소개
- 이 글은 단지 CS231n를 공부하고 정리하기 위한 글입니다.
- Machine Learning과 Deep Learning에 대한 지식이 없는 초보입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
참조
-
https://devkor.tistory.com/entry/Visualizing-and-Understanding?category=730880
-
https://younghk.netlify.app/posts/cs231n-lecture-13---visualizing-and-understanding/
-
https://zzsza.github.io/data/2018/06/04/cs231n-visualizing-and-understanding/
-
https://research.sualab.com/introduction/2019/10/23/interpretable-machine-learning-overview-2.html
-
https://hoya012.github.io/blog/Self-Supervised-Learning-Overview/
-
https://hoya012.github.io/blog/Fast-Style-Transfer-Tutorial/
개요
< Visualizing and Understanding >
- Visualizing and Understanding
- First Layer Visualize Filters
- Intermediate Layer
- Last Layer Nearest Neighbors
- Last Layer Dimensionality Reduction
- Visualizing Activations
- Maximally Activating Patches
- Occlusion Experiments
- Saliency Maps
- Grabcut
- Intermediate Features via guided Backprop
- Gradient Ascent
- Fooling Image Adversarial Examples
- Maximization by Optimization
- Style Generation
Visualizing and Understanding
지금까지 ConvNet을 이용하여 Classification, Object detection, Segmentation등의 문제들을 수행하였습니다.
하지만, 이러한 것이 어떻게 Convolutional Network에서 가능한지, 내부에서 무슨 일이 일어나는지에 대해서는 알 수 없었습니다.
이번 챕터에서는 Black Box라고 불리는 딥러닝 모델을 조금 더 해석할 수 있도록 시각화 하는 방법에 대해서 배웁니다.
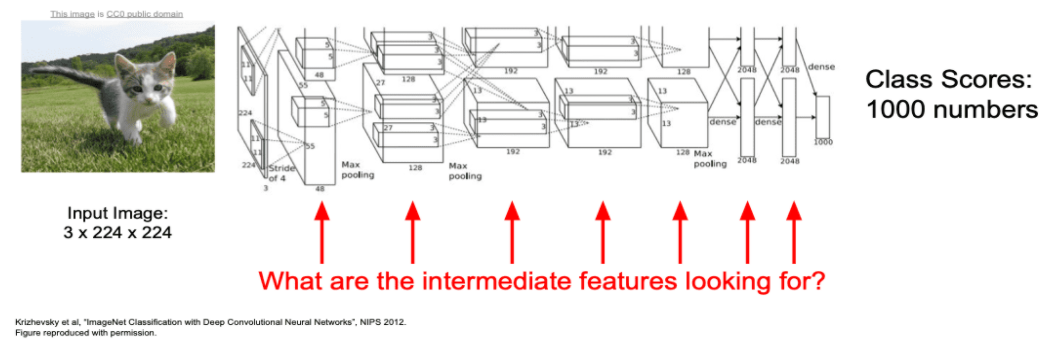
First Layer Visualize Filters
먼저 앞에서 배운 Image Classification의 첫번째 레이어의 필터 값을 살펴봅시다.
아래 그림에는 유명한 Image Classification의 3 Channel의 필터 값을 RGB로 표현한 결과입니다.
- 각기 다른 Image Classifier 모델이 첫번째 필터 값에 대해서 비슷한 모습을 가지는 것을 볼 수 있습니다.
- 사람의 뇌도 처음 물체를 볼때에 아래와 같이
oriented edges성분을 찾는 다고 합니다.

Intermediate Layer
- 첫번째 이후 레이어의 Filter 값은 아래와 같습니다.
- 해석하기 어렵습니다.

Last Layer Nearest Neighbors
- 이제 Filter 값이 아닌 입력에 대한
출력값을 확인해보자.- 아래 왼쪽 그림은 그냥 image의 pixel에 대한 Nearest Neighbor의 결과이다.
- 아래 오른쪽 그림은 AlexNet의 마지막 layer의 출력인 4096-dim vector에 대한 Nearest Neighbor 결과이다.
- image의 pixel과 같은 경우 비슷한 색깔끼리 모여있습니다.
- layer의 마지막 출력값을 이용한 경우 비슷한 물체들 끼리 잘 구분되어집니다.
- 코끼리의 방향과 관계없이 분류됩니다.
- 이러한 것을 네트워트가 학습을 통해 이미지의
semantic content한 특징을 잘 찾아낸 것이라 볼 수 있습니다.

Last Layer Dimensionality Reduction
- 최종 레이어에 대해 차원 축소(Dimensionality Reduction)을 진행하는 방법도 있습니다.
- 차원 죽소 방법
- PCA(Principal Component Analysis) 주성분 분석
- t-SNE(t-distributed stochastic neighbor embeddings)
- UMAP(uniform manifold approximation and projection)
- t-SNE의 예시
- MINST의 28x28-dim 데이터를 2-dim으로 압축해 시각화한 결과 그림
- AlexNet의 마지막 출력 4096-dim 데이터를 2-dim으로 압축해 시각화한 결과 그림


Visualizing Activations
- 중간 레이어의 가중치(filter)를 시각화 하는 것은 어렵습니다.
- 가중치가 아닌 Activation map을 시각화 하는 방법도 있습니다.
- 아래 그림은 이미지에 대한 Activation map 결과를 보여준다.
- 한 patch 부분에 사람의 얼굴 모양을 보고 활성화 되는 것 같아 보입니다.
- 네트워크에 어떤 레이어에서는 사람의 얼굴을 찾고 있는 것일 수 있습니다.


- 사람 또는 동물의 ‘얼굴’을 커버하는 feature map의 Activation Visualization 결과 예시 (Jason Yosinski et al.)
Maximally Activating Patches
- Activating Maximization(활성화 최대화)란
- 어떤 레이어의 한 Activation map을 target으로 정합니다.
- 이 target을 최대화 시키는 이미지를 찾는 방법입니다.
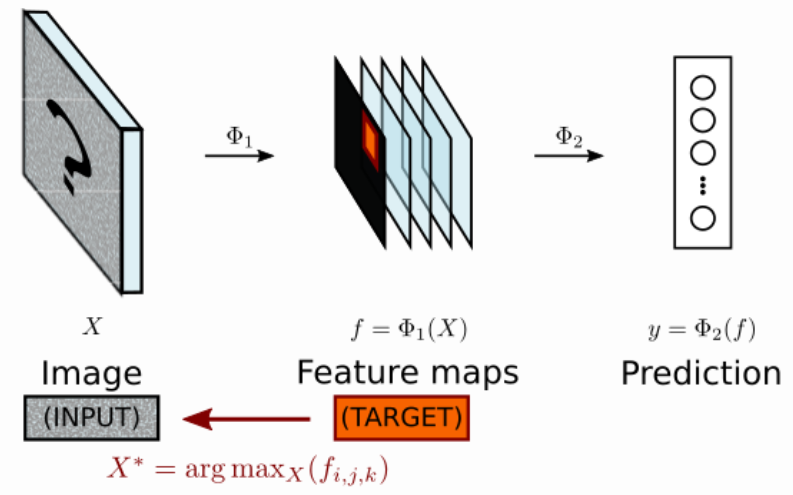
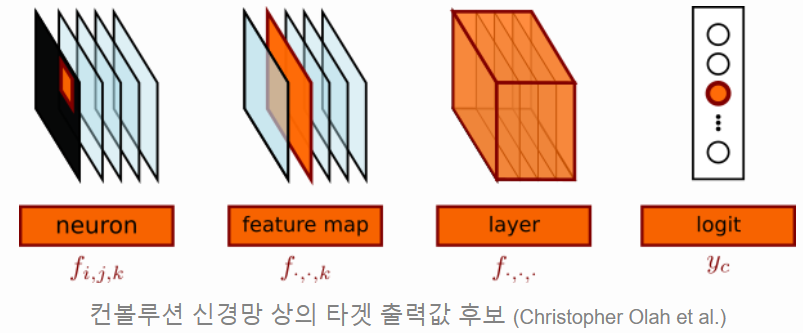
- 위에서 사용할 수 있는 target의 종류는 아래와 같습니다.
- neuron (scalar 값)
- feature map (chaanel)
- layer
- logic (마지막 출력 값)
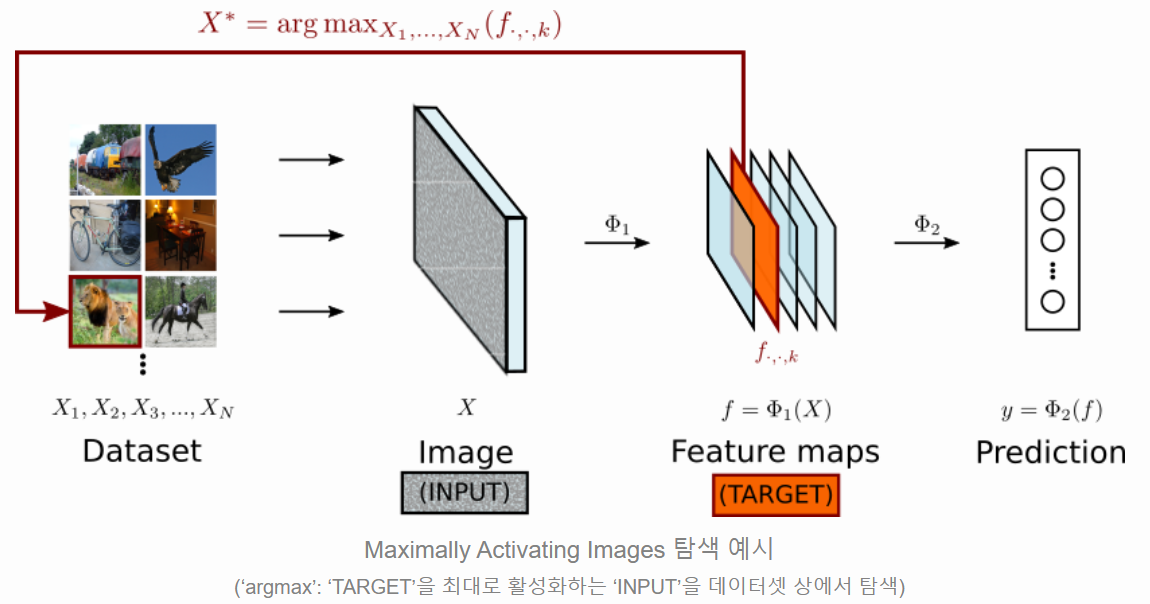
- 여러 입력 데이터를 넣습니다.
- 한 target를 최대로 만드는 image가 무엇이었는지 탐색합니다.
- 각 레이어는 ConvNet으로 이미지 전체가 아닌 일부분을 봅니다.
- 레이어에 따라서 다른 receptive field를 가집니다.
- 깊어질 수록 점점 크고 복잡한 물체를 인식합니다.
- 아래 그림은 Conv6와 Conv9의 비교입니다.
- Conv6의 첫번째 행은 동그라미(아마 눈) 모양을 찾는 것 같이 보입니다.
- Con9의 2번째 행은 사람의 모습등을 찾고 있음을 볼 수 있습니다.

Occlusion Experiments
- Occlusion : 폐쇄
- 이미지의 어떤 부분이 classification(logic)에 영향을 많이 미치는지 찾아보는 방법
- 아래 그림과 같이 코끼리의 한 부분을 가립니다(Occlusion).
- 각 가리는 위치에 따라 코끼리의 logic에 값의 확률 값을 오른쪽과 같이 나타냅니다.
- 이 방법은 1차 근사적 방법입니다.
- 빨간 색은 low probability, 하양색/노란색은 high probability입니다.
- low probability 일수록 classification에 있어서 중요한 부분이라고 추측 할수 있습니다.
- 이러한 영향을 주는 요소를
Attribution(귀착, 귀속)이라고 합니다.

Saliency Maps
- Saliency : 중요한
- Attribution를 찾기 위한 다른 접근 방식입니다.
- 예측 클래스 logic yc의 입력 이미지 X에 대한 gradient를 계산하는 방식입니다.
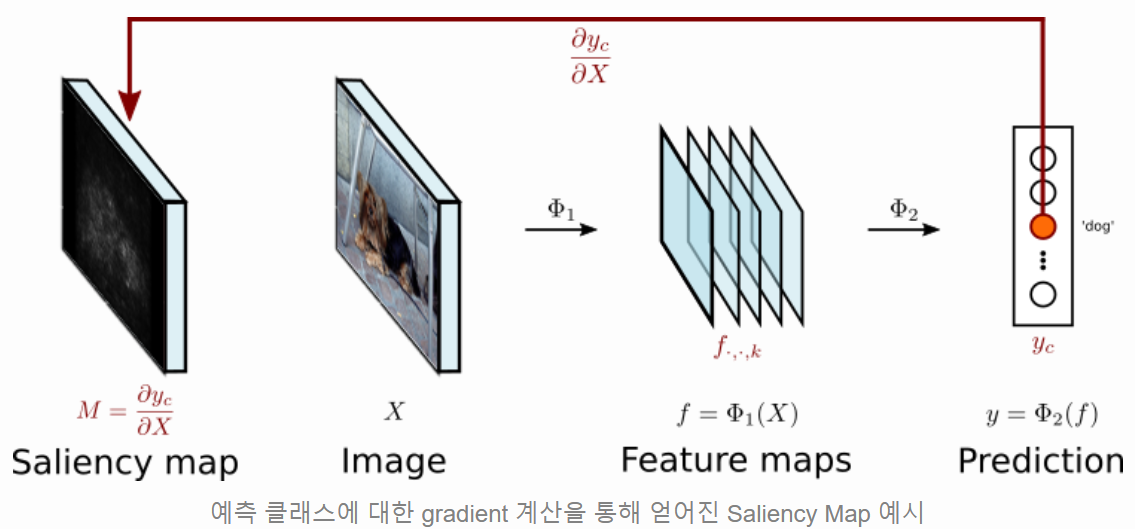

Grabcut
- Saliency map에 Grabcut를 활용하면 Segmentation label 없이 Segmentation이 가능합니다.
- Supervision으로 만들어지는 결과에 비해 그리 좋지 못합니다.
- Unsupervised learning이 가능하다는 점에서 의의가 있는 것 같습니다.

Intermediate Features via guided Backprop
- Guided Backprop은 Saliency Maps 방법과 달리 클래스 logic 값이 아닌
네트워크 중간 뉴런을 하나 고릅니다.- 중간 네트워크의 한 뉴런에 대한 gradient를 계산하게 됩니다.
- Backprop시 ReLU에 대해서 다른 연산을 취합니다.
- 양수인 경우 그대로 사용합니다.
- 음수인 경우 backprop 하지 않습니다.
- 양의 부호인 graident 값만 고려합니다.
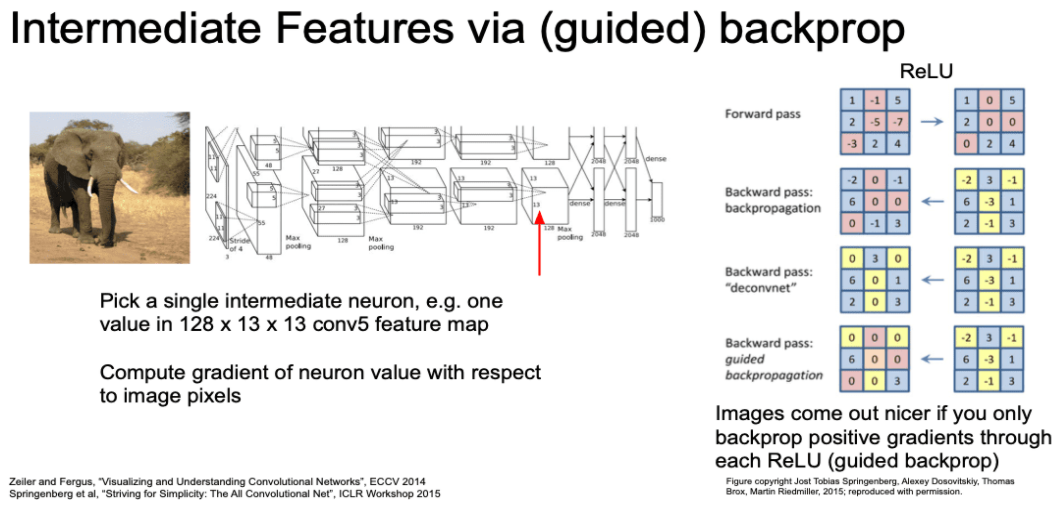
- 전에 Maximally activating patches에서 본 그림의 Guided Backprop 결과입니다.
- 첫 행에서 동그란 무언가를 찾고 있는 것을 짐작했는데, 이러한 추측이 어느 정도 맞다고 생각할 수 있게 되었습니다.

- 더 깊은 ConvNet에 Guided Backprop 결과입니다.
- 2번째 행의 사람 얼굴 형태의 값을 가지는 것을 볼 수 있습니다.
- 이러한 방법은
고정된 입력 이미지에 대한 방법입니다.

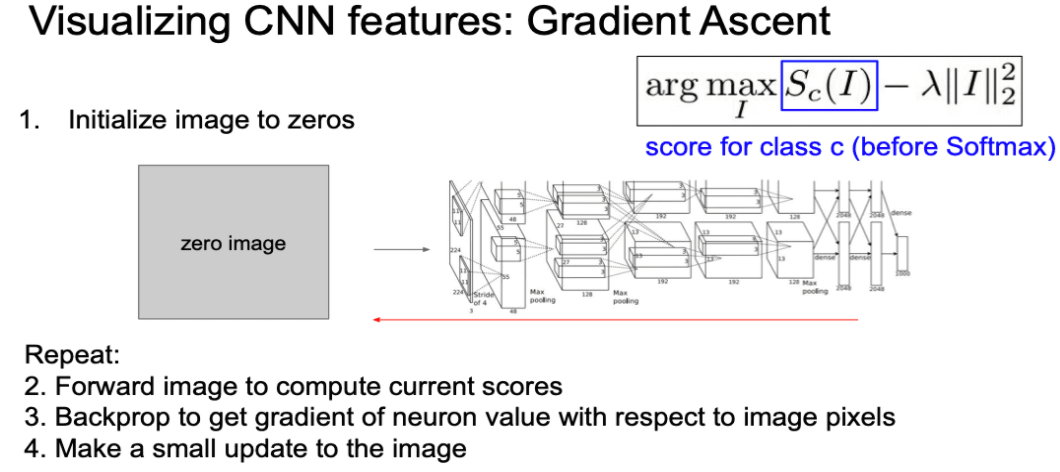
Gradient Ascent
- 고정된 입력 이미지에 대한 의존성을 제거합니다.
- 우리는 Network를 학습하기 위해서 loss에 대한 Gradient Descent 방식을 적용해 왔습니다.
- 여기서는 지금까지와 다르게 Gradient Ascent 방법에 대해서 다룹니다.
- 네트워크의 가중치들을 전부 고정시킵니다.
- Gradient Ascent는
target(중간 뉴런 혹은 클래스 스코어)를 최대화하는입력 이미지를 학습하는 과정이라고 볼 수 있습니다.- Backprop 과정에서 네트워크의 가중치가 아닌 입력 이미지의 pixel값을 바꿔나갑니다.
- 여기서 R(I)인 regularization term이 존재합니다.
- 우리는 Gradient Ascent로 생성된 이미지가 일반적으로 볼 수 있는 이미지이길 원합니다.
- 즉, 이미지가 자연스러워 보여야 한다는 것입니다.
- 이를 제어하는 역할을 합니다.

- Gradient Ascent는 초기 이미지가 필요합니다.
- 보통 zeros, uniform, noise 등으로 초기화 합니다.
- 초기 이미지를 입력으로 넣어, 관심있는 target(logic 또는 중간 뉴런 값)의 값을 계산합니다.
- 아래 예시에서는 softmax 전 logic 값을 사용했습니다.
- 위 target를 Maximization 하는 Gradient Ascent을 입력 이미지 픽셀에 적용합니다.
- logic에 대한 Gradient Ascent의 결과는 아래와 같습니다.
- 덤벨과 컵의 예제를 보면 많이 중첩되 있는 것을 볼 수 있습니다.
- 달마시안의 경우 특징이 잘 나타난 것을 볼 수 있습니다.
- 색상이 무지개인 이유는 Gradient Ascent가 unconstrained value(Range가 제한되지 않은) 이기 때문에 0~255의 pixel로 normalize 하면서 나타나는 오류라고 합니다.

- Gradient Ascent 값을 훨씬 더 깔끔하게 하는 방법도 있습니다.
- L2 norm에 주기적으로 Gaussian blur를 적용하는 방법
- 작은 pixel 값을 0으로 만드는 방법
- 작은 graident 값을 0으로 만드는 방법

- 최종 스코어(logic)에 적용하는 것이 아니라 중간 뉴런에도 적용할 수 있습니다.
- 레이어가 깊을 수록 receptive field가 크며, 보다 큰 이미지를 가집니다.

Fooling Image Adversarial Examples
- Gradient Ascent로 만든 이미지 값을 이용하면 네트워크를 속이는 이미지를 만들 수 있습니다.
- 아래 사진은 거의 차이가 없어 보이지만 코끼리가 코알라로 인식되는 것을 볼 수 있습니다.

Maximization by Optimization
- 위와 같이 한 target에 대해서 Gradient Ascent 하는 방법을 Maximization by Optimization이라고 부릅니다.
- Christopher Olah et al. 에서는 이를 'Feature Visualization'이라고 표현하기도 합니다.
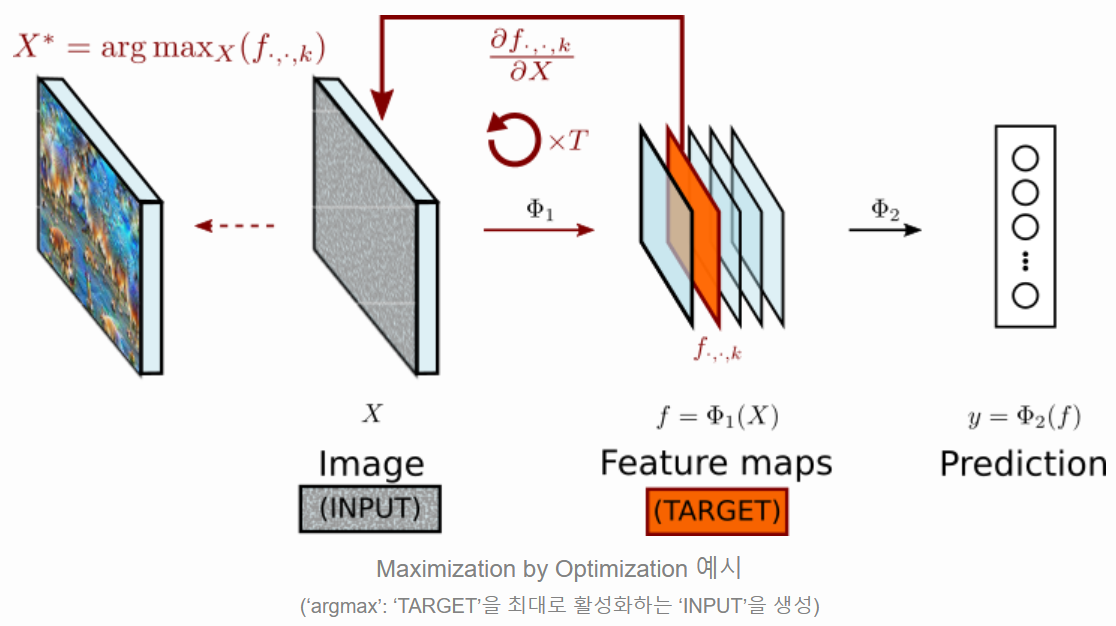
- 아래의 예시 그림은 target 값을 서로 다른 feature map으로 설정했을 때에 Maximization by Optimization의 결과 값입니다.
- 앞쪽 layer의 경우 단순하고 반복적인 패턴(edges, textures)을 커버하는 경향을 보임니다.
- 보다 뒤쪽 layer의 경우 좀 더 복잡한 무늬, 사물의 일부분 또는 전체를 커버하려는 경향을 보입니다.

- Image Classifier의 마지막 출력인 logic 값을 타겟으로 한 Maximization by Optimization의 결과는 아래와 같습니다.

DeepDream
- 참고 자료 : 텐서플로우를 이용해서 딥드림(DeepDream) 알고리즘 구현해보기
- Google에서 발표한 네트워크입니다.
- 사람이 꿈을 꾸면서 환상(hallucination) 같은 것을 보는 느낌과 비슷하도록 이미지를 만들기도 한다고 해서 이와 같은 이름이 붙여졌다고 합니다.
- 여기서는 Maximization by Optimization 과 다르게 특정 Image를 넣어줍니다.
- 그리고 Activation map이 아닌 특정 target layer를 선택합니다.
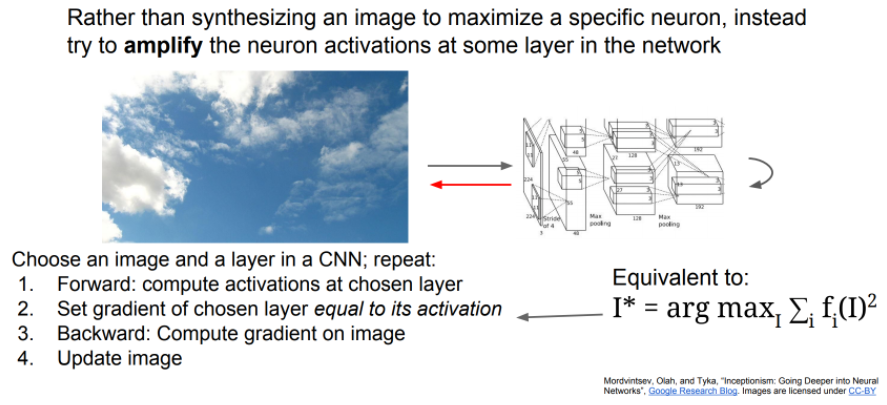
- Image와 layer를 선택하고 아래 과정을 반복합니다.
- Forward
- 선택된 레이어의 Activation 값으로 Gradient를 설정
- 이미지에 Gradient Ascent 적용
- 여기서 선택된 이미지의 Activation 값으로 Gradient를 설정하는 것은 레이어가 가지고 있던 어떤 특징을
Amplify(증폭시키는)역할을 하게 됩니다.- 실제로는 작은 scale에 이미지부터 시작해서 원하는 이미지 크기로 키워나가는 방식을 사용합니다. (multi scale processing)
- DeepDraem의 코드는 굉장히 간결합니다.
- 여기에는 몇가지 트릭이 있습니다.
- graident를 계산하기 앞서 이미지를 조금 움직임(jitter)
- regularization의 역할로 이미지를 부드럽게 만듦
- L1 normalization 사용
- 이미지 합성에서 유용함
- clipping
- pixel이 이미지로 표현되기 위해서는 0~255 사이값 이어야 함

- 얕은 층의 레이어 결과

- 깊은 층의 레이어 결과
- 강아지가 좀 많이 보이는데, 실제로 ImageNet(위의 예제)에는 1000개 중 200개가
강아지이다.



Feature Inversion
- 각 레이어가 이미지의 어떤 요소를 포착하는지 알아보는 또 다른 방법입니다.
- Feature Inversion 방법은 아래와 같습니다.
- 이미지를 네트워크에 통과시킵니다.
- 우리가 보고싶은 특정 layer의 activation map을 저장합니다.
- 이 activation map을 가지고 이미지를 재구성합니다.- regularization으로 gradient ascent를 사용합니다.
- 여기서는 특징 벡터간 거리(L2 Norm)를 최소화하는 방법으로 진행합니다.
- 위와 같은 이러한 방법을 total variation regularizer 라고 합니다.
- 이것이 인접 픽셀 간의 차이에 대한 패널티를 부여합니다.

- VGG-16에 대한 Feature Inversion 예시입니다.
- relu2_2와 같이 얕은 층과 같은 경우 거의 완벽한 이미지가 복원되는 것을 볼 수 있습니다.
- 깊어질수록 공간적인 구조는 많이 유지되고 있으나, 디테일이 많이 약해지고 모호해집니다.
- 낮은 레벨의 특징은 네트워크가 깊어질 수록 소실되는 것을 확인할 수 있습니다.

Texture Synthesis
- Texture(질감?) Synthesis(합성)
- 어떤 texture의 샘플 patch가 주어졌을때, 같은 texture의 더 큰 이미지를 생성하는 것입니다.
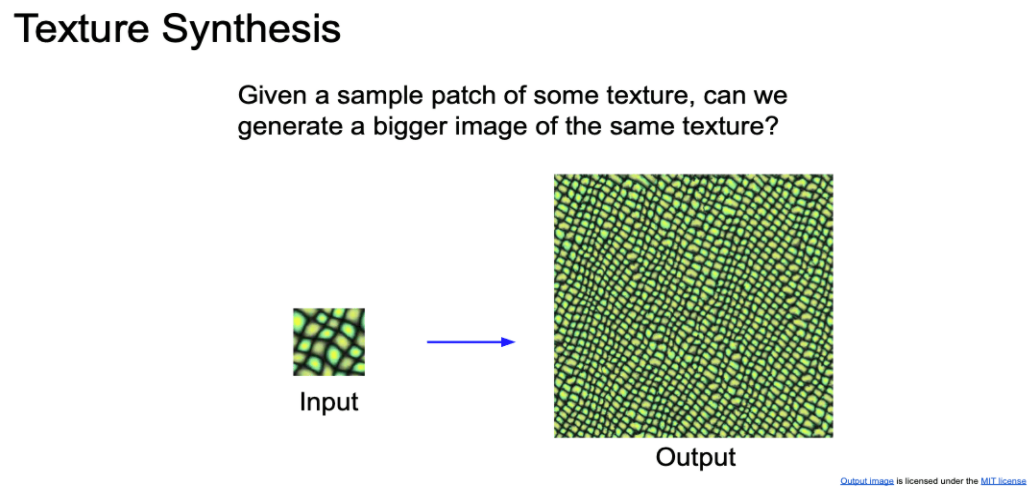
- 기초적인 방법으로 Nearest Neighbor 방법이 있습니다.
- 잘 되는 것 처럼 보이지만, 복잡한 texture에 경우에는 다른 방법을 생각해야합니다.

Neural Texture Synthesis Gram Matrix
- Gram Matrix는 2015년에 제안된 신경망을 이용한 Texture Synthesis 방법입니다.
- 진행과정은 아래와 같습니다.
- 한 Sample Texture를 Network의 입력 이미지로 넣어줍니다.
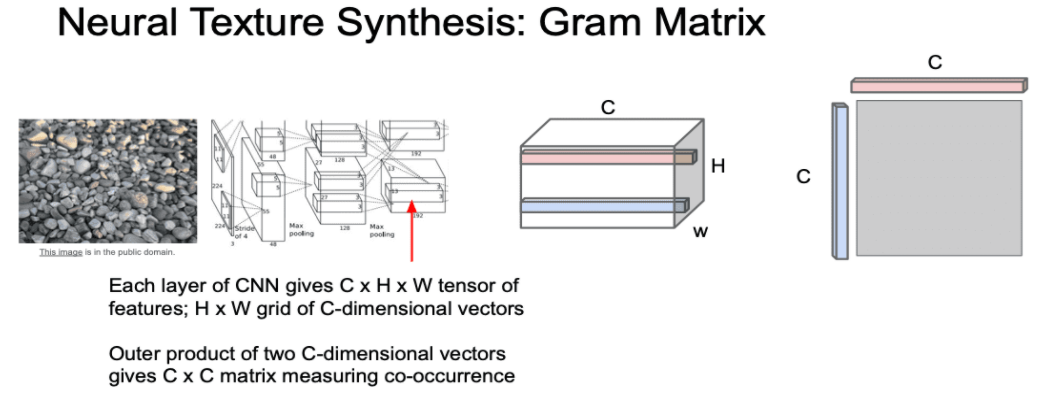
- Feature Inversion때와 같이 특정 layer의 activation map(C x H x W)을 저장합니다.
- 이 activation map을 살펴보면
- H x W grid는 공간정보를 나타냅니다.
- H x W 의 한 점에 있는 C차원 특징 벡터는 해당 지점에 존재하는 이미지의 특징으로 볼 수 있습니다.
- 이제 이 activation map을 이용하여 texture descriptor를 구합니다.
- activation map에서 서로 다른 두 개의 점에 있는 C차원 특징 벡터를 선택합니다.
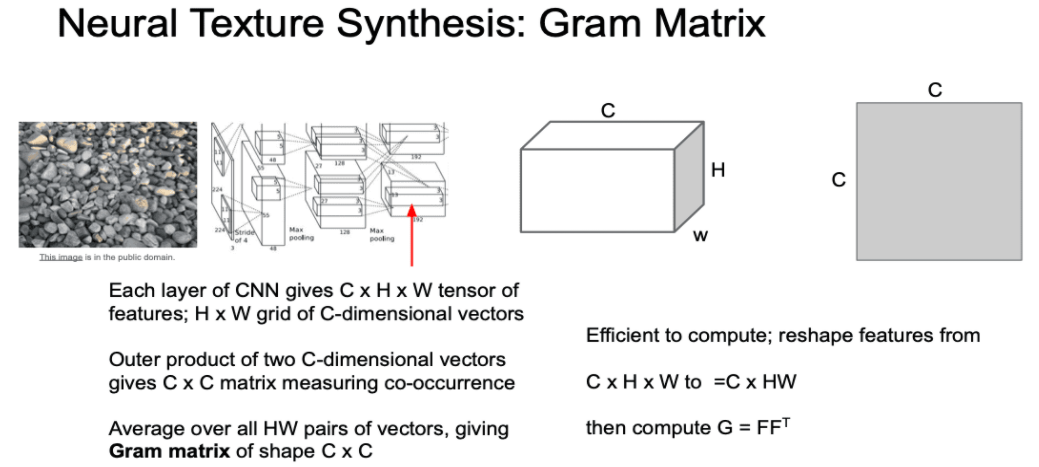
- 이 두 벡터의 외적(outer product)을 계산하여 C x C 행렬을 만듭니다.
- 이 C x C 행렬은 이미지 내 서로 다른 두 지점에 있는 특징들 간의 co-occurrence를 담고 있습니다.
- 이 C x C 행렬의 (i, j)번째 요소의 값은 두 입력 벡터 i번째, j번째 요소가 모두 크다는 의미입니다.
- 서로 다른 공간에서 동시에 활성화 되는 특징이 무엇인지 2차 모멘트를 통해 어느정도 포착해 낼 수 있는 것입니다.
- 이러한 과정을 H x W grid에 전부 수행하고 결과에 대한 평균을 계산하면 C x C Gram Matrix를 얻게 됩니다.
- 이 Gram Matrix를 texture descriptor로 사용합니다.
- Gram Matrix는 주변 공간 정보를 가지지 않습니다.
- 특징들 간의 co-occurrence 만을 포착해 냅니다.
- 제대로 된 공분산 행렬대신 Gram Matrix를 쓰는 이유는 계산 효율성 때문입니다.
Neural Style Transfer
- 위에서 배운 Gram Matrix이용한 Texture Synthesis을 이용하여 Style Transfer를 만들수 있습니다.
![]()
![]()
- 다음과 같이 3가지 입력을 네트워크에 넣어줍니다.
- Content Image : 최종 이미지가 어떻게 생겼으면 좋겠는지를 나타냄
- Style Image : 최종 이미지의 Texture가 어땟으면 좋겠는지를 나타냄
- Output Image : Content Image와 Style Image를 합쳐 만든 이미지 출력
- 최종이미지를 만드는 과정에서 2가지 loss를 사용합니다.
- 최종이미지와 Content Image 사이에 feature reconstruction loss
- Style image의 gram matrix loss
- 두 loss에 대한 hyperparameter 조정으로 어느부분에 더 초점을 맞출지를 선택할 수 있습니다.
![]()
- 이에 대한 학습 결과를 아래와 같습니다.
![]()
![]()
Fast Style Transfer
- 위 Style Transfer는 backprop와 forward를 굉장히 많이 해야 하여 느립니다.
- 이를 해결하는 방법으로 Fast Style Transfer가 있습니다.
- 이 방법은 Style Transfer를 위한 네트워크를 만드는 것입니다.
- Style Image를 고정하고 Content Image만을 입력으로 받아 출력을 구성합니다.
![]()
![]()
- 여러 개의 스타일을 동시에 얻어낼 수도 있습니다.
- Segmentic segmentation과 비슷하게 Downsampling 후 transposed Conv로 Upsampling을 진행합니다
- 여기서 Segmentic segmentation과 다른점은
- 최종 출력이 RGB 이미지 입니다.
- 네트워크 중간에 batch norm 대신에 instance norm을 사용함
![]()

- 최근에는 한가시 스타일 뿐 아니라 여러 개의 스타일을 섞어서도 표현이 가능하다고 합니다.

