소개
- 이 글은 단지 CS231n를 공부하고 정리하기 위한 글입니다.
- Machine Learning과 Deep Learning에 대한 지식이 없는 초보입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
참조
-
https://zzsza.github.io/data/2018/05/18/cs231n-training_neural_networks/
-
https://younghk.netlify.app/posts/cs231n-lec7-training-neural-networks-part-1/
-
https://taeu.github.io/cs231n/deeplearning-cs231n-Neural-Networks/
-
https://taeu.github.io/cs231n/deeplearning-cs231n-Neural-Networks-2/
-
https://taeu.github.io/cs231n/deeplearning-cs231n-Neural-Networks-3/
-
https://datascienceschool.net/view-notebook/f43be7d6515b48c0beb909826993c856/
-
https://mlexplained.com/2018/11/30/an-overview-of-normalization-methods-in-deep-learning/
개요
< Training Neural Networks 1 >
- Activation Functions
- Data Preprocessing
- Weight Initialization
- Batch Normalization
- Layer Normalization
- Instance Normalization
- Group Normalization
- Hyperparameter Optimization
Activation Functions
Activation Function(활성화 함수)는 앞에서 배운 CNN(Convolutional Neural Network) 또는 FC(Fully-Connected Layer)에서 나온 결과를 어떻게 다음 노드로 보낼지를 결정해주는 함수입니다.
보통 non-linear함수를 하며 어떤 값이 들어오면 어떻게 활성화 시킬 것인지를 정하는 것입니다.
이러한 특징으로 활성화 함수의 종류에 따라서 그 값의 형태도 다양합니다.

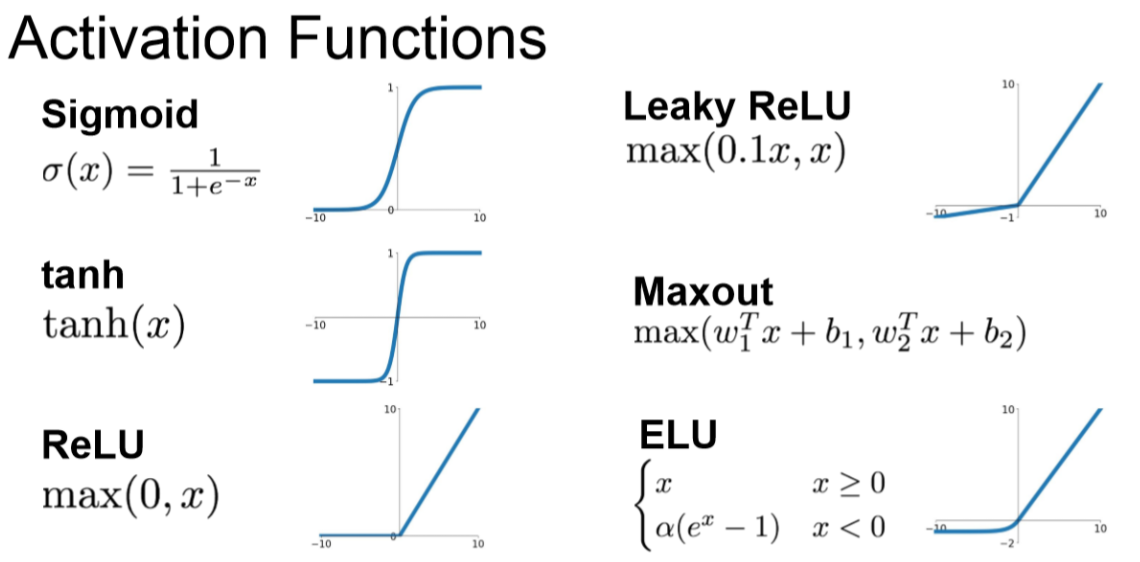
활성화 함수는 아래와 같이 다양한 종류를 가지고 있습니다.
이제 아래 활성화 함수들을 각각 알아보도록 하겠습니다.
Sigmoid 함수
Sigmoid 함수는 아래와 같은 모습을 하고 있습니다.
보통 단순한 단일, 이진 분류 등에서도 많이 쓰이고 있다고 합니다.
하지만 최종 출력에서만 사용합니다.
왜 그럴까요?

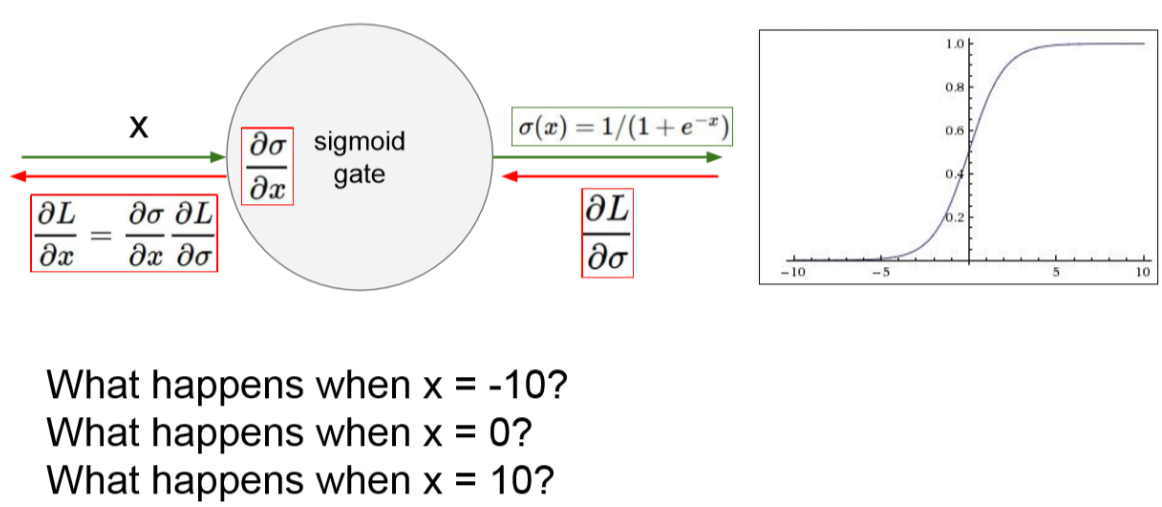
첫번재로 gradient vanishing 문제가 있습니다.

아래와 같은 예시를 봅시다.
-10, 0, 10 일때를 살펴봅시다.
-10과 10과 같은 경우 기울기가 거의 0이 됩니다.
0일 때는 그나마 0에 가깝지 않은 상태를 보여주고 있습니다.
위 결과들을 기반으로 계속 backpropagation을 하게 되면 0과 가까운 값이 계속 곱해지게 됩니다.
그러다 보니 기울기가 0에 매우 가까워져 기울기가 소실되어 버리는 것입니다.
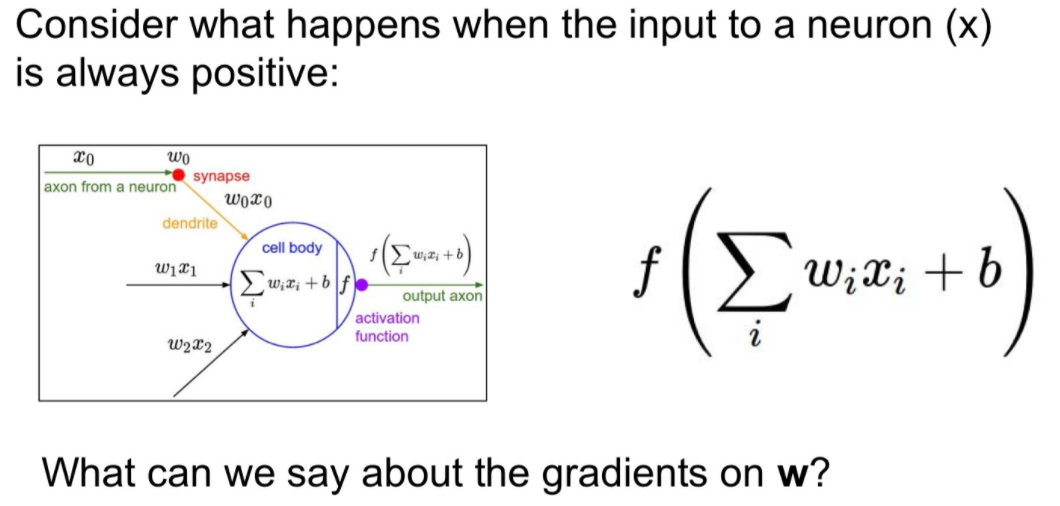
두번째로 zero-centered가 되어 있지 않는 문제입니다.

입력 X값이 모두 양수라고 합시다.
여기서 Local gradient를 계산해보면 Sigmoid의 Gradient는 X 입니다.
따라서 Gradient의 부호는 그저 위에서 내려온 Gradient의 부호와 같게 됩니다.
즉 W가 모두 같은 방향으로만 움질일 것이라는 것입니다.
파라미터를 업데이트 할 때, 다같이 증가하거나 다같이 감소할 것입니다.
이러한 Gradient 업데이트는 4분면중 2개의 영역만 이용하므로 비효율적입니다.
파란색 화살표가 최적의 업데이트인데, 빨간색으로만 움직이므로 수렴하는데 시간이 오래걸린다.

세번째 문제는 exp 연산의 값이 매우 비싼 연산입니다.
그래서 sigmoid는 잘 쓰지 않습니다.
tanh 함수
sigmoid의 Zero centered 문제를 해결한 하이퍼볼릭 탄젠트(tanh)입니다.
하지만 기울기 소실문제와 exp연산 문제가 남아 있습니다.

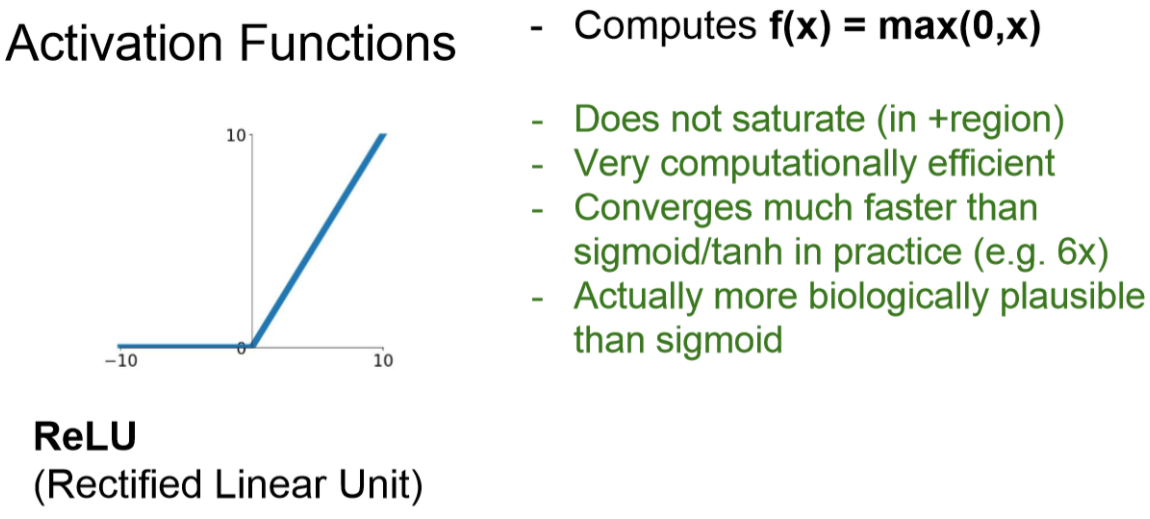
ReLU 함수
아래 그림은 ReLU(Rectified Linear Unit) 입니다.
이것은 가장 많이 사용하는 Activation Function입니다.
아주 간단하게 구현할 수 있습니다.
위에 사용한 sigmoid와 tanh보다 수렴속도가 6배나 빠르다고 한다.
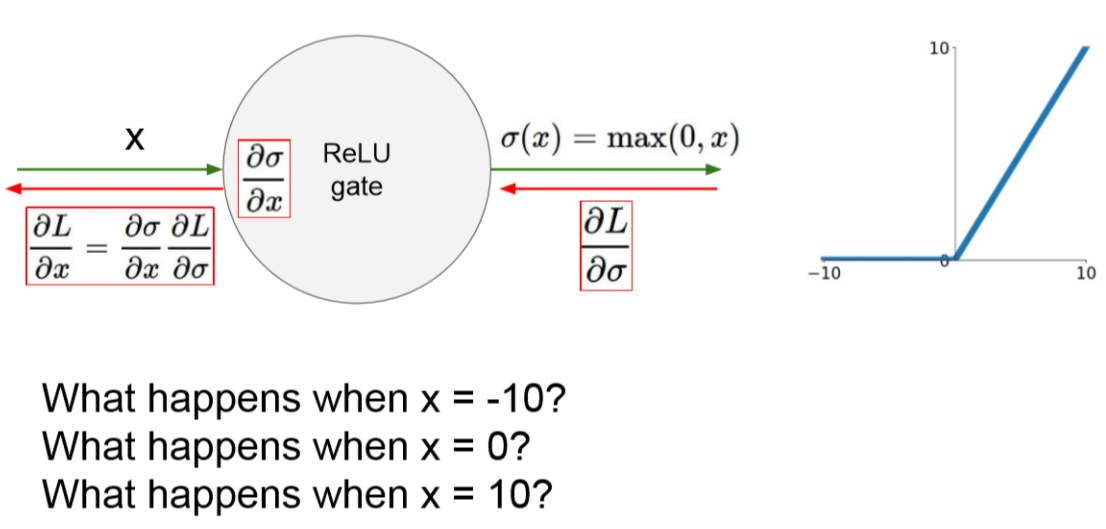
그러나 ReLU 또한 문제가 있습니다.
Zero-centered가 되어 있지 않으며 0 이하 값들은 전부 버리게 되는 것입니다.
아래와 그림에서 x의 값이 0일때와 -10 이게 되면 0이 되게 됩니다.
이렇게 된다면 dead ReLU에 빠지게 됩니다.
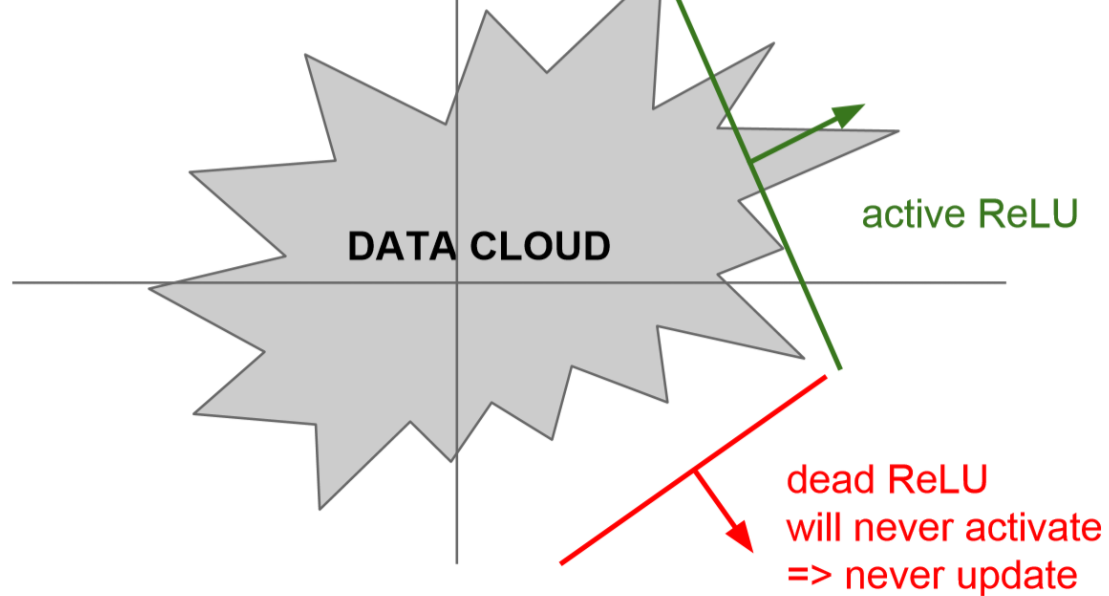
아래 그림과 같이 모든 DATA 에 대해서 0의 값을 가지게 되는 경우가 생기는 겁니다.
이러한 경우가 발생하는 것은 아래와 같다.
-
초기화를 잘못한 경우
- 가중치 평면이 traning data로 부터 멀리 떨어져 있는 경우
-
지나치게 learning rate를 사용한 경우
- Update를 지나치게 크게 해서 ReLU가 데이터의 manifold를 벗어나게 된다.
Leaky ReLU
이러한 문제를 해결하기 위해서 조금이라도 움직임을 주자는 것인데요.
0 이하의 값을 0.01x 값을 줘서 작은 값이라도 주게 하는 것입니다.

PReLU
또한 위 Leaky ReLU를 살짝 변경한 것이 Parametric Rectifier (PReLU) 입니다.
이것은 알파 값을 학습을 통해 찾아가는 방법이라고 생각하시면 됩니다.

ELU
Exponential Linear Units (ELU)로 ReLU의 변형으로 나온 것입니다.
이것도 ReLU의 모든 장점을 가지고 있고 zero mean과 가까운 결과가 나오게 됩니다.
그리고 zero mean 형태가 saturation 되는 데, 이런 saturation이 잡음(noise)에 robust 하다고 합니다. (feature selection과 연관)
exp 계산을 해야하는 것이 단점이라고 합니다.
- 왜 ReLU, ELU는 왜 noise에 robust할까?
- 음의 영역에서 saturate되어 gradient vanishing 되는 부분이 있다. 이때 데이터 전체를 학습하는 것이 아니라 0인 부분이 있어 선택적으로 학습하게 된다.(generalized)

Maxout
max 값을 이용해서 2개의 파라미터를 준 뒤에 좋은 것을 선택하는 network 이다
그런데 연산량이 2배가 되어서 잘 사용되지 않는다고 한다.

Activation 결론
- 일반적으로 딥러닝에서 ReLU와 Leaky ReLU를 많이 사용한다고 합니다.
- Tanh는 RNN과 LSTM에서 자주 사용합니다.
- sigmoid는 절대 사용하지 않는다고 합니다.
Data Preprocessing
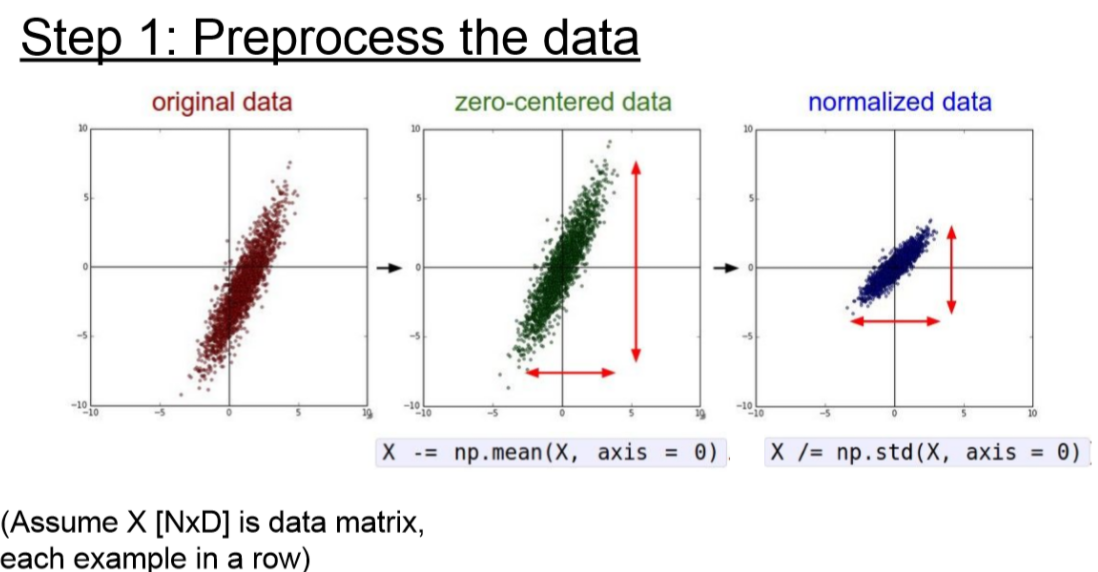
데이터 전처리는 zero-centered, normalized를 많이 사용합니다.
이미지에서는 이미 값이 0 ~ 255로 제한되어 있어서 normalilzation은 사용하지 않고 zero-centered만 사용한다고 합니다.
- 이미지에서 normalization을 사용하지 않는 이유
- 이미지에서 scale이 달라지면 다른 feature이게 때문입니다.
일반적으로 평균 값인 128로 빼준다고 생각하시면 됩니다.
- Scale 조정 (Normalization)
이 부분은 CS231n의 강의노트보다 이해하기 더 쉽고 자세한 설명이 있는 링크를 가져왔습니다.
Scale 조정은 (1) Standard Scaler, (2) Robust Scaler, (3) Minmax Scaler, (4) Normalizer 4가지 방법이 있는데 Scikit-Learn의 전처리 기능을 통해 각 Scaler가 어떻게 구성되어 있는지 참고하시길 바랍니다.
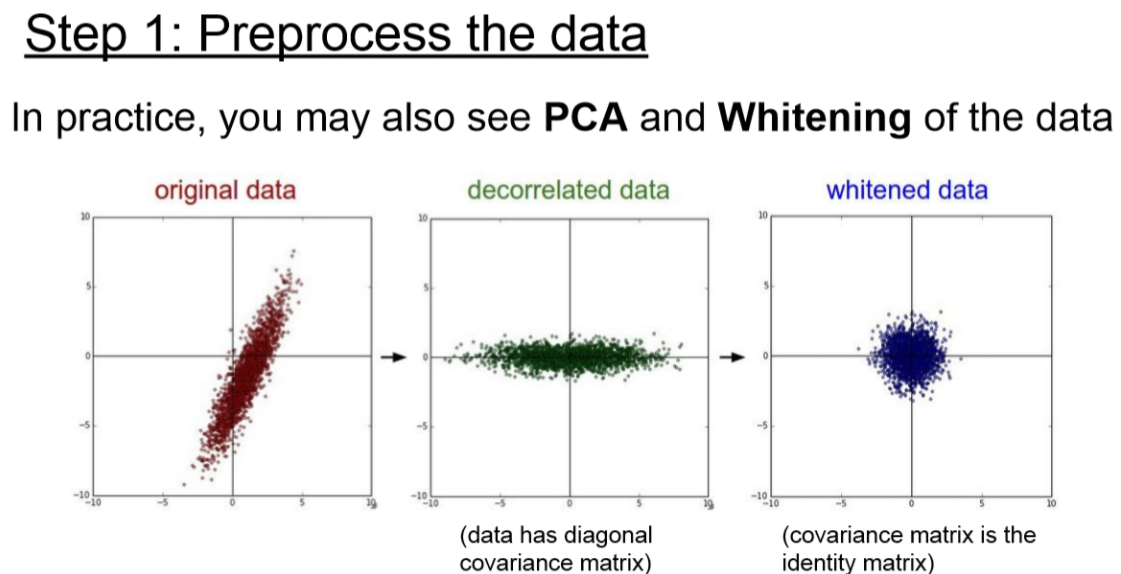
PCA와 Whitening 기법도 있다고하는데 image에서는 잘 쓰이지 않는다고 합니다.
-
Principal Component Analysis(PCA)
- 데이터를 정규화 시키고 공분산(Covariance) 행렬을 만듭니다.
- 공분산 행렬이란 각 구조간 상관관계를 말해주는 행렬입니다.
- SVD factorization으로 상위 중요한 몇 개의 vector들만 이용하여 차원을 축소하는데 사용할 수 있습니다.
-
Whitening
- input의 feature들을 uncorrelated하게 만들고, 각각의 variance를 1로 만들어줌
- 기저벡터 (eigenbasis) 데이터를 아이젠벨류(eigenvalue)값으로 나누어 정규화 하는 기법입니다.
- 이 변환의 기하학적 해석은 만약 입력 데이터의 분포가 multivariable gaussian 분포 라면 이 데이터의 평균은 0, 공분산은 단위행렬(I)인 정규분포를 가집니다.
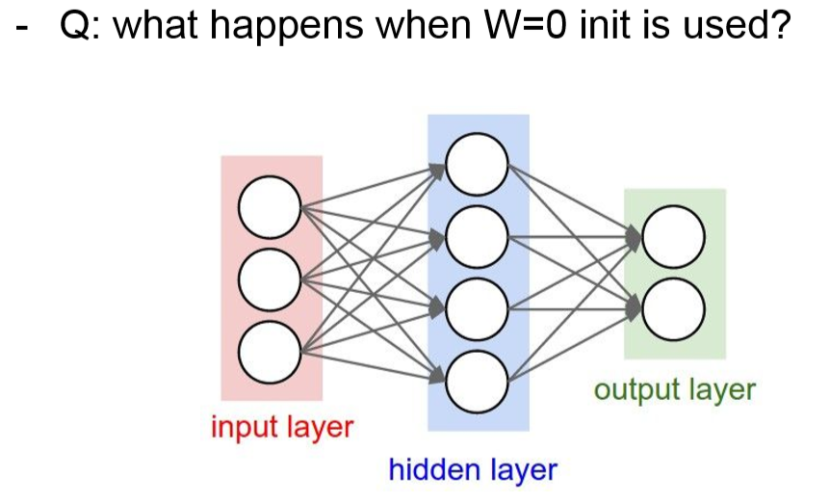
Weight Initialization
만약 Weight 값이 0인 경우에는 어떻게 될까요?
Gradient vanishing이 발생할 겁니다.
작은 랜덤값 초기화
아래와 같이 랜덤값을 0.01로 scale 한 값을 사용하는 방법이 있습니다.
작은 network에서는 잘 작동하지만 깊은 network에서는 문제가 발생합니다.

아래는 각각 500개의 뉴런을 가진 10개의 레이어와 사이사이에 tanh Activation를 사용한 결과입니다.
보시면 알겠지만 레이어가 깊어질수록 weight 값이 전부 날라가게 됩니다.
tanh 그림을 보면 기울기가 0인 지점이 날라가게 됩니다.
기울기가 0이 안되는 지점인 가운데만 살아남게 됩니다.

그럼 0.01 scale를 하지 않고 사용하면 어떻게 될까요?
아래 그림과 같이 -1과 1 값을 포화가 되어버리고 맙니다.

Xavier initialization
Xavier initialization은 위에서 고정된 크기로 scaling을 해주었다면,
여기서는 노드의 개수(fan_in)로 normalized를 하자 입니다.
이렇게 하면 학습이 잘 되는 것을 볼 수 있습니다.

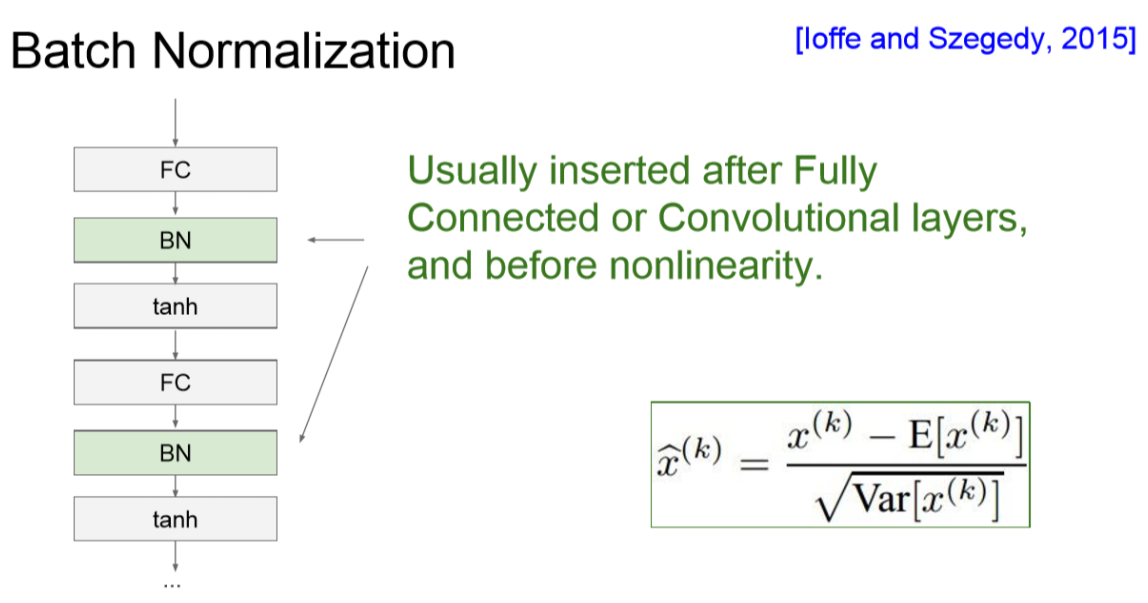
Batch Normalization
우리는 데이터가 gaussian range에서 activation이 꾸준히 잘 되기를 원하고 있습니다.
이러한 착안점에서 제안된 것이 Batch Normalization입니다.
이를 통해 training 하는 과정 자체를 전체적으로 안정화시켜 주는 것입니다.

이것은 internal covariance shift를 방지합니다.
network 각 층마다 input의 distribution이 달라지는 것을 방지합니다.

아래 그림은 일반적으로 activation 전에 잘 분포되도록 한 뒤에 activation을 진행할 수 있도록 해줍니다.
그래서 FC --> BN --> Activation으로 들어가게 되는 겁니다.
하지만 여기서 BN을 사용하면 input은 항상 unit Gaussian이 되게 되는데
이게 적합한 것인지 아닌지는 알 수 없습니다.
- 의문점
- Activation function을 relu를 사용한다면?
- 가중치의 크기를 증가시킬때 더 나은 성능을 가진다면?
이러한 문제를 해결하기 위해서 여기서 감마와 베타 값이 주어지게 됩니다.
감마 값으로 BN의 Variance 값을 조절하며, 베타 값으로 평균 값을 조절할 수 있게됩니다.
그리고 이 감마와 베타 값을 학습의 Hyperparameter로 사용하여 알맞은 값을 얻어가도록 합니다.
참고로 감마 값이 표준편차이고, 베타가 평균 값이면 BN를 하지 않는 것과 같습니다.
감마:Scaling베타:Shifting

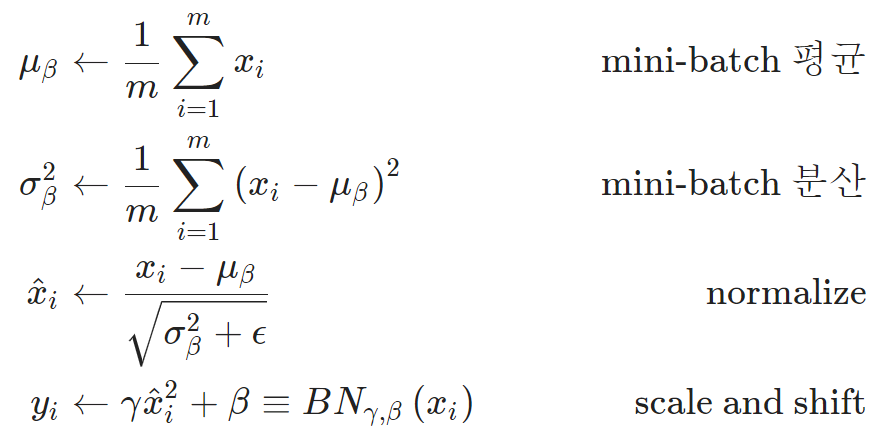
보통 BN을 하면 Dropout을 안써도 된다고 합니다.
그 이유는 Dropout은 랜덤하게 값을 꺼내주기 때문입니다.
BN도 마찬가지로 배치마다 값이 조금씩 다르게 들어가고 값이 계속 바뀌게 되어 노이즈가 적어지게 된다고 합니다.
또한 BN은 선형변환으로 기존의 공간적인 구조가 잘 유지됩니다.
Notice) CONV에서 Batch Normalization 할때 주의사항
-
기존에 Wx + b 형태로 weight를 적용해 주는데 BN의 Beta 값과 중복된다.
-
고로 Wx + b 의 bias 값을 사용하지 않아도 된다.
-
장점
- Network에
Gradient flow를 향상시킴 높은 learning rate를 사용해도 안정적인 학습가능Weight 초기화의 의존성을 줄임Regularization기능도 하여dropout의 필요성을 감소시킴Test 시에 overhead가 없다. (학습된 것을 사용만 함)
- Network에
-
Test할땐 Minibatch의 평균과 표준편차를 구할 수 없으니
Training에서 구한 고정된 Mean과 Std를 사용함
Layer Normalization
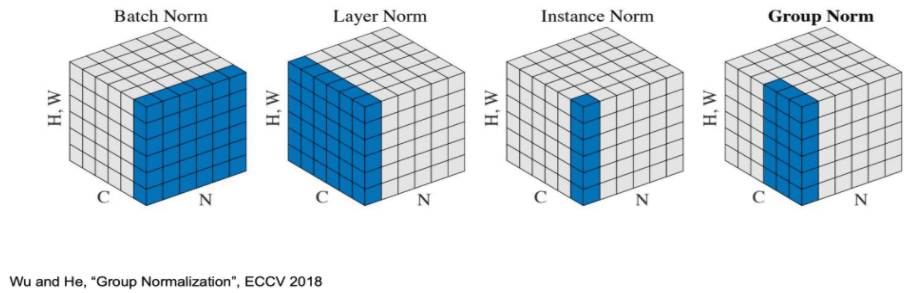
Layer Normalization(LN)은 Batch Normalization(BN) 비슷하지만 다르다.
BN은 Batch들과 W, H 대해서 Normalization을 진행했다면,
LN은 한 Batch에서 Depth와 W,H 대해서 Normalization을 한 것이다.
고로 LN은 각 Batch들에 대해서는 신경쓰지 않고 BN과 다르게 각 Depth에 대한 정보를 모두 보고 Normalization을 진행한다.
BN과 LN의 식은 아래와 같다.
식을 보면 형태는 같고 i와 j만 바뀐 것을 볼 수 있다.

위 식에 대한 좀더 직관적인 이해는 아래와 같다.
아래는 Batch Normalization과 Layer Normalization의 차이를 보여준다.
실험적으로 RNN에서 좋은 성능을 가진다고 한다.

Instance Normalization
Instance Normalization 은 Layer Normalization 에서 한 걸음 더 나아간 것입니다.
Layer Normalization은 (Width, Height, Channel)에 대한 모든 성분을 보고 Normalization을 진행 진행했다면,
Instance Normalization은 각 Channel에서 (Width, Height)에 대해 Normalization을 진행하는 것입니다.
이는 이미지에 대해서만 가능한 정규화이고, RNN 에서는 사용할 수 없습니다. style transfer 에 있어서 배치 정규화를 대체해서 좋은 성능을 내는 것으로 보이며 GAN 에서도 사용되었다고 합니다.
Group Normalization
그룹 정규화(group normalization) 은 채널 그룹에 대한 평균 및 표준 편차를 계산합니다.
이는 layer normalization 과 instance normalization 의 조합인데,
모든 채널이 단일 그룹(G=C)이 된다면 layer normalization 이 되고,
각 채널을 다른 그룹에 넣게 될 경우(G=1) instance normalization 이 됩니다.
그룹 정규화는 ImageNet 에서 batch size 32 인 batch normalization 의 성능에 근접하며, 더 작은 크기에서는 성능이 더 좋게 나타난다.
또한, 높은 해상도의 이미지를 사용하여 물체를 감지(detection)하거나 분할(segmentation)하는 문제는 메모리 문제로 배치 크기를 늘리기 어려운데 이러한 문제에 대해 그룹 정규화는 매우 효과적인 정규화 방법이다.
- 그룹 정규화의 장점
- layer normalization보다
각 채널의 독립성을 보장해주며모델의 유연성(flexibility)을 줄 수 있습니다.
- layer normalization보다
아래 그림은 이미지의 resolution은 H,W이 하나의 차원으로 표현되었으며, C는 Channel axis(채널의 개수), N은 batch axis(배치의 개수) 이다.
Hyperparameter Optimization
하이퍼 파라미터를 찾아갈때 적절한 learning rate를 사용해야합니다.
learning rate의 크기에 따라서 다른 분포를 가지고 있고
우리가 원하는 learning rate는 빨간색으로 너무 크지도 않고 작지도 않은 learning rate 값을 설정해야합니다.

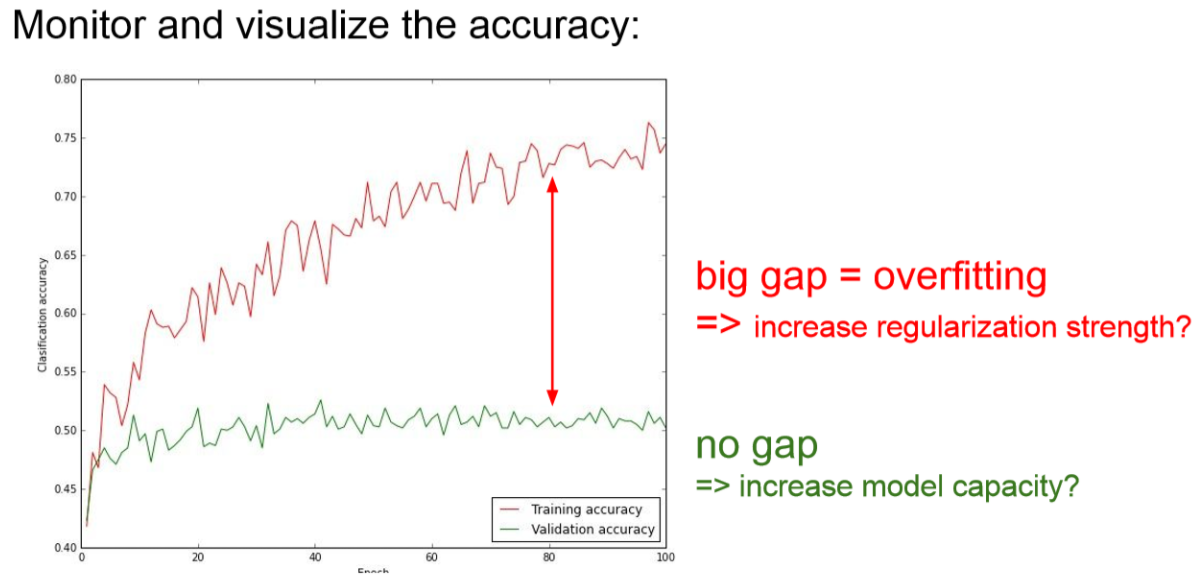
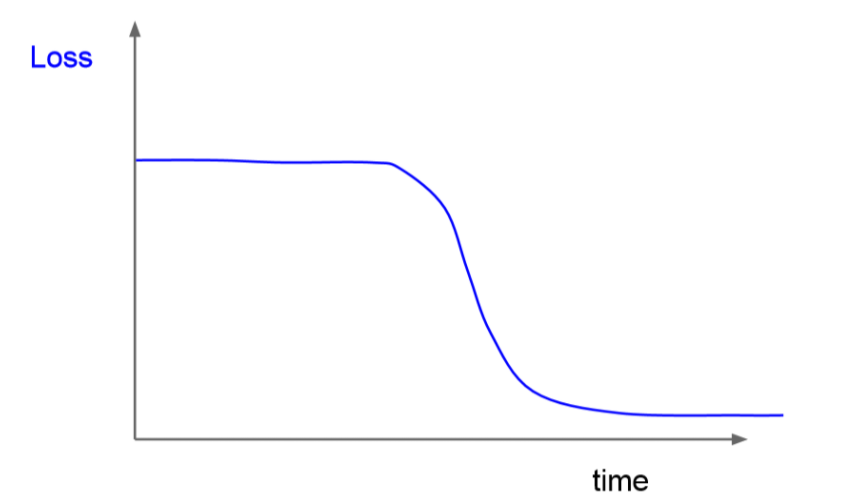
가끔은 이런 그래프를 볼 수 있는데 이런 경우에는 initialization이 좋지 않았던 것입니다.
아래 처럼 우리는 빨간색 선과 초록색 선의 Gap이 없어져야 합니다.
이 gap이 커지게 되버리면 overfitting(과적합)이 걸린 것입니다.
오버피팅이 되면 실제 데이터 셋에서 잘 동작이 되지 않습니다.