소개
- 이 글은 단지 CS231n를 공부하고 정리하기 위한 글입니다.
- Machine Learning과 Deep Learning에 대한 지식이 없는 초보입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
참조
-
https://strutive07.github.io/2019/03/17/cs231n-lecture-7-1,-Traning-Neural-Networks-2.html
-
https://strutive07.github.io/2019/03/17/cs231n-lecture-7-2,-Traning-Neural-Networks-2.html
-
https://strutive07.github.io/2019/03/17/cs231n-lecture-7-3,-Traning-Neural-Networks-2.html
-
https://strutive07.github.io/2019/03/17/cs231n-lecture-7-4,-Traning-Neural-Networks-2.html
-
https://strutive07.github.io/2019/03/17/cs231n-lecture-7-5,-Traning-Neural-Networks-2.html
-
https://zzsza.github.io/data/2018/05/20/cs231n-training_neural_networks_2/
-
https://humanbrain.gitbook.io/notes/notes/vision/fractional_max-pooling
개요
< Training Neural Networks 2 >
Introduction
이번에는 저번에 배운 Optimization과 Regularization에 대해서 더 깊게 배우게 됩니다.
또한 Dropout, transfer learning등을 배우게 됩니다.
그럼 시작하겠습니다.
Optimization
SGD의 문제점
일반적으로 우리는 vanilla gradient descent를 하게 되면 아래 식처럼 weights를 update해줍니다. 여기서 mini batch 단위로 끊어서 하는 것이 SGD 였습니다.
근데 SGD에는 몇가지 문제가 있습니다.
# Vanilla Gradient Descent
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # perform parameter update
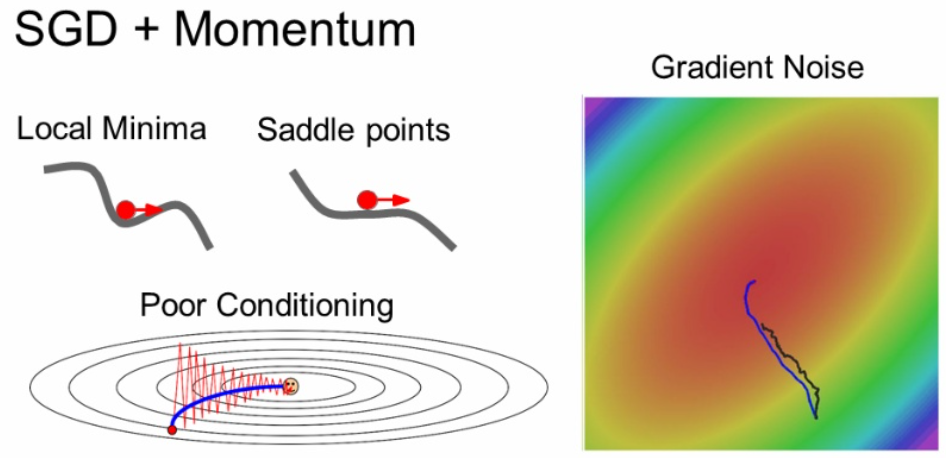
아래 그림과 같이 loss function이 타원모양의 분포를 가진다고 해봅시다.
만약 빨간색 점에서 이모티콘이 있는 지점까지 찾아간다면,
X축 방향은 완만하고, Y축방향은 급격하여서 빨간색 선 처럼 매우 크게 방향이 튀면서 지그재그 형태로 지점을 찾아가게 됩니다.
이렇게 되면 매우 느립니다.

다음문제로는 loacl minima와 saddle point 문제가 있습니다.
두 지점 모두 순간적으로 기울기가 0이 되는 지점입니다.
또한 local minima는 global minimum를 찾지 못하고 멈추게 됩니다.
여기서 local minima에 대한 좀 재미있는 이야기가 있습니다. 다크 프로그래머님 글 참고.
간단하게 요약해본다면, 일반적으로 Deep learning에서 local minima와 saddle point에 대한 생각을 할때, local minima가 더 중요하고 고질적인 문제라고 생각했습니다.
하지만 실제적으로 고차원 관점에서 본다면 모든 주변 gradient 양수인 경우를 찾기는 어렵고 대부분 learning에 문제를 일이키는 주된 원인은 saddle point 라는 점입니다.
이에 대한 설명은 다크 프로그래머님 글을 참고하시면 될 것같습니다.
이 강의에서 그렇게 중요한 포인트는 아니니 그냥 이런게 있구나 하고 넘어가시면 됩니다.

그리고 약간의 noise가 있는 입력에 대해서 SGD를 적용하면 아래와 같은 결과가 나옵니다.
global minimum에 가지 못하고 멈추며 안 이쁘게 나온걸 볼 수 있습니다.
# SGD
while True:
dx = compute_gradient(x)
x += learning_rate * dx
Momentum
이러한 문제를 해결하기 위해서 모멘텀(momentum)이라는 개념이 나오게 됩니다.
기존 SGD에서 가속도를 주는 것입니다.
아래 식을 보면 기존 SGD와 다르게 vx와 rho 값을 사용하는 것을 볼 수 있습니다.
vx는 velocity(속도)값, rho는 마찰계수로 생각하면 됩니다.
보통 rho 값은 0.9~0.99를 준다고 합니다.
vx = 0
while True:
dx = compute_gradient(x)
vs = rho * vx + dx
x += learning_rate * vx
SGD와 Momentum를 비교한 그림입니다.
파란색 선이 Momentum의 결과를 나타내며 SGD보다 부드러운 결과를 가집니다.
또한 가속도의 영향을 받으므로 local minima와 saddle points에도 SGD보다 안전합니다.
Nesterov Momentum
Momentum의 velocity 개념을 좀 더 나아간 Nesterov Momentum이라는 방법도 있습니다.
기존 Momentum은 아래 왼쪽 그림과 같이 현재 입력값(빨간점)에서 구한 Gradient와 Velocity를 더하여 다음 step를 구합니다.
하지만 Nesterov Momentum은 아래 오른쪽 그림과 같이 현재 입력값에서 Gradient 값을 구하는 것이 아닌 Velocity 만큼 움직인 이후에 Gradient를 구하고 이를 더하여 Step를 구합니다.
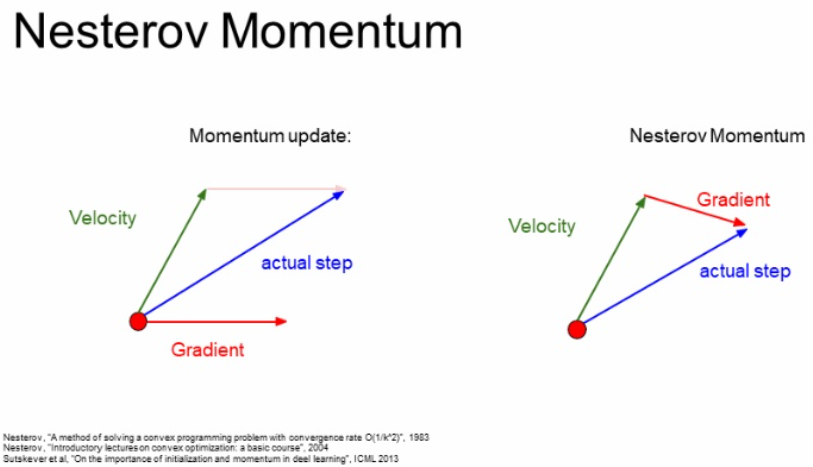
수식은 아래와 같이 Gradient의 xt에 추가적으로 velocity 값인 rho * vt term을 함께 넣어주는 것을 볼 수 있습니다.

일반적으로 Nesterov는 Convex function(볼록 함수)에서 굉장히 뛰어난 성능을 보입니다.
하지만 고차원적인 함수인 Neural Networks 들에 대해서는 별로 성능이 좋지 않다고 합니다.
아래 코드는 속도를 업데이트를 나중에 하는것이 아니라,
그냥 미리 다음에 예측할 velocity를 더하여 업데이트 하여 코드를 arrange 한 형태입니다.
위에 수식을 이해하셨으면 간단하게 집고 넘어가시면 됩니다.
# Nesterov Momentum
dx = compute_gradient(x)
old_v = v
v = rho * v - learning_rate * dx
x += -rho * old_v + (1 + rho) * v
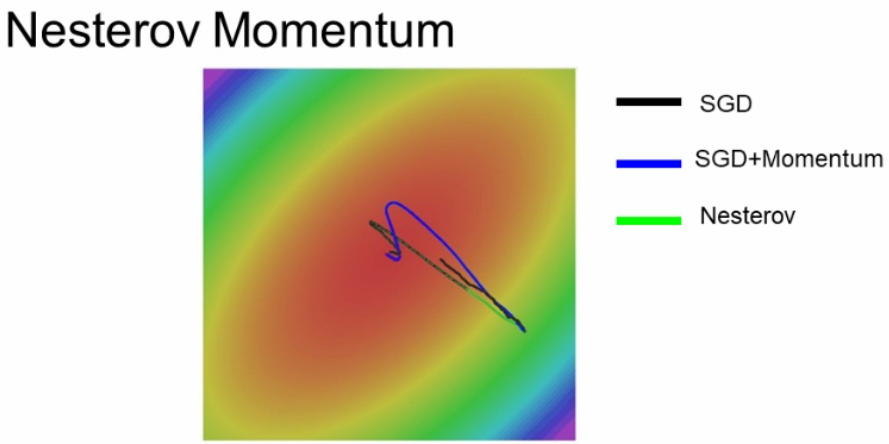
Nesterov Momentum의 실험결과는 아래 초록선과 같습니다.
하지만 실제로는 거의 이렇지 않다고 합니다.
AdaGrad
다른 방법으로 AdaGrad(아다그라드)가 있습니다.
이 방법은 각각의 매개변수에 맞게 맞춤형 매개변수 갱신 알고리즘 입니다.
여기서 A는 adaptive로 적응적으로 학습률을 조정하는 의미입니다.
아래 코드를 살펴보면 다음과 같습니다.
- 현재 x에 대한 Gradient를 구합니다.
- 구한 Gradient를 제곱한다. 이는 각 수직성분들에 대한 곱의 합으로 표현됩니다.
- 이후 구한 grad_squared 값의 sqrt 이후 이 값으로 나누어 각 요소에 adaptive하게 업데이트 할 수 있게 됩니다.
# AdaGrad
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared = dx * dx
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
이 수식에서 1e-7을 더하는 것은 grad_squared 값이 0인 경우를 없애기 위한 방법입니다.

학습 중에는 전에 나왔던 모든 gradient 값의 제곱을 더해주는 형태가 됩니다.
하지만 이러한 방법은 분모가 점점 커지게 되어 step을 진행할 수록 값이 작아집니다.
이것은 처음에 빨랐다가 느려지는 형태이고, 앞에서 Nesterov Momentum과 같이 Convex function에 대해서 좋은 경과를 가집니다. 하지만 이외의 경우 도중에 멈출 수 있습니다.
이에 대한 대안으로 RMSProp가 나오게 됩니다.

RMSProp는 AdaGrad와 똑같이 Gradient의 제곱을 사용합니다.
하지만 이 값을 계속 누적하는 것이 아니라 decay_rate를 곱해줍니다.
위에서 배운 Momentum의 수식과 비슷하지만 Gradient의 제곱을 누적한다는 점이 다릅니다.
보통 decay_rate는 0.9 혹은 0.99를 사용합니다.
이는 adagrad와 매우 비슷하게 step의 속도를 가속과 감속이 가능합니다.
하지만 Momentum과 같이 앞에서 온 값을 적용시켜 주어 속도가 줄어드는 문제를 해결할 수 있습니다.
# RMSProp
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared = decay_rate * grad_squared + (1 - decay_rate) * dx * dx
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)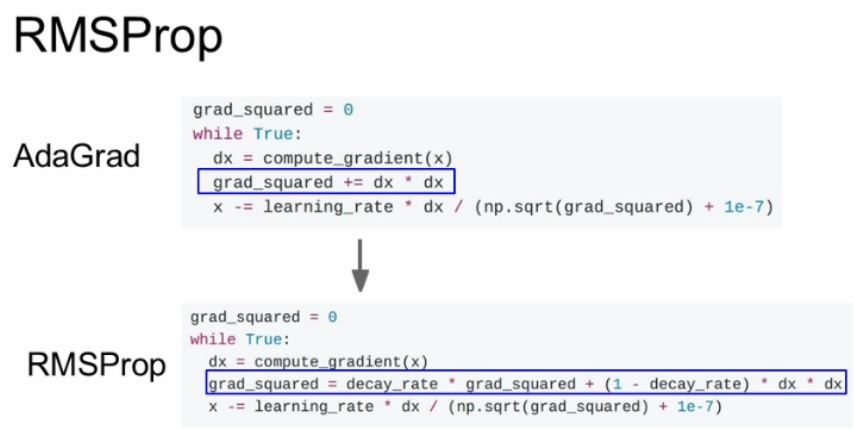
아래 그림의 빨간색 선이 RMSProp의 결과 입니다.
SGD는 너무 느리게 가며, Momentum은 너무 튀었다가 옵니다.
RMSProp는 어느정도 우리가 원하는 이상적인 방향으로 갑니다.

Adam
자 위에서는 크게 2개의 방법에 대해 배웠습니다.
Momentum을 이용한 방법과 Adaptive를 적용한 방법입니다.
근데, 이 둘다 좋은 방법입니다. 이러한 관점에서 2개를 합쳐서 사용한 것이 Adam입니다.
아래 그림은 Adam의 almost 버전입니다. 완전한 Adam은 아니죠
Adam은 Momentum과 Adaptive를 모두 사용한다고 했었죠?
먼저 first_moment는 Momentum을 나타내며,
second_moment는 Adaptive를 나타냅니다.
이후 분자에는 Momentum 값을, 분모에는 RMSprop의 Adaptive값을 사용하여 x 값을 구하게 됩니다.
마치 모멘텀과 RMSProp을 합친 것과 같죠.
# Adam (almost)
first_moment = 0
second_moment = 0
while True:
dx = compute_gradient(x)
first_moment = beta1 * first_moment + (1 - beta1) * dx
second_moment = beta2 * second_moment + (1 - beta2) * dx * dx
x -= learning_rate * first_moment / (np.sqrt(second_moment) + 1e-7)
하지만 이러한 방법은 초기 step에서 문제가 있습니다.
second_moment 값이 초기에 굉장히 작은 값일 수 있습니다.
이러한 경우 이 값이 분모에 있기 때문에 update step에서 값이 튀어서 이상한 곳으로 튀어 버릴 수 있다고 합니다.
이러한 문제를 해결하기 위해서 추가적으로 bias correction term을 추가합니다.
이것은 update할 때에 현재 step에 맞는 적절한 bias를 추가하여 값이 튀지 않도록 하는 것입니다.
정확하게는 잘 모르겠지만, beta1가 0.9 beta2가 0.99인 경우 처음에 두 값이 차이가 10배 이상 난다. 이러한 부분을 초기에는 보정하여 사용하고 이후에는 이 비율을 그대로 사용하는 방법같다.

이 그래프에서 보라색이 Adam의 결과 입니다.
Adam이 가장 좋은 효과를 보이고 실제로도 많이 사용합니다.

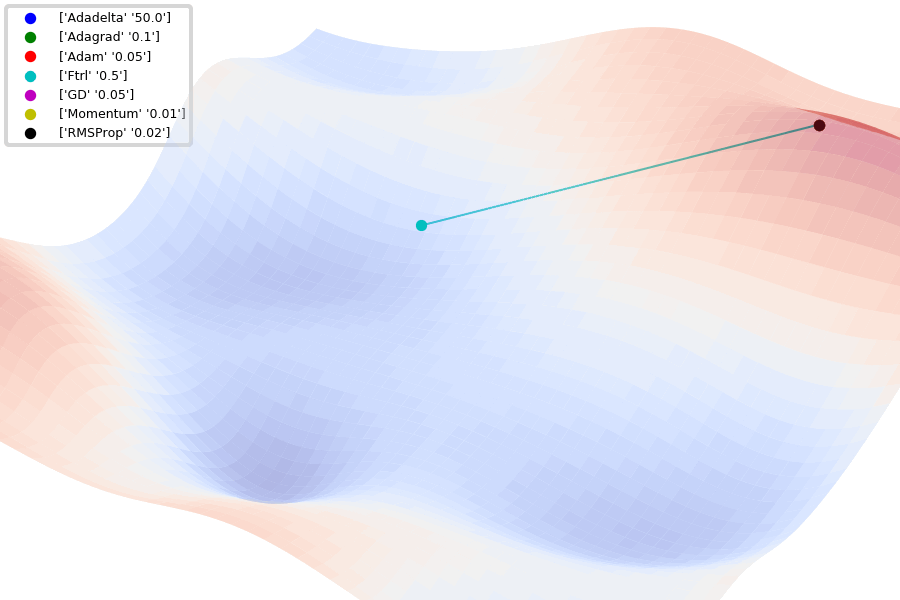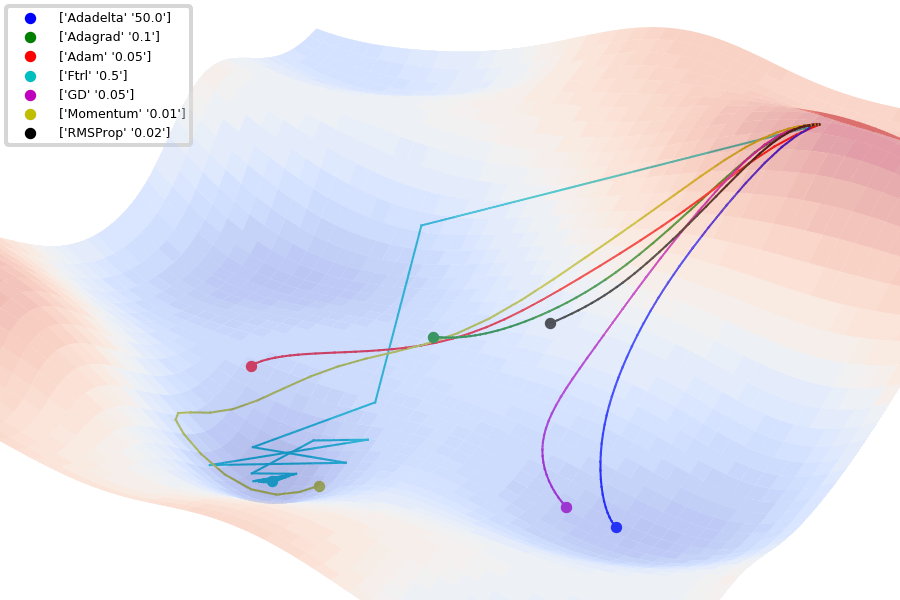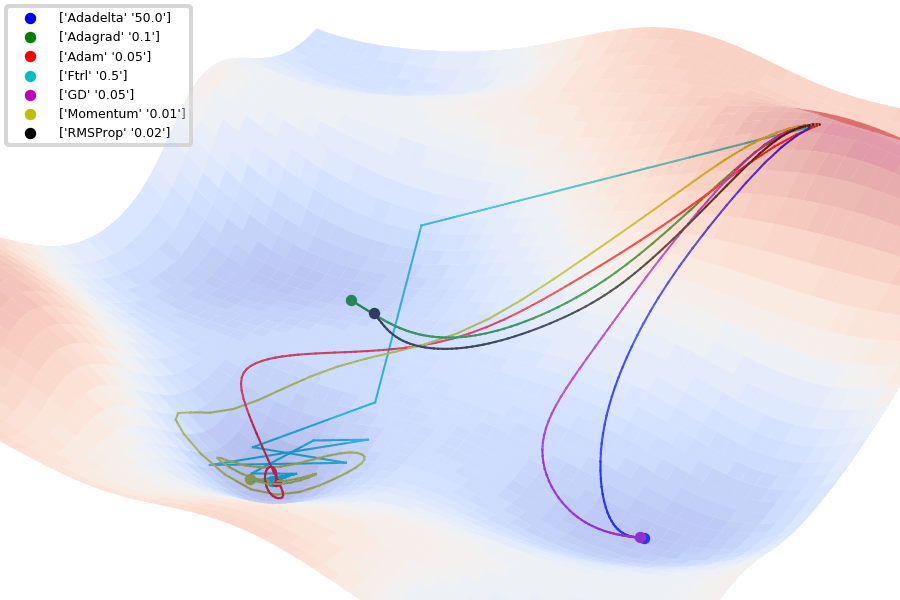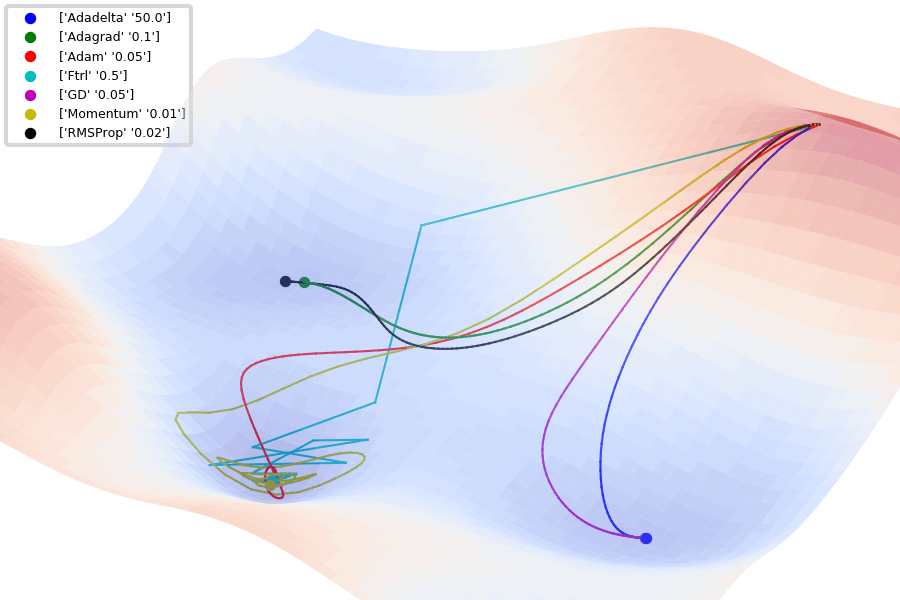
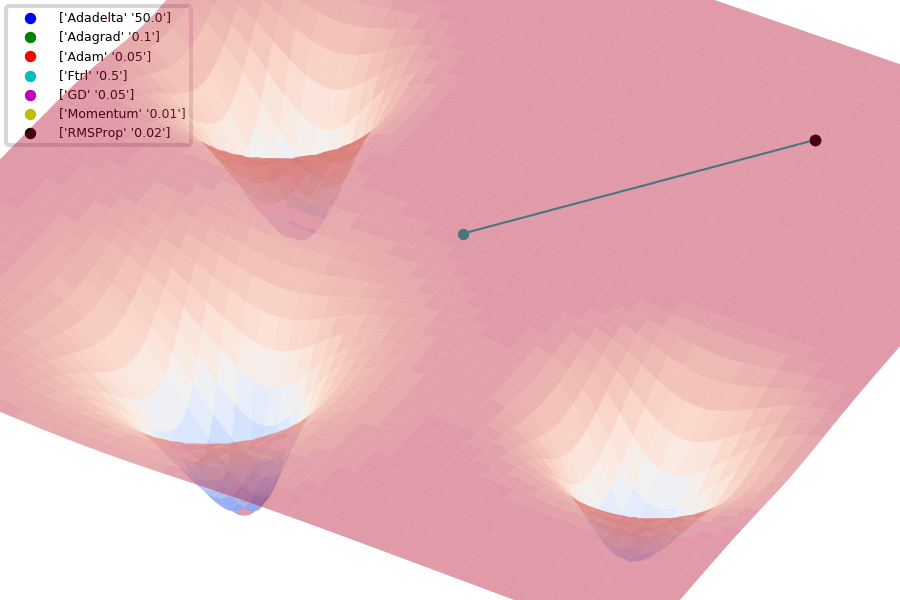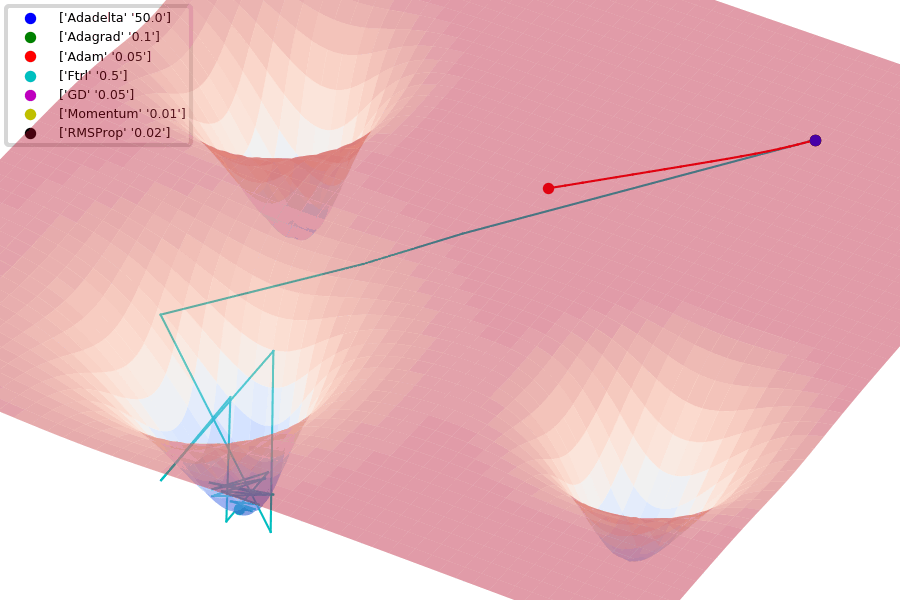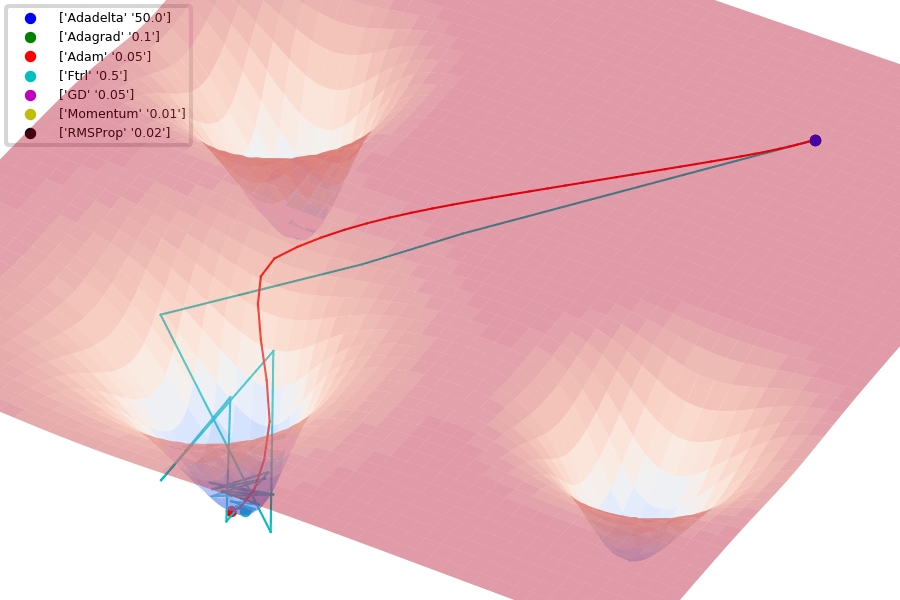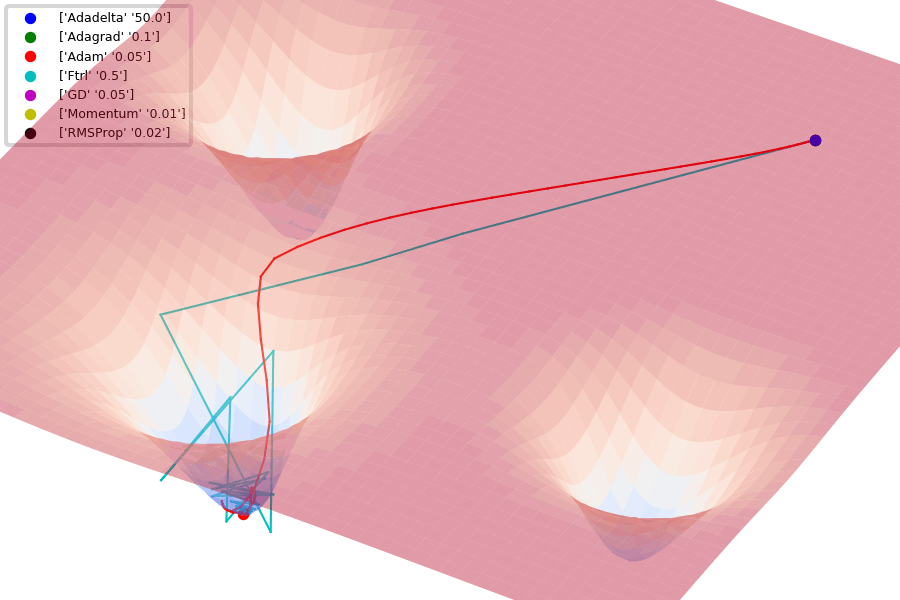
Compare Optimization
이 사이트에서 그림을 참조했습니다.
아래는 Optimizer에 따른 수렴 분포를 보여줍니다.
Adam이 없어서 아쉽지만... 다른 것이라도 잘 살펴봅시다.

아래 그림은 안장점에서 Optimizer 비교를 보여줍니다.
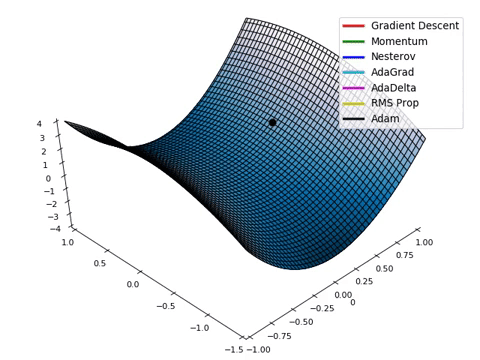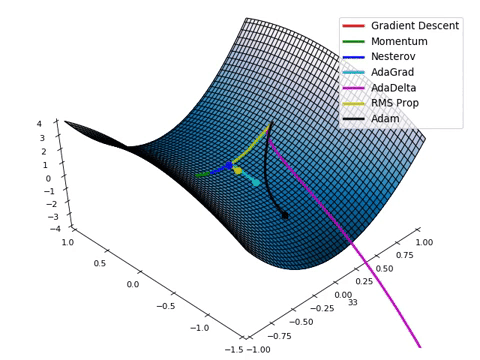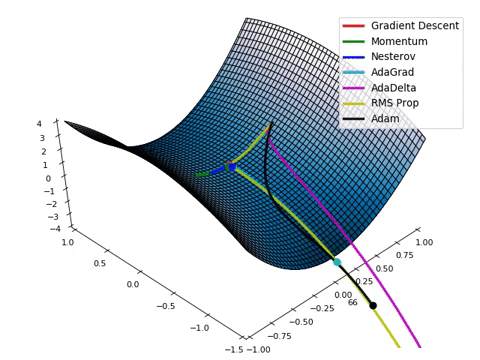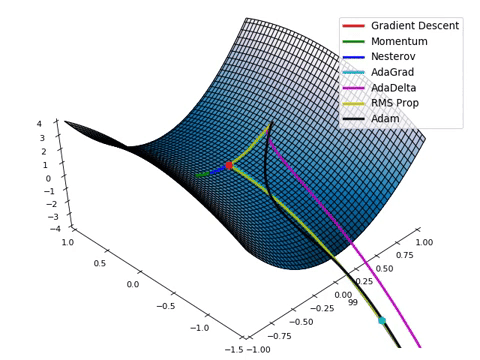

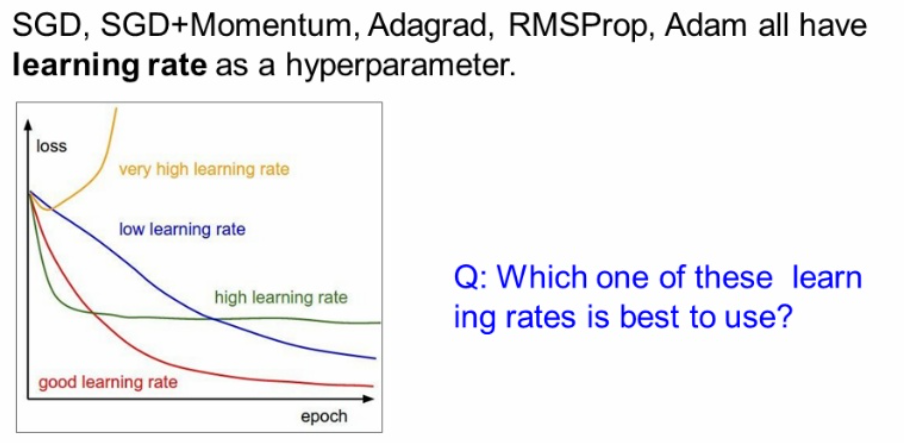
Tuning learning rate
이전 챕터에서 learning rate의 크기에 따라서 다른 loss 분포를 가지는 것을 배웠습니다.
너무 낮으면 느리고 너무 높으면 튀고, 적절한 learning rate를 찾는 것이 쉽지 않습니다.
여기서는 좋은 learning rate 적용하는 여러 예시를 다룹니다.
learning rate decay
이 전략은 learning rate를 학습이 진행됨에 따라서 learning rate를 줄이는 전략입니다.
각 step에 따라서 꾸준히 줄일 수 도 있으며, 일정 간격 마다 줄이는 방법을 사용할 수도 있습니다.

아래 그림을 보면 loss가 완만해지다가 다시 내려가는 것을 반복합니다.
여기서 내려가는 부분이 Learning rate를 decay하는 곳입니다.
이 그림은 Resnet 논문에서 나왔다고 하며, 이 방법은 Step decay learning rate를 사용한 것입니다.
이러한 decay 방법은 Adam 보다는 Momentum에서 자주 쓴다고 합니다.
그리고 이 learning rate decay는 second order hyperparameter라고 합니다.

Second Order Optimization
지금까지는 아래와 같이 테일러의 1차 근사법인 first-order optimization을 사용했습니다.
우리가 현재 빨간색 점에 있으면 이 지점에서 기울기 값을 찾고 step만큼 움직입니다.
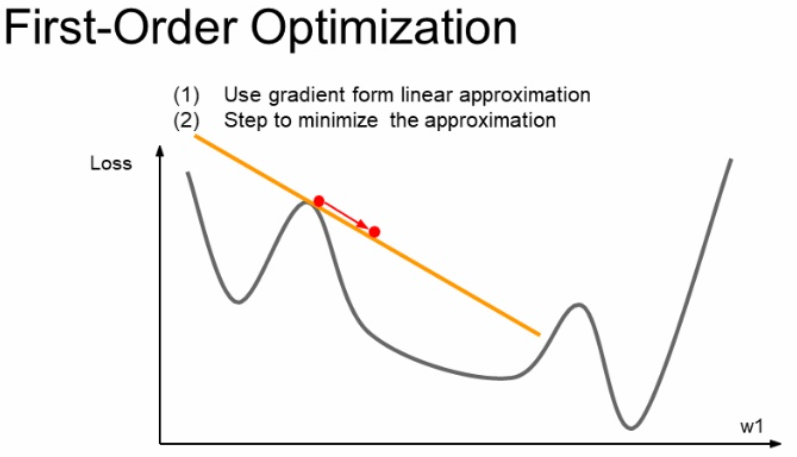
여기서는 아래 그림과 같이 Second-order optimzation(2차 근사)에 대해서 소개합니다.

아래 그림은 테일러 급수의 2차 근사식 식을 보입니다.
이 방법은 hyperparameter와 learning rate를 필요로 하지 않는 방법입니다.
말로 듣기에는 정말 좋아보입니다.
이 좋은게 있는데 왜 First-Order Optimzation과 hyperparameter 왜 생각해야 하지 싶을 수 있습니다.

이 Second-Order Optimization 방법은 2차 미분 값은 Hessian Matrix 값을 계산해야합니다.
이 값은 O(N^2)의 메모리 공간을 필요로 하고 O(N^3)의 Time Complexity를 가집니다.
여기서 보통 딥터닝의 파라미터 값은 수천만개 이상인 경우가 많으므로 메모리에 올리기 벅차며 느립니다. 그래서 잘 안쓴다고 합니다.
N이 작은 경우는 다르다고한다. learning step를 K번 한다고 하면, first-order는 O(N^2K), second-order는 O(N^3)으로 더 빠른 경우도 있다고 한다.

위에서 모든 Batch 값을 사용하여서 찾아가는 방법을 BGFS 이라고 합니다.
여기서 Full Batch 대신에 L-BFGS 알고리즘을 사용하는 방법도 있습니다.
하지만 이 방법은 mini Batch를 사용하지 못해서 실제로 적용하기에 무리가 있습니다.

Ensemble
이제 최적화 하는 방법들에 대해서 간단하게 배웠습니다.
이제 우리가 이 방법을 이용하여 학습을 한다고 생각해봅시다.
아래 그림은 학습이 진행됨에 따라서 Training 데이터에 대해서는 잘 학습되고 있지만 Validation 데이터에 대해서 학습이 잘 되고 있지 않습니다.
이러한 Training과 Validation가 학습 차이를 보이는 것을 Overfitting이라고 배웠습니다.
이러한 해결책으로 Model ensembles과 Regularization 등이 있으며 먼저 Ensembles(앙상블)에 대해 다뤄보도록 합시다.
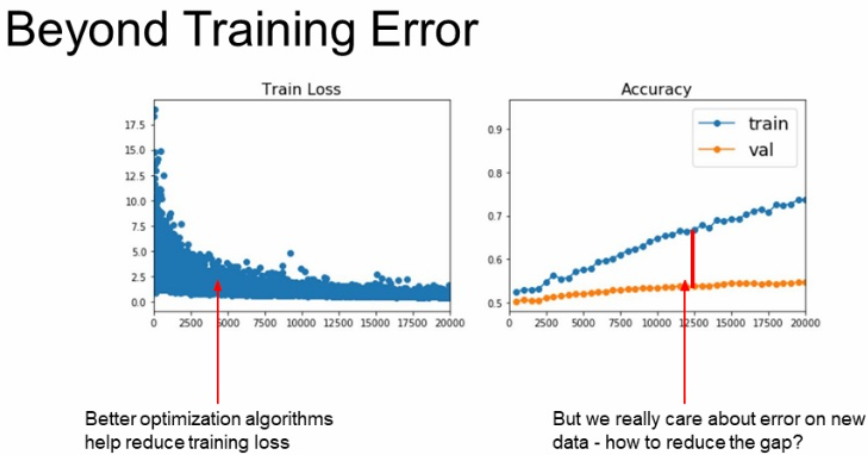
Ensemble Tips and Tricks Multi model
Ensemble(앙상블)하는 방법은 여러가지 방법이 있습니다.
하나씩 차근차근 알아가봅시다.
먼저 Multi model 를 사용하는 방법이 있습니다.
각각의 여러 독립적인 모델들을 학습시키고, 이 모델들을 test time에서 동시에 이용하는 것입니다.
한 test에 대한 여러 결과의 평균을 결과로 사용하는 것입니다.
이것은 약 2% 정도의 성능 보정이 가능하다고 합니다.
너무 적네? 라고 생각할 수 있지만, 90%이상대로 가면 1~2% 올리는게 쉽지 않은데 보통 이럴때 앙상블을 많이 사용한다고 합니다.

Ensemble Tips and Tricks Snapshot
조금 더 창의적인 방법이 있습니다.
모델을 독립적으로 학습시키는게 아니라 학습 도중 중간 학습 모델들을 저장(snapshot)하고 앙상블로 사용할 수 있다고 합니다.
특정 구간에서 train할때는 여러 모델을 사용하고, test에는 여러 snapshot을 평균을 내어 사용하겠다는 것입니다.
이 앙상블 모델 방법은 모델을 그만큼 더 학습해야하기 때문에 시간이 훨씬많이 걸립니다.
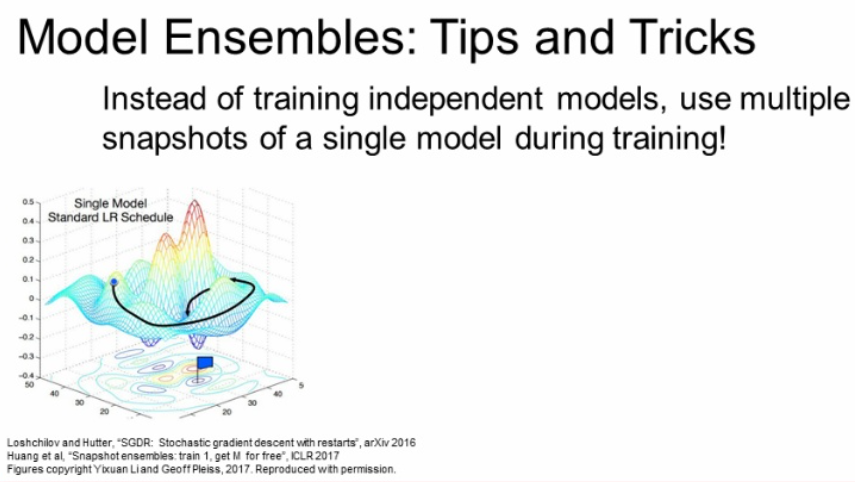
Ensemble Tips and Tricks Learning rate Schedules
앞에서는 여러 개의 모델을 학습시키는 방법을 사용했다면, learning rate를 계속 변화시켜 다양한 지역에 수렴할 수 있도록 하는 방법이 있습니다.
이 방법은 아래 그림과 같이 learning rate를 계속 줄이다가 일정 Epochs(Batchs) 마다 다시 올리는 것을 반복하여 손실함수가 다양한 지역에 수렴할 수 있다고 하는 것입니다.
이 방법은 한번만 train하여도 좋은 성능을 얻을 수 있습니다.

Ensemble Tips and Tricks Polyak averaging
이 방법은 학습하는 동안 파라미터의 exponentially decaying average를 계속 계산하는 것입니다.
이 방법은 학습중에 smooth ensemble 효과를 얻을 수 있다고 하며, checkpoints에서의 파라미터를 그대로 사용하지 않고 smoothly decaying average를 사용합니다.
이를 polyak averaging이라고 하고 때때로는 조금 성능향상이 있을 수도 있다고 하는데 자주 사용하지 않는다고 합니다.
정확하게 무슨소리인지 사실 저도 잘 모르겠네요.
# Polyak averaging
while True:
data_batch = dataset.sample_data_batch()
loss = network.forward(data_batch)
dx = network.backward()
x += - learning_rate * dx
x_test = 0.995*x_test + 0.005*x # use for test set
Regularization
자 overfitting을 방지하기 위한 방법중 앙상블에 이어서 이번에는 Regularization(제약)에 대해서 배워 봅시다.

L1 L2 Regularization
아래와 같이 앞에서 기본적인 Regularization 방법중 하나인 L1과 L2에 대해서 배웠습니다.
하지만 실제로 이 방법은 Neural Networks 에서는 잘 사용하지 않는다고 합니다.
대신 Batch Normalization(BN)과 Dropout 을 사용한다고 합니다. BN은 들어보신적이 있지만 Dropout은 처음들어보죠? 한번 알아봅시다.

Dropout
Dropout 이란, 말 그래로 꺼버리는 방법입니다. Forward 과정에서 일부 뉴런을 0으로 만들어 버리는 것입니다. 그리고 forward pass 할 때마 0이 되는 뉴런을 바뀌게 됩니다.
이거는 한 레이어씩 진행되는데, 한 레이어의 출력을 구하고 임의로 일부를 0으로 만들고 그리고 넘어가고 이런식으로 진행하며 아래 오른쪽 그림이 Dropout을 적용한 상태입니다.

Dropout은 아래와 같이 정말 간단합니다.
첫번째 Hidden layer에서 나온 출력값 H1과 p의 확률로 1 또는 0 의 값을 가지는 U1과의 곱으로 간단하게 구현할 수 있습니다. 다음 Hidden Layer 또한 같은 방법으로 H2의 Dropout을 적용시킵니다.
아래에서 p의 값은 0.5로 0.5보다 작은 값에 대해서는 1로, 높은 값에 대해서는 0으로 사용하는 방법입니다.
p의 값이 크면 적은 수를 Dropout 시키며, p의 값이 작으면 많은 노드를 Dropout 한다고 생각하실 수 있습니다.
p = 0.5 # probability of keeping a unit active. higher = less dropout
def train_step(x):
""" X contains the data """
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # first dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # second dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass: compute gradients... (not shown)
# perform parameter update... (not shown)
자 이렇게 왜 Dropout 하는 것이 Regularization에 왜 좋을 까요?
아래에는 이에 대한 간단한 설명이 있습니다.
아래와 같이 입력이 들어간다고 생각합시다.
일반적으로 Dropout을 시키지 않게 되면 어떤 일부의 feature에 대해서 의존하는 현상이 발 생할 수 있는데, Dropout으로 이를 막아주는 역할을 한다고 합니다. 결과적으로 이러한 것이 overfitting을 막아준다는 해석이 있습니다.
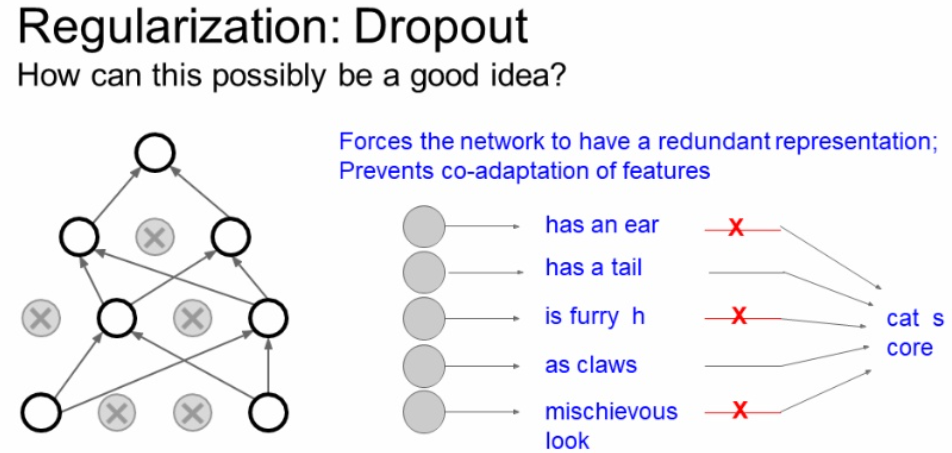
또 다른 해석은 단일 모델로 앙상블 효과를 가질 수 있다는 것입니다.
forward pass마다 랜덤으로 Dropout을 하기 때문에 forward 마다 다른 모델을 만드는 것과 같은 효과가 나오게 될 수 있습니다.
위에서 배운 앙상블은 뉴런의 수에 따라서 엉청나게 많은 서브 네트워크 수를 가질 수 있기 때문에 모든 서브네트워크를 사용하는 것은 불가능합니다.
이 Dropout은 거대한 앙상블 모델을 동시에 학습 시키는 것이라고도 할 수 있습니다.
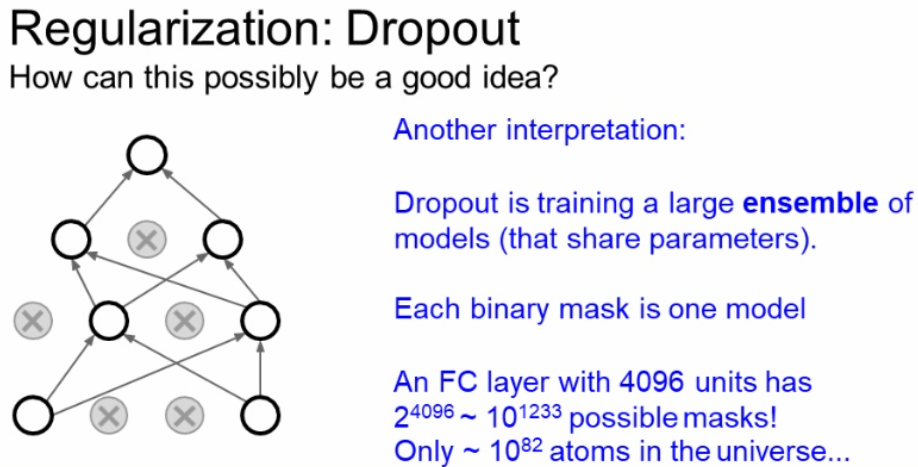
이제 이렇게 학습을 했다고 합시다.
그렇다면 Test time 에서는 이를 어떻게 사용하여야 할까요?
방법은 average out을 사용하는 방법입니다.
하지만 이 방법은 적분을 사용하기 때문에 어려워 보입니다.

우리는 이를 적분을 직접하는 방법이 아닌 확률적으로 접근하는 locally chip한 방법을 사용합니다.
아래 예시를 봅시다.
한 출력 a = w1x + w2y 입니다. 여기서 (p=0.5)의 확률로 x와 y를 Dropout 한다고 가정합니다.
이때 우리는 적분 값이 아닌 출력의 기대치를 구하는 것입니다.
결과적으로 이 기대치는 원래 a의 출력에 p를 곱한 값이 기대치이며 test time에서는 Dropout를 사용하지 않고 p 값을 곱한 것을 사용한다고 합니다.

코드로는 아래와 같이 각 H1의 값에 p 값을 곱해준 값을 입력 값으로 사용하는 것을 볼 수 있습니다.
하지만 이렇게 되면 test time에 각 입력에 p를 곱해줘야 합니다.
forward code를 보존하면서 test time complexity를 보장할 수 있는 방법이 없을까요?
# Dropout: Test time
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations
out = np.dot(W3, H2) + b3
물론 있습니다!
한가지 트릭으로 test에서 p를 곱하는게 아니라, training 할때 p를 미리 나눠서 사용하면 똑같습니다.
이렇게하면 test time 에서 더 좋은 계산 효율을 가지고 갈 수 있습니다.

그리고 Dropout을 사용하면 학습 시간이 늘어납니다. 하지만 모델이 수렴한 후에는 좋은 일반화 모델이 나오게 됩니다.
결국 dropout은 일반적인(common) 전략을 구체화한 예시입니다.
Train time 에서는 무작위성(randomness)를 추가해 train data의 너무 fit하지 않게 하는 것입니다.
그리고 test time에서는 randomness를 평균화 시켜서 사용하는 것입니다.
우리는 Regularization의 한 예인 Dropout에 대해서 배웠습니다.
여기서는 다루지 않았지만 배웠던 Regularization 중 Batch Normalization 도 있습니다.
Batch Normalization은 Training에서는 mini-batch에 대해서 얼마나 정규화 시킬지에 대한 stochasticity가 존재하였습니다.
또한 Testing time에서는 mini-batch가 아닌 global 단위로 수행하여 stochasticity를 평균화 시킵니다.
이러한 점에서 Batch Normalization은 Regularization 효과를 얻을 수 있습니다.
둘을 한번에 같이 쓰지는 않지만, 각각의 특징은 Dropout은 특정 노드들로 weights가 편중되는 현상을 막아주기 위해 사용 한다고 하며, BN은 Node의 편향성을 줄여 optimizer 를 도와주기 위해 사용한다고 합니다.
결국 Regularization이란 Overfitting을 막기 위해서 noise를 주는 방식이라고 생각하시면 됩니다.

Data Augmentation
위에서는 Network에 직접적인 영향을 주면서 Regularization을 시켰습니다.
여기서 Data Augmentation은 데이터에 대한 Regularization입니다.
자 아래 그림을 봅시다.
고양이를 이미지로 넣어서 작업을 한다고 합시다.
이때에 고양이는 좌우 반전을 해도 똑같은 고양이입니다.
이렇게 데이터를 조금씩 변경하여 다양한 데이터를 넣어주는 방식을 Data Augmentation이라고 합니다.
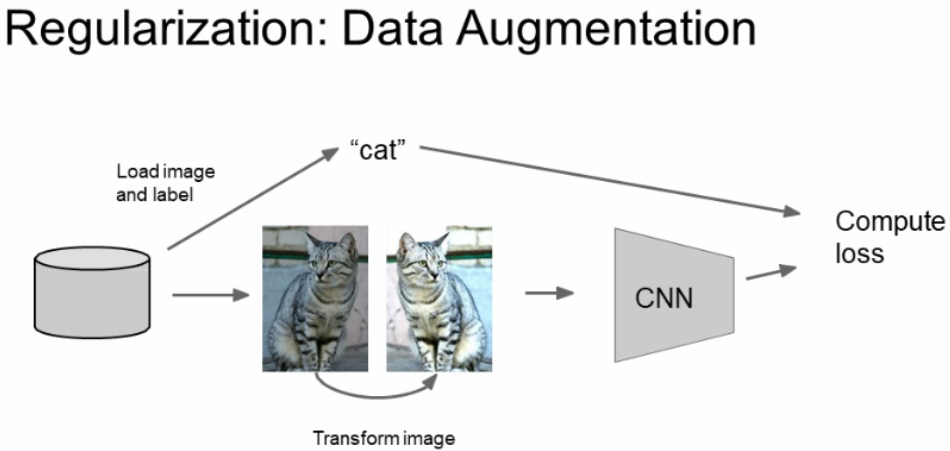
좌우 반전 이외에도 Random crops와 Scales 방법도 있습니다.
이미지를 임의의 다양한 사이즈로 crop(잘라서) 사용할 수 있습니다.
이를 crop한 뒤에 원본 크기로 키워(Scale)줍니다..
아래 예시는 ImageNet관련 논문을 보면, 데이터를 학습할때에 4개의 코너 + 중앙에 대한 5개 공간에 대해 자르고 각각 좌우반전하여, 1개의 사진에 대해 총 10개 데이터를 생성하고 이에 대해서 학습을 진행합니다.
이후에 test time에서도 이와 같이 10개의 사진에 대해서 평가를 진행했다고 합니다.
또한 이미지 크기를 5가지 크기로도 바꿔서 학습을 진행해보기도 했다고 합니다.

또한 Data Augmentation에서 color jittering 기법도 사용합니다. 임의로 색을 반전 시키는 것이라고 합니다.
그리고 PCA(Principal Component Analysis) 주성분분석을 이용해서 PCA방향을 고려해서 color offset을 조절하는 방법도 있다고 합니다.
자주 사용하는 방식은 아니라고 합니다.

뭐 이에 이어서
- 사진 좌표 이동
- 회전
- 늘려보기
- 기울려보기 (직사각형 사진을 평행 사변형 꼴로)
- 렌즈 왜곡 주기 등...
도 있다고 하네요 :( 허허 웃음만 나오네요

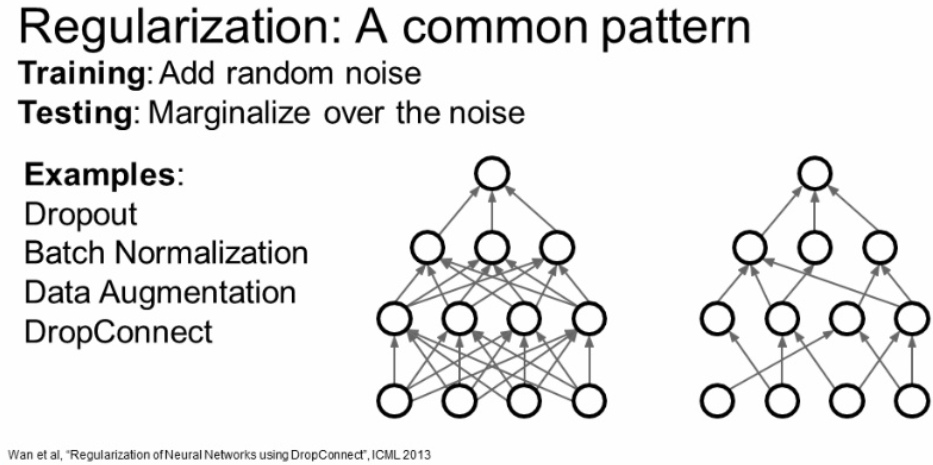
DropConnect
또 다른 Regularization으로 Dropout에서는 입력을 Drop 했다면 DropConnect은 weight 값에 대해서 Drop를 줍니다.
다른 말로 weight 값에 대해서 임의로 0으로 설정해 주는 것입니다.
임의로 weight matrix를 임의적으로 만들어주고 이를 곱해주는 것입니다.
Fractional Max Pooling
또 다른 Regularization 방법으로 Fractional Max Pooling (FMP) 이라는 방법입니다.
자주 사용하지 않지만 좋은 아이디어라고 합니다.
보통 2x2 Max Polling 연산을 고정된 2x2 지역에서 수행합니다.
이 Fractional Max Pooling은 고정된 영역이 아닌 임의로 선정한 영역에 대해서 Max Pooling을 수행합니다.
아래의 오른쪽 그림처럼 임의로 선정되는 것입니다.
그리고 Test time에 Stochasticity를 average out 시키려면 Pooling region을 고정시키거나 여러 개의 pooling region을 만들고 averaging 을 적용한다고 합니다.

수업에서 다룬 내용만으로는 뭔가 아쉬워서 다른 자료를 참고했습니다.
간단하게 정리하면 다음과 같습니다.
- Maxpooling과 다르게 이미지의 크기를 alpha 인수로 줄이는데, 이 값은 1 또는 2 입니다.
- 이 영역을 선택하는데 있어서 무작위로 선택합니다.
- 풀링 영역은 분리되거나 중복될 수 있습니다.
- Random FMP을 Dropout과 Data Augmentation과 같이 사용하면
Overfit될 수도 있습니다.


Stochastic depth
자 여기서 소개할 마지막 Regularization 방법입니다.
이 Stochastic depth는 입력값, weight 값도 아닌 layer를 Drop 시키는 것입니다.
이 효과는 dropout과 비슷하고, test time에서는 전체 네트워크를 사용합니다.
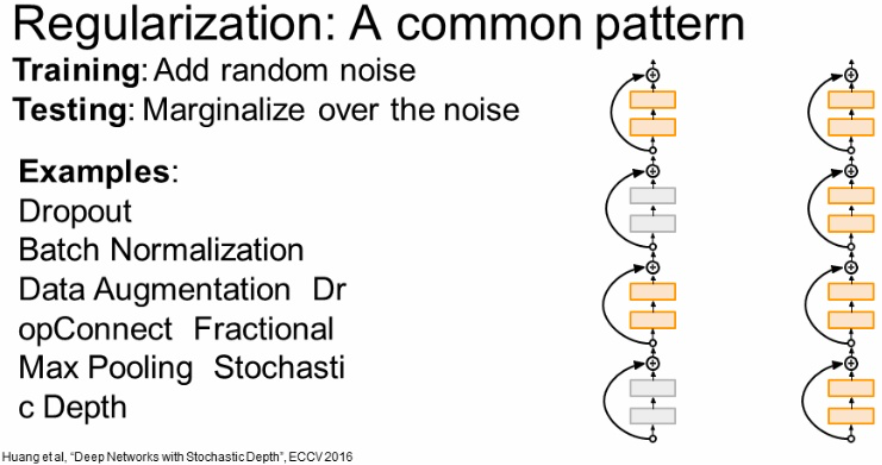
Regularization 결론
일반적으로 Regularization은 보통 1개를 사용한다고 합니다.
보통 Batch Normalization을 많이 사용하는데요.
근데 이걸 사용했는데도 Overfitting이 발생한다? 그러면 Dropout을 추가해주거나 다른 방법을 적용한다고 합니다.
Transfer Learning
자 마지막 내용인 Transfer Learning입니다.
한국말로는 전이 학습이라고 부릅니다.
이 Transfer Learning은 CNN에서 많은 데이터가 필요하다는 문제에 나름에 차안책을 제시해줍니다.
이 Transfer Learning은 이미 pre-train 된 base model과 새로운 데이터를 추가로 사용한다는 방법입니다.
자 Transfer Learning 진행 과정은 아래와 같습니다.
- Transfer 절차
- ImageNet과 같은 아주 큰 데이터 셋으로 학습을 시킵니다. (또는 이미 학습된 weight를 가져옵니다.)
- 이후 우리가 가진 작은 데이터셋에 적용시킵니다. 보통 가장 마지막 FC Layer을 초기화 하고 이부분만 우리의 데이터셋으로 다시 학습시키는 방법입니다.
- 또는 우리의 데이터 셋이 많다면 위에 있는 3개의 FC에 대해서 또는 좀더 많은 Layer를 초기화 하고 학습을 진행한다고 합니다.
- 일반적으로 이미 학습이 되어있는 상태로 learning rate 값은 원래보다 낮은 값(일반적으로 기존보다 1/10) 값을 사용한다고 합니다.
![]()
우리는 Transfer Learning을 할 때에 4가지 시나리오를 생각해볼 수 있습니다.
- 데이터가 적은데, 기존 데이터셋과 다른 경우
- 이러면 문제가 있습니다. 다른 방법을 찾아야 합니다.
- 데이터가 적은데, 기존 데이터셋과 비슷한 경우
- 이 경우 맨 위에 Linear Classification을 추가하면 된다고 합니다.
- 데이터가 많은데, 기존 데이터셋과 다른 경우
- 기존보다 훨씬 많은 layer을 fine-tunning 해야합니다.
- 데이터가 많은데, 기존 데이터셋과 비슷한 경우
- 적은양의 layer를 fine-tunning 하면 된다고 합니다.
![]()
아래는 Transfer Learning의 적용 예시입니다.
왼쪽은 일반적인 이미지 분류기이며, 오른쪽은 Image Captioning 입니다.
이러한 경우 이미 학습된 CNN 이미지 분류기를 pretrain으로 사용하고, RNN 부분과 같은 경우 이미 학습된 Word vector을 사용하여 Transfer Learning을 적용한다고 합니다.
컴퓨터 비전과 같은 경우는 pre-train을 base로 시작하는 경우가 많다고 합니다.
![]()
