소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
ICASSP 2021 에 올라온 논문입니다. (Paper)
Citation
@misc{liu2021endtoend,
title={End-to-end Neural Diarization: From Transformer to Conformer},
author={Yi Chieh Liu and Eunjung Han and Chul Lee and Andreas Stolcke},
year={2021},
eprint={2106.07167},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Introduction
Background
- SA-EEND 포스트 내용 참고!
Limitation
- 1) Can't handle local cues (e.g. at speaker changes)
- 기존 SA-EEND에는 CNN, RNN과 같이 주변
지역 정보를 다루지 못한다.- 즉, transformer의 attention은
모든 frame을 동등하게 aggregation한다.- 이 정보는,
speaker changes지점과발화의 연속성등을 모델이 다루지 못하는 단점을 가지고 있다.- 2) stacked-frame sub-sampling 의 한계
- stacked-frame 은 단순히 주변 context 들을 단순히
stack하는 방법으로, convolution 과 같이학습을 통한 sub-sampling이 더 효과적일 수 있다.- 3) 학습 dataset 개편
- 이전 SA-EEND 연구에서 simulation 과 real dataset을 합쳐 training 한 경우 실제 CALLHOME 에서 좋아짐을 보였지만 아직 개편이 필요해 보였다.
Main Proposal
- 1) EEND can use local cues using
Conformer
- Conformer의 내부 convolution 을 통해서 주변 Frame 들, 즉 local cues 정보를 모델링 할 수 있게 되었다.
- 2)
convolutional sub-sampling
- 단순히 stacked-frame 형태의 sub-sampling 보다
depthwise convolution layer 를 이용한 subsampling을 통한 성능 향상을 보였다.- 3)
revised training dataset
- CALLHOME dataset은 기존 simulation 데이터 셋의 overlap ratio 보다 낮은 값을 가지며 (simu:약 30%, real:약 10%), 데이터의 현실성이 떨어진다. (무작위로 섞기 때문에 화자 말이 나오기 적절하지 않은 타이밍에 나오는 경우가 많음)
- 본 논문에서는 SA-EEND 와 같이 simu 과 real 데이터 셋을 같이 사용했다.
- 추가로, 기존의
화자 발화 길이의 제약(1.5초 이상인 speech segment만 사용)이real dataset에서는 화자 발화 길이 제약이 없는 것이 더 학습 성능에 좋음을 보였다.- 추가로 Libri-speech 데이터도 같이 사용해 보았지만, 이는 그리 좋지 않았다.
- SpecAugment 추가 실험
Proposed Method
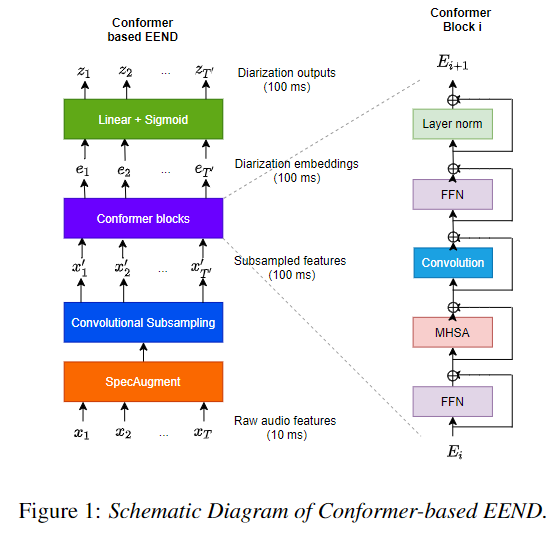
Convolutional sub-sampling
Intro
좀 더 나은 sub-sampling 방법이 있지 않을까?에 대한 부분에서 시작된거 같다. (논문 나오기 전 DIHARD III Challenge 에서 1D-Conv 기반의 sub-sampling 방법이 제안되긴 함)
Architecture
- 이 부분은 논문에 기재된 내용만으로
유추한 것입니다. 실제와 다를 수 있습니다 ㅠㅠ 혹시 다르게 생각하시는 부분이 있으면피드백 부탁드립니다...!
- Stacked-Frame (same SA-EEND)
- 주변 7 frames 과 현재 frame (previous 7 frames + current 1 frame + 7 frames = 15 frames)을 staked 한다.
23-dimensional log-mel:10*T x 23 -> 10T * 345 (23x15)80-dimensional log-mel:10*T x 80 -> 10T * 1200 (80x15)
- Convolutional Sub-Sampling (2 layer)
- computation cost 를 줄이기 위해 2층의 depth-wise separable convolution 사용함
23-dimensional log-mel
- kernel size: {(3,3), (7,7)}, strides: {(2,1), (5,1)}, (maybe? padding: {(1,1), (3,3)})
- Input:
1 x 10*T x 345- 1st layer:
1 x 10*T x 345 -> 1 x 5*T x 345- 2rd layer:
1 x 5*T x 345 -> 1 x T x 34580-dimensional log-mel
- kernel size: {(3,3), (7,7)}, strides: {(2,2), (5,2)}, (maybe? padding: {(1,1), (3,3)})
- Input:
1 x 10*T x 1200- 1st layer:
1 x 10*T x 1200 -> 1 x 5*T x 600- 2rd layer:
1 x 5*T x 600 -> 1 x T x 300
Conformer
Intro
- Conformer 는 ASR encoder architecture 로 local 과 global 의존성을 모델링 하기 위해서 사용 되었다.
- 기존 transformer의 multi-head self-attention과 FFN 구조는 동일
- 변경점
- 1)
pre-norm -> post-norm으로 변경됨- 2) multi-head self-attention 과 FFN 사이
Convolution 추가- 3)
앞단에 FFN 추가 됨
Architecture
- Conformer Configures
- The number of Encoder blocks
P: 4- The hidden dimension of Encoder
D: 256- The number of header
H: 4- position-wise FFN(Feed Forward Network) internal unit: 1024(Transformer), 256(Conformer)
- convolution kernel size: 32
- model
- 1) (pre) FFN(Feed Forward Network)
- 2) multi-head self-attention
- 3) Convolution (depth-wise separable convolution)
- 4) (post) FFN + layerNorm
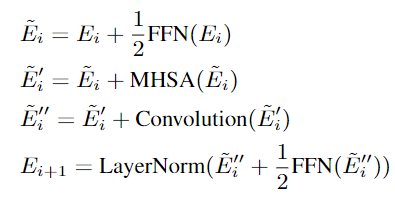
SpecAugment
Intro
- 이전 ASR 에서 사용하던 Data Augmentation 방법
- sub-sampling 전에 Frequency 와 Time에 대해서 SpecAugment masking 적용
- Time Warping 은 사용하지 않음
Config
- Frequency: At most two consecutive Mel frequency channel (
F = 2)- Time: Maximum-size of consecutive time step mask (
T = 1200)
Additional Dataset
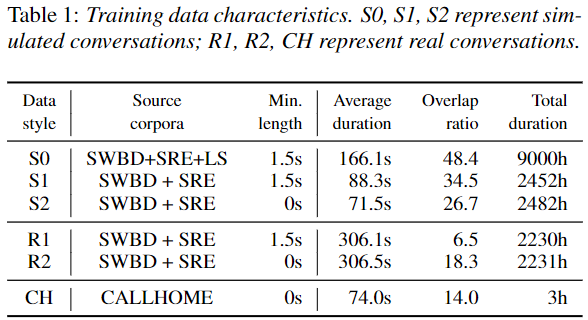
Dataset
- SWBD + SRE (기존 SA-EEND dataset 과 동일)
- Total Speaker: 6,381 (train: 5,743, test: 638)
- LibriSpeech(LS) (추가 실험 데이터)
- Total Speaker: 2,496 (970 hours)
- CALLHOME dataset
- Adatation: 155 recordings (2 speakers)
- Test: 148 recordings (2 speakers)
Data style
- simulation data
S0:
- 기존 SA-EEND simulation 데이터 + LS
- beta: 2
- Utterance Min length: 1.5 sec
S1:
- 기존 SA-EEND simulation 데이터와 동일
- beta: 2
- Utterance Min length: 1.5 sec
S2:
- 기존 SA-EEND simulation 데이터와 동일
- beta: 2
- Utterance Min length: 0 sec
- Real dataset
R1:
- 기존 SA-EEND Real 데이터와 동일
- Utterance Min length: 1.5 sec
R2:
- 기존 SA-EEND Real 데이터와 동일
- Utterance Min length: 0 sec
CH:
- real conversation 데이터
Experiments Result
Model Type
- Self-attention EEND (SA-EEND)
- Transformer-based EEND (TB-EEND)
- SA-EEND에서 아래 사항 변경
- SpecAugment 추가
- Convolutional Sub-Sampling 변경
- Conformer-based EEND (CB-EEND)
- TB-EEND에서 아래 사항 변경
- Encoder block:
Transformer -> Conformer
Training Strategy
- batch Size: 64
- 1) Training set
- learning rate: 1.0
- scheduler
- norm warm up: 25k
- optimizer
- adam
- epoch: 100
- 2) Average model parameters
- 마지막 10 epoch model parameter 값을 averaging 하여 사용
- 즉, 각 91~100 epoch에 checkpoint model parameter 들을 평균하여 하나의 model parameter 생성
- 3) Adaptation ( Dataset: CALLHOME dataset )
- 설명
- CALLHOME dataset 은 모델을 학습 시키기엔 적은 데이터 양이기 때문에, adaptation 과정을 이용한다.
- learning rate: 1e-5
- optimizer
- adam
- epoch: 100
- 4) Average model parameters
- 3의 결과에 대해서 2와 동일하게 적용
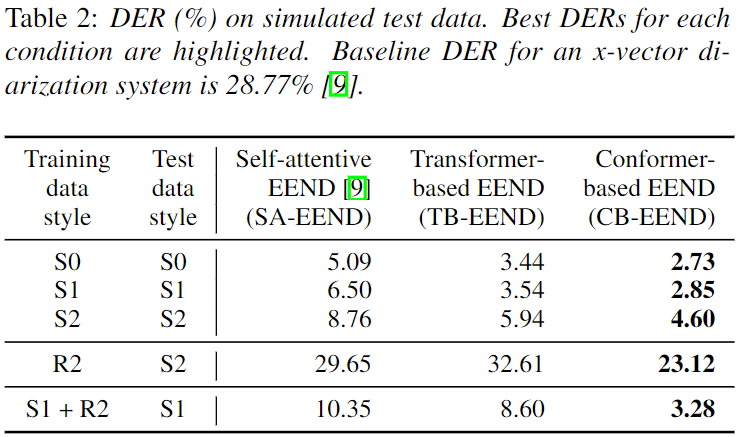
Validation Data 결과
- Simultaion dataset
- 기존 데이터와 LibriSpeech가 추가된 큰
S0가 가장 좋은 성능을 보인다.- utterance 길이가 짧은 것도 포함한
S2에 대해서 성능이 떨어진다. (근데, 짧은걸 찾기 어려운건 당연한거 아닌가 싶다. 정확한 비교 실험은 아닌듯 ?)
- Training:
simu vs Real dataset
- Real dataset으로 학습한 경우 simu test 에 대해서 떨어지는 성능을 보인다.
- TB-EEND
- Convolutional Sub-sampling 과 SpecAugment 가 굉장히 효과적이다.
- 하지만 Real 셋 학습에 대해서는 떨어지는 성능을 보인다.
- CB-EEND
- Conformer 또한 성능 향상의 효과적이었다.
CALLHOME 결과
- Sub-sampling, SpecAugment 관점
- TB-EEND 성능이 모든 면에서 능가하는 성능을 보였다.
- Conformer 관점
- Simulation 만 있는 데이터셋에 대해서 성능저하를 보였다.
- Real 데이터셋
R2으로 학습한 경우 좋은 성능을 보였다.- Simulation 과 Real 데이터셋을 같이 사용한
S1+R2가 가장 좋은 성능을 보인다.Overlap ratio 비율에 대해서 더 민감하게 반응함을 볼 수 있다.

Conclusion
Convolutional Sub-sampling과SpecAugment가 성능 향상에 도움을 보였다.Conformer로 overlap ratio 가 잘 맞는 데이터를 주면 Transformer보다 좋은 성능을 보인다.- Real dataset 은
Min utterance제약을 주지 않고 사용하는 것이 더 좋다.- Simulation과 Real dataset을 같이 합쳐서 학습한 CB-EEND가 CALLHOME dataset에 대해서 가장 좋은 성능을 보였다.

Audio & Speech AI Researcher 입니다.