한지 알 수 있습니다.
그리고 다른 모델보다 Normalization & Data Augmentation 적게 써서 overfitting 문제를 줄였습니다.
그냥 딥러닝 프레임워크 라이브러리들에 GEMM 연산이 들어가있다.
그렇게 크게 대단한 건 아닌 듯 하다.
Thinner Model
이 친구들이 cost 줄이기 위해 두가지 방식을 썼다고 하는데,
1. ‘width multiplier α’ 도입
2. ‘resolution multiplier ρ' 도입
이렇게 총 두가지 입니다.
1. width multiplier α
여기서 입력 채널이 M이면, αM이 되고, 출력 채널은 αN이 됩니다.
결국 총 cost는
DK · DK · αM · DF · DF + αM · αN · DF · DF
이 되고,
여기서 α 값은 (0, 1]의 범위를 가지게 됩니다.
대부분 설정은 1, 0.75, 0.5, 0.25로 둔다고는 하는데,
α = 1이 기본 MobileNet, α값이 점점 작게 될수록 축소된 MobileNet을 의미하게 됩니다.
이 방식은 파라미터값 α^2 만큼 줄이는 엄청난 효과를 가져왔다고 합니다.
2. resolution multiplier ρ
이 방식은 input 이미지에 사용 가능한데, 이로인해 축소도 가능하다고 합니다.
즉, input 이미지 설정으로 ρ 설정이 가능합니다.
위 α 와 ρ 적용한 계산 비용은
DK · DK · αM · ρDF · ρDF + αM · αN · ρDF · ρDF
이고,
ρ 범위값은 (0,1],
보통은 224, 192, 160, 128로 설정하고,
α와 동일하게 1은 기본 MobileNet,
ρ < 1은 감소된 MobileNet을 의미하게 됩니다. cost는 ρ^2만큼 줄이는 효과를 가져왔습니다.
남은 부분은 빠른 시일 내에 정리해서 올리도록 하겠습니다.
감사합니당 ~ 🦾
참고자료
https://arxiv.org/abs/1704.04861
