소개
- 이 글은 단지 CS231n를 공부하고 정리하기 위한 글입니다.
- Machine Learning과 Deep Learning에 대한 지식이 없는 초보입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
참조
-
https://strutive07.github.io/2019/04/01/cs231n-Lecture-9-1-CNN-Architectures.html
-
https://zzsza.github.io/data/2018/05/25/cs231n-cnn-architectures/
-
http://melonicedlatte.com/machinelearning/2019/11/01/212800.html
개요
< CNN Architectures >
- Introduction
- AlexNet
- VGG
- GoogleNet
- Inception module
- ResNet
- Comparing complexity
- SENet
- Improving ResNets
- Wide Residual Networks
- MobileNets
Introduction
이번 강의는 여태 나왔었던 훌륭한 CNN 모델들을 소개해줍니다.
AlexNet(알렉스넷), googleNet(구글넷), VGG Net, ResNet(레즈넷) 등을 소개하는 강의입니다.
이 모델들은 imagenet과 localization 대회에서 우수한 성적을 거둔 모델입니다.

AlexNet
AlexNet은 최초의 Large scale CNN 입니다.
AlexNet의 등장으로 CNN이 주목받기 시작했다고 해도 과언이 아닙니다.
이 논문은 2012년도에 발표되었는데, 그 당시에는 컴퓨터의 성능이 좋지 않아서 네트워크를 분산시켜서 GPU에 넣었다고 합니다.
그래서 그림에서 Feature map이 2개의 영역으로 나누어져 있는 것을 볼 수 있습니다.
AlexNet의 특징을 살펴보면 다음과 같습니다.
- ReLU를 처음으로 사용
- Local Response Normalisation(LRN) Norm Layers를 사용
- Data augmentation을 많이 사용
- dropout : 0.5
- batch size : 128
- SGD Momentum : 0.9
- Learning rate : 1e-2
- L2 weight decay : 5e-4
- 7 CNN ensemble : 18.2% -> 15.4%

참고) Local Response Normalisation(LRN) 이란?
Batch Normalization이 등장하기 전에, 이를 대신해 측면 억제(lateral inhibition)을 하기 위해서 사용한다고 합니다.
측면억제란, 아래 그림과 같이 검은색과 흰색선이 있다고 합시다. 이때, 흰색선의 교차점을 집중해서 보면 흰색이지만 집중해서 보지 않으면 회색의 점이 보이는데 이러한 현상이 측면 억제에 의해 발생합니다.

이를 AlexNet에서 사용한 이유는 ReLU의 사용으로 양수의 값을 대로 사용하여 Conv와 Pooling시 매우 높은 픽셀 값이 나올 수 있습니다. 이를 방지하기 위해 다른 ActivationMap의 같은 위치에 있는 픽셀끼리 정규화 하는 것입니다.

VGG
ILSVRC 우승 모델 중 다음으로 알아볼 모델은 VGG 입니다.
VGG는 AlexNet과 비교했을때, 확실히 Layer의 수가 깊어진 것을 볼 수 있습니다.
하지만 VGG는 AlexNet의 초기 Conv의 11x11 filter와 같이 큰 filter가 아닌 3x3 필터로 바꿔 쌓아 올려 파라미터의 수를 줄인 것을 볼 수 있습니다.
VGG의 모델은 VGG16, VGG19가 대표적인데 Layer의 갯수에 따라 다른 이름이 붙어졌습니다.

VGG 모델의 파라미터 수는 다음과 같습니다.

VGG의 특징을 살펴보면,
- AlexNet과 비슷한 절차로 Training을 걸침
- Local Response Normalisation(LRN)이 없음
- Ensemble을 사용해서 최고의 결과를 뽑아냄
- 맨 마지막에서 두번째 FC (fc7)은 다른 task들을 가지고 잘 일반화를 함
GoogleNet
다음으로는 GoogleNet이 있습니다.
매우 복잡한 구조를 가지고 있으며, 가장 큰 특징으로 Inception module을 사용했습니다.
GoogleNet의 특징은 다음과 같습니다
- 22 Layer들로 구성
- 파라미터의 수를 줄이기 위해 Fully Connected Layer를 없앰
- 총 5백만 개의 파라미터 수 (AlexNet과 비교하면 현저히 줄어듬)
- 높은 계산량을 효율적으로 수행

Inception module
Inception module의 대해 좀 더 자세히 알아보면
같은 입력을 받는 여러 개의 필터들이 병렬적으로 존재하고, 결과를 합치는 것을 볼 수 있습니다.
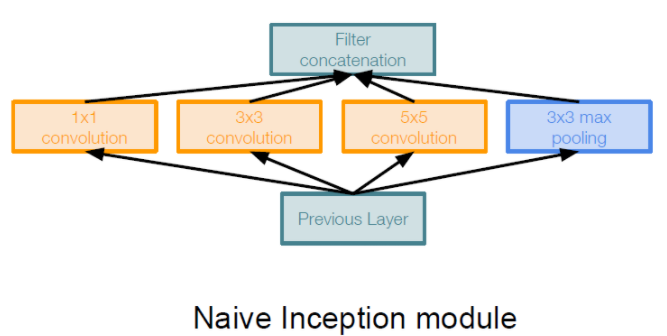
하지만 이러한 구조로 Inception module을 만들면 계산량 측면에서 문제가 발생합니다.

이러한 문제를 조금이라도 해결하기 위해서 1x1 convolution layer를 사용합니다.
이렇게 되면 input의 depth가 줄어드는 효과가 납니다.
이것을 Bottleneck layer라고 합니다.
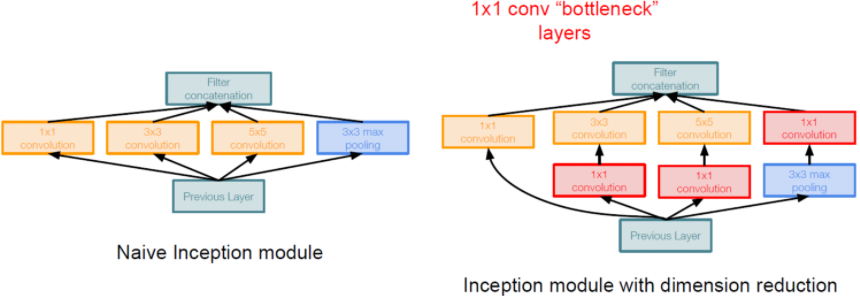
1x1 convolution layer로 depth를 줄이면 정보의 손실이 있지만 동작을 더 잘합니다.
차원을 줄인 후 parameter의 수를 다시 확인하면,
854M 에서 358M로 2배 이상 줄어든 것을 확인할 수 있습니다.

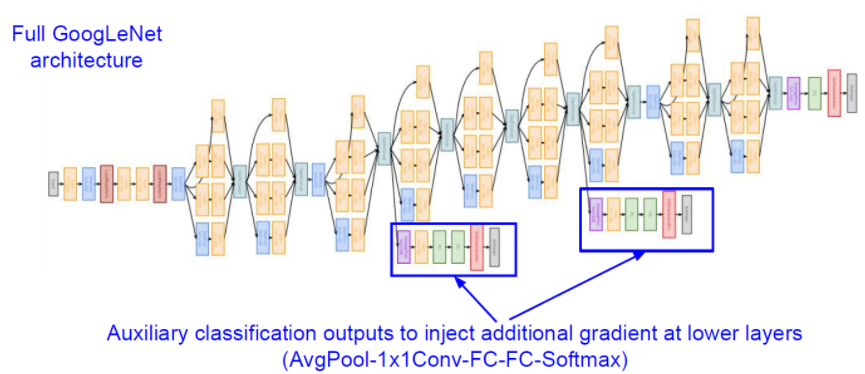
또 다시한번 GoogleNet의 구조를 살펴보면
아래와 같이 중간중간에 보조 분류기가 있는 것을 확인할 수 있습니다.
이것은 네트워크의 깊이가 깊기 때문에 중간 Layer의 학습을 돕기 위해서 설계한 것이라고 합니다.
ResNet
이번에는 ResNet에 대해서 배워봅시다.
Residual connection 이라는 새로운 구조로 굉장한 성능을 보였습니다.
기본적인 Residual Block의 모습과 모델의 구조는 아래와 같습니다.

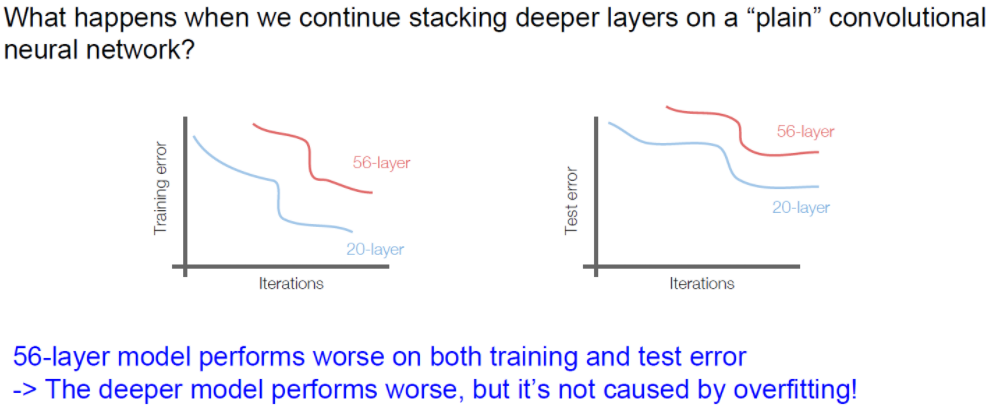
일반적으로 CNN이 깊어서 Parameter 수가 늘어나면 Overfitting의 위험이 있다고 생각할 수 있습니다.
하지만 결과는 다른 것을 볼 수 있습니다.
56-layer와 20-layer를 비교한 결과이다.
이 결과는 오히려 더 깊은 layer를 가진 구조가 training error가 더 높았다.
overfitting이 되었다면 training error가 낮아야 하지만 우리의 생각과 다른 것을 볼 수 있습니다.
결국, 네트워크 구조가 깊으면 깊을 수록 어느 순간 그 모델은 얕은 모델보다 학습이 안된다는 것인데,
이러한 현상을 Degradation이라고 합니다.
이러한 Degradation 문제를 해결하기 위해서 등장한 방법이 Skip connection 이라는 구조입니다.
일반적으로 Layer를 쌓아 올리는 방식 대신, Skip connection이라는 새로운 구조를 이용하여 학습을 진행합니다.
이러한 방법은 연산 증가도 거의 없고, 만약 Gradient Vaninshing 현상이 일어나더라도 원본 신호에 대한 정보를 가지고 있어 학습을 하는데 원할하게 시킬수 있다는 것이 ResNet을 만든 연구진의 설명이라고 합니다.
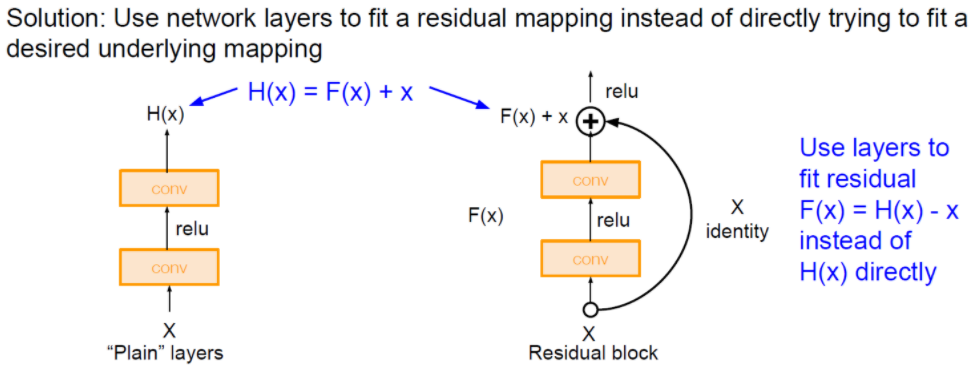
이러한 Residual block을 이용한 결과 깊이가 깊어질수록 더 정확하게 training을 시킬 수 있었습니다.

ResNet의 특징은 다음과 같다.
- VGGNet과 비슷하게 convolution layer를 3x3로 설계
- 복잡도를 낮추기 위해 dropout, hidden fc를 사용하지 않음 대신 Batch Normalization 사용
- 출력 feature-map의 크기가 같은 경우, 해당 모든 layer는 모두 동일한 수의 filter를 갖음
- Feature-map의 크기를 줄일 때는 pooling을 사용하는 대신에 convolution을 수행할 때, stride의 크기를 2로 하는 방식을 사용
- Xavier initialization 사용
- SGD + Momentum (0.9)
- Learning rate : 0.1
- Mini-batch size 256
- L2 Weight decay of 1e-5
아래는 test 시간과 에너지 소비량에 대한 그래프인데, FC가 크게 있을 수록 안좋은 결과를 가집니다.

Comparing complexity
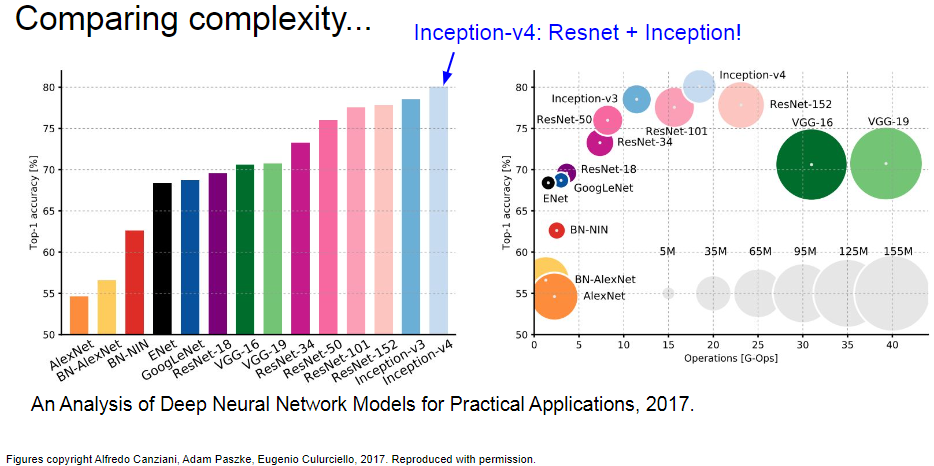
전반적인 CNN의 분석은 아래와 같습니다.
2017년 기준
- 가장 높은 성능 : Inception-v4 - Resnet + Inception
- 가장 많은 파라미터와 계산량 : VGG
- 가장 효율적 : GoogLeNet
- 적은 계산량, 많은 메모리, 낮은 성능 : AlexNet
SENet
SENet은 Resnet 이후에 에러를 낮추기 위한 새로운 방법 중 하나입니다.
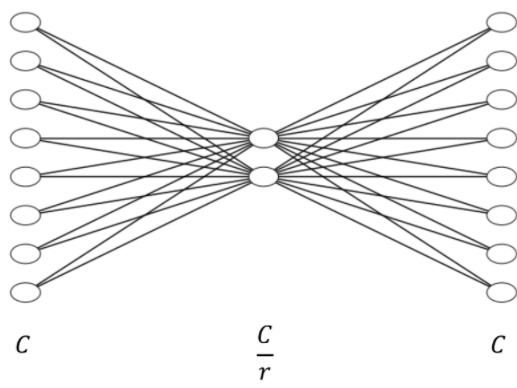
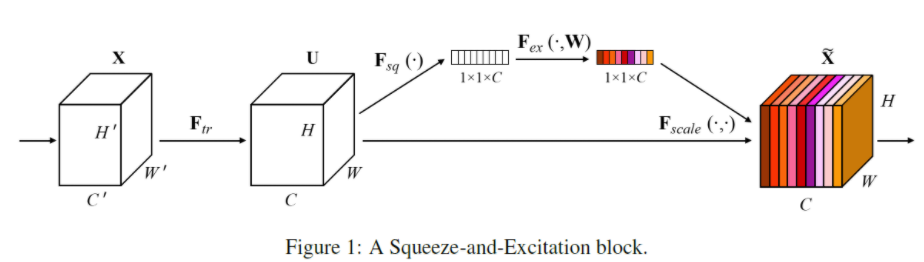
이 방법은 Channel-wise feature response를 적절하게 조절해주는 Squeeze-and-Excitation(SE)입니다.
Squeeze-and-Excitation Block의 구조는 아래와 같습니다.
여기서는 사용하는 중요한 개념을 소개하고자 합니다.
- Squeeze : Global Information Embedding
- Local Receptive field가 작은 네트워크 하위 부분에서는 중요 정보 추출 개념이 중요합니다.
- 여기서 GAP(Global Average Pooling)기법은 global spatial infromation을 channel descriptor로 압축할수 있습니다.
- Excitation : Adaptive Recalibration
- 이제 중요한 정보들을 압축했다면, 재조정(Recalibration)을 해주어야 합니다.
- 여기서는 채널 간 의존성(channel-wise dependencies)을 계산합니다.
- 이는 Fully connect와 Relu, sigmoid 함수를 이용하여 간단히 구현가능합니다.

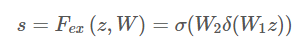
아래 그림은 이를 실제 적용한 예시입니다.
왼쪽은 Inception module에 추가한 SE-Inception의 예시이며,
오른쪽 그림은 skip-connection에 추가한 SE-ResNet의 예시입니다.
이를 개발한 논문 저자는 이 SE Block 방법을 VGGNet, GoogLeNet, ResNet에 적용했다고 합니다.

Improving ResNets
여러 ResNets의 발전들이 있지만, 공부할 시간이 부족하다.
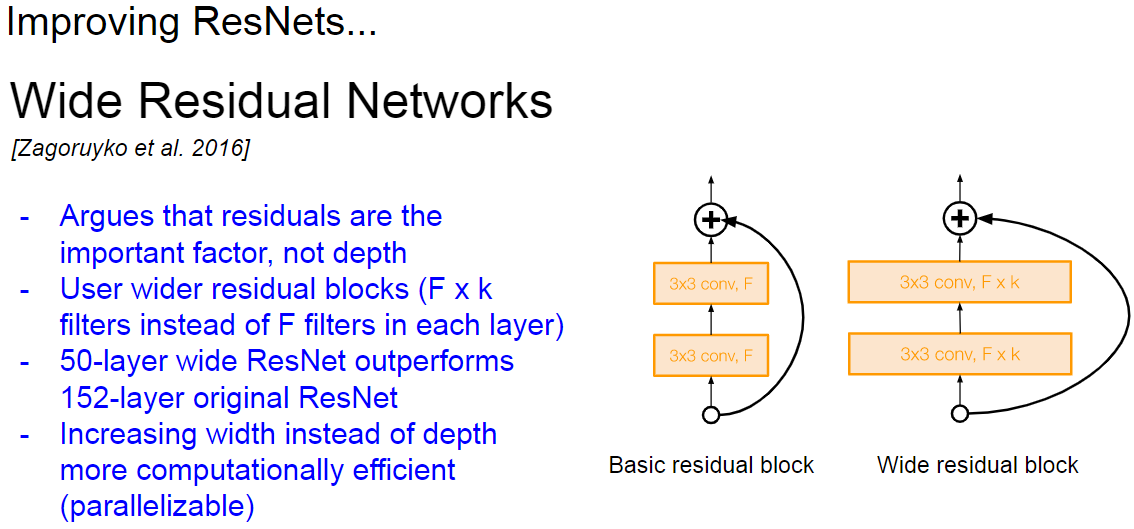
Wide Residual Networks
아래는 Wide Residual Networks이다.
152-layer 크기에 ResNet보다 Residual Block의 크기를 늘린 50-layer 크기에 ResNet이 더 좋은 성능을 가졌다고 한다.
계산량 면에서도 더 효율적이라고 한다.
MobileNets
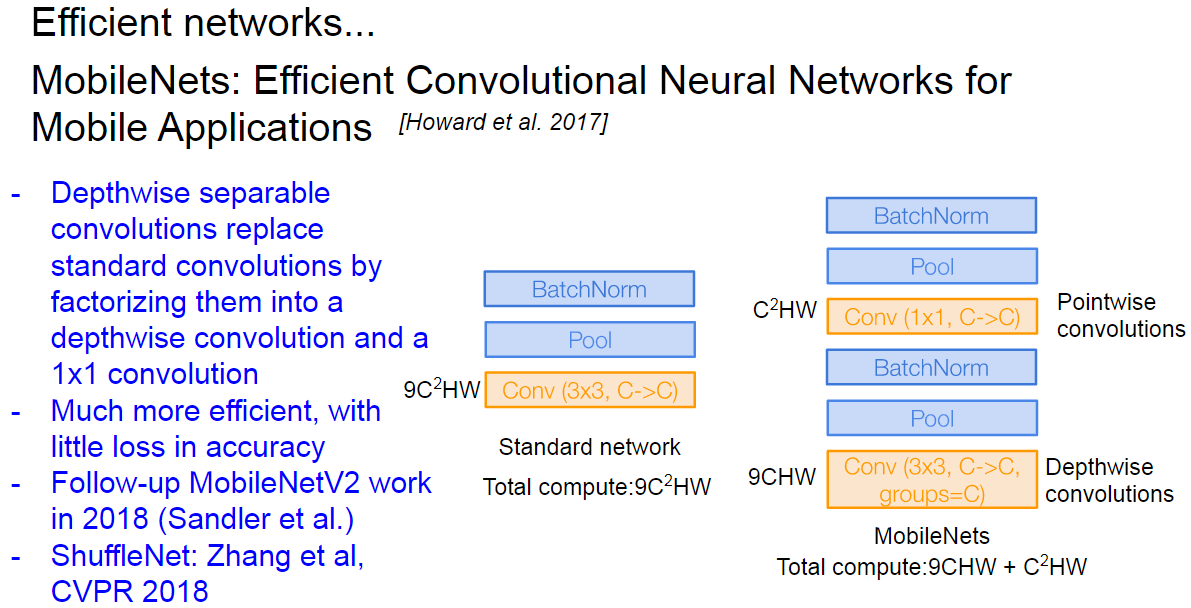
기존의 Convolutional layer의 계산량을 줄이기 위한 방법이다.
Convolutional layer를 depthwise convolution과 pointwise convolutions로 비슷하게 대체하고 계산량을 줄였다.
이에 대한 소개를 이 블로그에서 정말 잘 설명하여 가져왔다.
기존의 CNN은 아래 그림과 같이 하나의 결과를 계산하기 위해서 모든 channel의 값을 Convolution을 진행하였다.
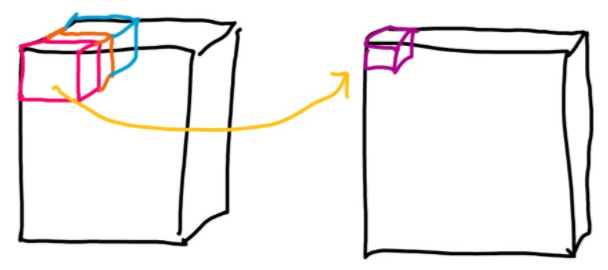
이와 다르게 Depthwise convolution은 입력과 출력의 채널수가 같으며, 1개의 channel의 정보만 보고 출력 값을 계산한다. 이런 점에서 계산량도 입력 채널수 배수 만큼 줄어들고, weight 수도 줄어든다.

이후 Pointwise 기법은 Depthwise의 출력 결과를 1x1 Convolution 하여 출력 채널을 조절합니다.
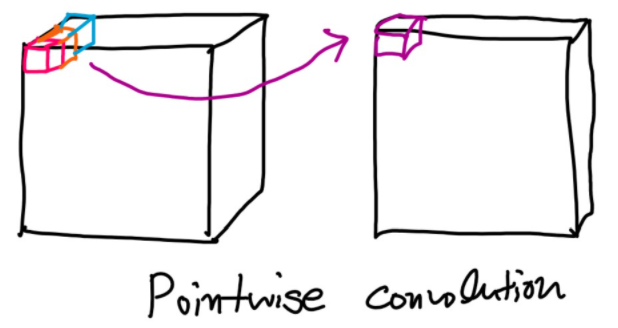
이러한 방법을 Depthwise convolution이라고 하고 기존 CNN보다 K^2 배 빠른 계산량을 가진다.
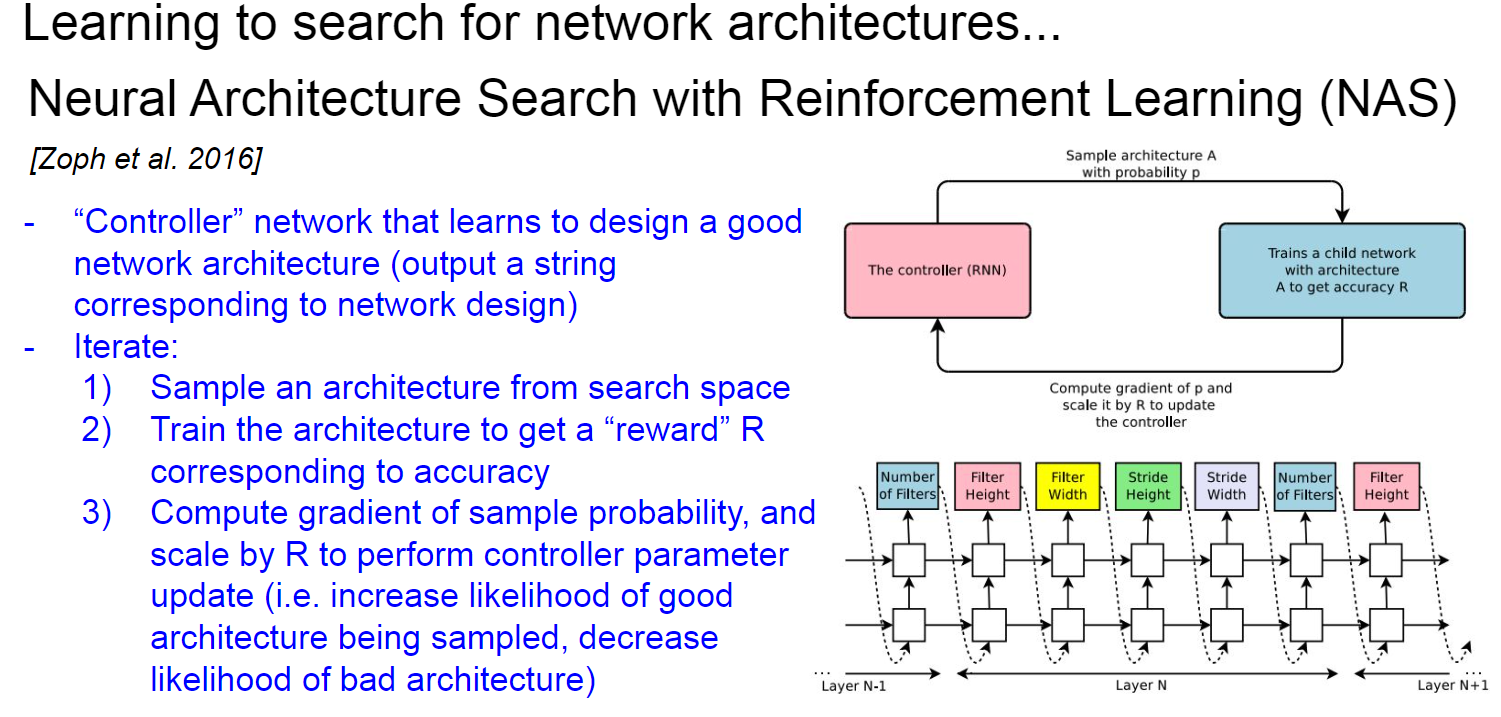
이후로 Reinforce Learning 개념을 도입한 NAS(Network Architecture Search), smart 휴리스틱을 도입한 EfficientNet이 있는데...
나는 잘 모르겠다 ㅎㅎ 궁금하신분들은 공부해보시길 바란다!