OCR 성능 올리기 위한 edge detection(에지 검출) 내용입니다.

이미지 작업할 때, 많이 사용되는 사진 인데,
물체 경계선 쪽을 보아하면 색상이 조금씩 바뀌는 것을 볼 수 있습니다.
여기서 색상이 바뀐다고 하면,
픽셀 값도 분명한 차이가 존재하기 마련이고,
이 값을 인식하는 것을 에지 검출이라고 합니다.
즉,
어떤 물체의 윤곽선 따기 라고 생각하시면 됩니다.
Prewitt operator, Sobel Operator, Chen-Frei Operator 등,
edge 검출 도구는 참 많습니다.
여기서는 Prewitt detector 와 Sobel detector만 다뤄보도록 하겠습니다.
사실 이것저것 다 적용해봤는데, 큰 차이가 없어서 두개만 정리하는거다.
- Prewitt edge detection
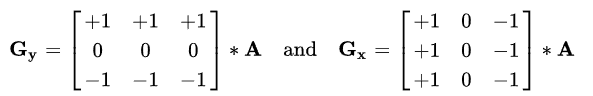
Prewitt 이라고 해서 어려운게 아니고,
위 그림처럼, 필터의 한 종류라 생각하시면 됩니다.
수평 방향, 수직 방향의 밝기 변화를 찾는 것인데,
-1, 0, 1 값들로 구성되어 있습니다.
값들이 단순해서, 간단하고 빠르다는 장점이 있지만,
이미지 픽셀값 변화(밝기 변화)가 명확해야 잡을 수 있다는 단점이 존재합니다.
Prewitt_detector_gy = np.array([
[-1, -1, -1],
[0, 0, 0],
[1, 1, 1]
], dtype=np.float32)
Prewitt_detector_gx = np.array([
[-1, 0, 1],
[-1, 0, 1],
[-1, 0, 1]
], dtype=np.float32)
prewitt_edges_x = cv2.filter2D(image, -1, Prewitt_detector_gy)
prewitt_edges_y = cv2.filter2D(image, -1, Prewitt_detector_gx)
prewitt_edges = cv2.magnitude(prewitt_edges_x, prewitt_edges_y)
prewitt_edges = cv2.normalize(prewitt_edges, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)적용 코드 입니다.
필터는 워낙 간단해서 그냥 생성했고,
밑에 정규화(cv2.normalize) 부분이 보입니다.
cv2.magnitude가 유클리드 거리 구하는 함수인데,
이 값이 255보다 더 큰(컴퓨터 출력 가능 범위를 훨씬 넘어가는) 값이 나올 수 있습니다.
그래서 0 ~ 255 값 범위를 갖도록 스케일링을 한 것이고,
숫자 타입은 각각의 라이브러리에 맞춰준 것입니다.

왼쪽은 그림자 제거한 이미지, 오른쪽은 이 이미지를 Prewitt operator 거친 이미지 입니다.
육안으로 봤을 땐, 어떤게 더 좋은 OCR 결과를 끌어올지는 잘 모르겠습니다.
- Sobel edge detection
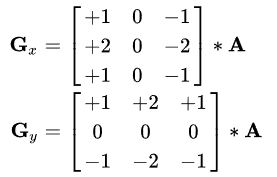
Prewitt과 비교하면, -2, -1, 0, 1, 2 로,
좀 더 다채로워 진게 보입니다.
중앙부 기준 상하(), 좌우() 낮은 가중치를 부여해서,
중점되는 픽셀을 더 강조하는 효과가 있습니다.
Chen-Frei는 값으로 변화하는데, 소수점들 계산 때문에 연산량이 더 많다고 한다.
Sobel_detector_gy = np.array([
[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]
], dtype=np.float32)
Sobel_detector_gx = np.array([
[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]
], dtype=np.float32)
sobel_edges_x = cv2.filter2D(image, -1, Sobel_detector_gy)
sobel_edges_y = cv2.filter2D(image, -1, Sobel_detector_gx)
sobel_edges = cv2.magnitude(sobel_edges_x, sobel_edges_y)
sobel_edges = cv2.normalize(sobel_edges, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)제가 적용한 코드는 이와 같고,
sobel_x = cv2.Sobel(img, cv2.CV_32F, 1, 0, ksize=3)
sobel_y = cv2.Sobel(img, cv2.CV_32F, 0, 1, ksize=3)cv2 내부에 Sobel 연산자를 지원해서 이런식으로도 많이 쓰는데,
저는 그냥 필터 값 명확하게 보고 싶어서 직접 저렇게 해주었습니다.

적용했을 때의 결과물 입니다.
왼쪽은 Sobel 결과물, 오른쪽은 Prewitt 결과물 인데,
577445 숫자값 보면은 좀 더 선명하게 나온게 눈에 보입니다.
- 정리
edge 검출 쭉 진행했는데,
확실히 글자 하나는 기가막히게 눈에 띕니다.
근데 솔직히 이게 더 괜찮은건가? 라는 의문이 듭니다.
그래도 OCR 결과 확인해봐야 아는거니까 일단 기록해 둡니다.
다음 포스팅에서는
바운딩 박스와 경계선 추출 방식을 적용해 보겠습니다.
감사합니당 ~ 🦾
참고자료
https://github.com/Ryuchanghoon/Improve-OCR-Quality/blob/main/reduced_shadow_edge_detection.py
https://en.wikipedia.org/wiki/Prewitt_operator
https://en.wikipedia.org/wiki/Sobel_operator
