마음을 다잡고 왔습니다.
이전에 잘 안나왔던 것에 있어서 의심해볼 사항이 있습니다.
정리해보면,
- 그림자 제거 과정을 거치면서 정보 손실이 있었는가?
- 만약 그렇다면, 노이즈는 어느정도 배제하는게 도움이 되는가?
- EasyOCR 라이브러리에 문제가 존재하는가?
입니다.
쭉 한번 살펴보겠습니다.
- 그림자 제거 시 정보 손실
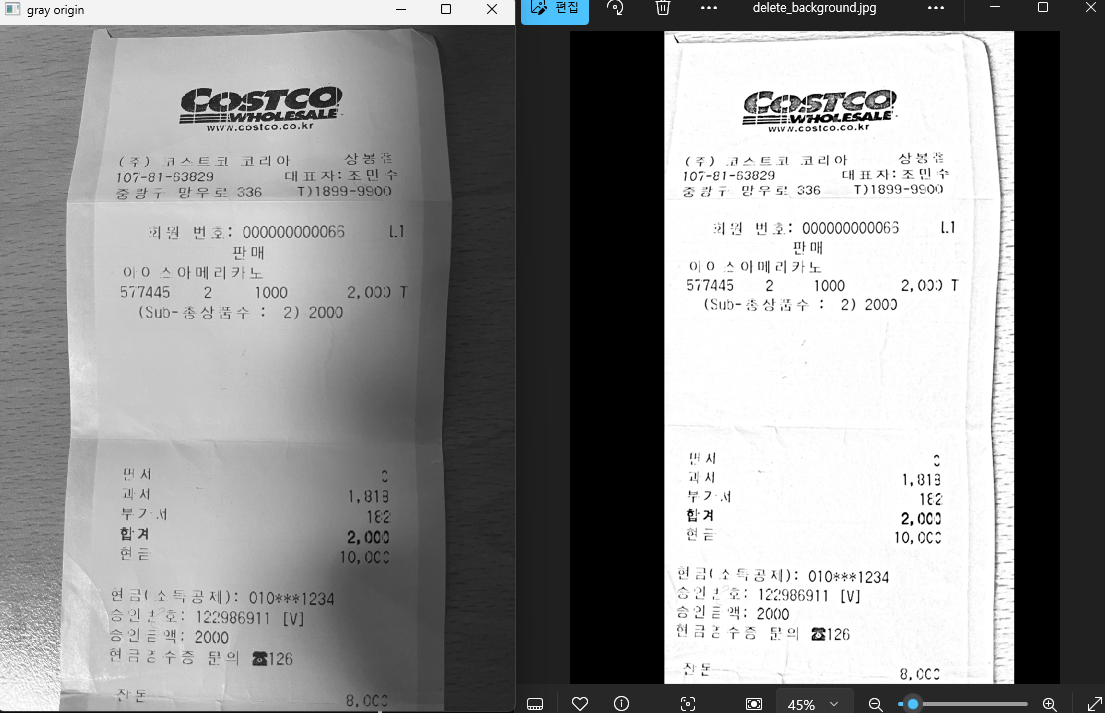
왼쪽 이미지는 원본 흑백 이미지, 오른쪽은 그림자 & 배경 제거 이미지 입니다.
이미지만 보았을 때, 노이즈 제거도 잘 되었고, 텍스트 손실 문제도 없어 보입니다.
하지만, 출력 결과를 봐보면,
흑백 이미지:
['EaATS위', '{어3르; UE', 'WIVNcostcocokr', '(주)', '고스트코', '코리 아', '상봉 손', '107-81-63829', '대 표자: 조민 수', '충항 T', "망우로'", '936', 'T)1899-9900)', '회원', '번호 : 000000000063', '11', '판 매', '이 0 ^ 이메리가노', '577445', '2', '1000', '2,0J)', '1', '(Sub-총상 품수', ':', '2)', '200)', '맨 시', '시', '1,813', '부', '7', '서', '182', '합', '겨', '2,00)', '든', '10,0Cs', '현금( 소득공제) :', '010***1234', '승신 ! 호; 122986911', '[V]', '승민 끝 백', '2000', '현 금근 수증', '문 의', '8126', '산돈', '8,OC~']
그림자 + 배경 제거:
['또C35동위', '{내귀o로 교E', 'wIVicostcocokr', '(주)', 'i스트 코', '고리 아', '상 봉 손', '107-81-63829', '대 I 자: 조민 수', '중앙 7', "망무도'", '236', 'T)1899-9900)', '회원', '민호: 000000000063', '1.1', '판 매', "이 0 ^ 이메리가'", '577445', '2', '1000', '2, ()) )', 'T', '(Sub- 3 상 ,수', '2)', '200)', '맨', '셋', '1,813', '어', '12', "'", '겨', '2,0CJ', '든', '10,(Cs', '급( 소득공제) : 010***1234', '언', '신 ! i: 122986911', '[V]', '승민 끝 백', '20)()0', '헌금 근 수층', '문의', '812f;', '신논', '8,(C']
아마 그림자 제거하면서 약간씩 흐릿해진 부분이 보이는데,
그것 때문에 성능이 좀 더 약해진 것 같습니다.
그럼 이제 다른 것도 봐보겠습니다.

왼쪽은 흑백 이미지에서 CLAHE 과정 거친 것,
오른쪽은 그림자 & 배경 제거, CLAHE를 거친 후의 이미지 입니다.
두 이미지 전부 글자는 뚜렷하게 되었지만, 약간의 노이즈는 추가된게 보입니다.
그래도 실제 결과도 확인해봐야 하니, 함 봐보겠습니다.
흑백 + CLAHE:
['K44Z:위', '1S무;U트', "WI'NGostco.cokr", '(주)', '코스트린', '코리아', '상봉 손', '107-81-63829', '대표자: 조민 수', '중항다', '망우로', '336', 'T)1899-9900)', '회원', '번호: 000000000063', '11', '판매', '00 스아메리카노', '577445', '2', '1000', '2,0J)', '1', '(Sub-총상 품수', '2) 200)', '맨 시', '서', '1,813', '7', ' 서', '18z', '"', '곁', '2,00)', '10,oCs', '현금( 소득공제): 010***1234', '승인 문 호; 122986911', '[V]', '승민 끝 백', '2000', '현 금증 수증', '문의', '8126', ' 잔돈', '8,oCs']
그림자 + 배경 제거, CLAHE:
['또C5Z{위', '{내귀o트교E', 'wIV ,costcocokr', '(주)', '고스트코', '코리 아', '상 봉 손', '107-81-63829', '대 표자: 조민 수', '충항 주 망우로', '236', 'T)1899-9900)', '회원', '반호: 000000000063', '11', '판 매', '이 0 스 이메리가노', '577445', '2', '1000', '2,0))', '1', '(Sub-상 ;수', '2)', '200)', '맨', '부', '셋', '1,813', '1t2', '합', '겨', '2,00J', '근', '10,oCs', '금( 소득공제) : 010***1234', '헌', '민', 'J', '호', '122986911', '[V]', '승민 끝 백', '2(()0', '헌 금근 수증', '문의', '8126', '돈', '8,0Cs']
한글 부분을 봐보면 어느 부분은 잘 나오고, 어느 부분은 잘 안나오고,
숫자 부분의 성능은 좀 더 좋아진것 같기도 하고,
아직까지는 확실히 좋아졌다고 답하기 애매합니다.
- 노이즈 배제 상황
그럼 무작정 노이즈가 추가되어도,
글자만 또렷해지면 잘 되는가에 대한 실험 입니다.

이 이미지는 그림자 제거 & 배경 제거 & CLAHE & Mean adaptive thresholding
과정을 거친 이미지 입니다.
글자 제외 부분을 봐보면 노이즈가 증가했으나,
글자 부분은 확실히 또렷해졌습니다.
이제 출력 결과를 봐보면,
그림자 제거 + 배경 제거 + CLAHE + Mean adaptive thresholding:
['"]하잎', 'WIN,costco.co,kr', ':코스트코', '코리아', '상 봉 :쪽', '107-81-63829', '대표자: 조민 :수=', '출중 항 수망우로 336', 'T)1899-990u)', '회원 번호: 000000000O63', 'L1', '판매', '아0 :스: 아메리카노', '577445', '2', '1000', '2,O))', '(Sub-총상품수', '2) 200)', '댐 시', '과 서', '1,813', '부7: 어', 'IGz', '입겨', '2,00)', '현<', '10,OCs', '현 금( 소 독공제) =', '010x1234', '승', '인 손 호; 122986911', '[V]', '민듣백; 2000', '현 금증 수증 문의 8126', '잔돈-', '8,0C;', '(주:)']
추출 텍스트 자체도 노이즈가 껴있다고 말하는 것 같습니다.
무작정 노이즈 무시하고, 텍스트만 살려서 좋은 성능을 내지는 않습니다.
여기서 말씀드린 것 말고도 많은 실험을 거쳤는데,
너무 길어서 밑에 링크로 대체하도록 하겠습니다.
- EasyOCR 라이브러리 문제?
이미지 퀄리티는 나쁘지 않은데, OCR 결과가 생각보다 안 나온다면,
OCR 모델을 의심해 볼 수 있습니다.
보통 OCR 성능이 잘 안 나온다고 하면,
학습 데이터에 특정 폰트가 안 들어가서 그런 경우도 있습니다.
원본 이미지:
[':예4-위', '{어트;트', '감환사밥기도(<기엽응*', '(주)', '고스트코', '코리 아', '상봉 손', '107-81-63829', '대 표자: 조민 수', '충항 주', "망우로'", '936', '7)1899-9900)', '회원', '번호: 000000000063', '11', '판 매', '이 0 ^ 이메리가노', '577445', '2', '1000', '2,0))', '1', '(-신6-총상 품수', ':', '2)', '200)', '맨 시', '시', '1,813', '부', '7 어', '182', '합', '겨', '2,00)', '든', '10,00~', '현금( 소득공제) : 010***1234', '승신 ! 호; 122986911', '[벼]', '승민 끝 백', '2000', '현 금근 수증', '문의', '8126', '산문', '8,00~']
하지만 위와 같이, 원본 이미지(컬러 이미지)로 실험을 했을 때,
한글이 어느 정도 까지는 잡히기 때문에,
학습 데이터 문제는 아니라고 볼 수 있습니다.
- 정리
이제 어느정도 이미지 전처리 작업은 마무리 해야할 것 같습니다.
실험한 이미지는,
시간이 좀 지난 영수증 이라서 텍스트 지워진 부분이 많이 보이는데,
현재까지 실험해본 결과,
- GrayScale 변환
- 그림자 제거
- Histogram equalization
방법들은,
저처럼 오래되어서 영수증 내 지워진 텍스트
혹은 출력 자체가 이상하게 된 경우만 없다면,
확실히 도움이 될 것 같습니다.
다만, 히스토그램 평활화는 노이즈 많이 낄 수도 있어서 주의해서 적용하세요~
이제 남은건 다른 모델도 적용해보고,
이렇게 해도 좋아지는게 안보이면,
EasyOCR 파인튜닝도 고려해봐야 겠습니다.
지금까지 적용했던 것들 컨테이너화하여 공유할 계획입니다.
필요하신 분들 쉽게 쓸 수 있도록 정리해서 다시 포스팅하겠습니다.
감사합니당 ~ 🦾
참고자료
https://github.com/Ryuchanghoon/Improve-OCR-Quality/blob/main/OCR_Compare.txt
