
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
2020 Interspeech 에 제출되었던 논문입니다.
통과는 되지 않은듯 하지만? 기존 SA-EEND의 fixed number speaker 문제를 해결하고자 노력한 논문으로 리뷰를 하고 싶었습니다!
제가 확인했을때는 SC-EEND model은 제공되지 않고 있지만, SA-EEND와 EEND-EDA를 참고하면 구현이 어려울 것으로 생각되지는 않습니다.
Citation
- Y. Fujita, S. Watanabe, S. Horiguchi, Y. Xue, J. Shi, K. Nagamatsu “Neural Speaker Diarization with Speaker-Wise Chain Rule,” arXiv preprint arXiv:2006.01796, 2020.
Introduction
기존 연구
- End-to-End Neural speaker Diarization (EEND)
- 장점
- Clustering-free 방법으로 direct diarization optimize 가능
- End-to-end 방식으로 network가 단순하고, external 모듈 필요 없음 (SAD, PLDA, VB 등)
- Permutation Invariant Training (PIT) 으로 End-to-end 학습이 가능한 Objective Function를 제안함
- 두 화자 기준 telephone conversation datasets(CALLHOME, CSJ) 기준 SOTA
- 한계점
- SA-EEND는 한 wav 안에 최대 2명의 화자만을 구분해 낼 수 있다. 그 이상인 경우를 다루지 못함.
논문의 제안
- 두가지 방법 제안
- Speaker-wise conditional inference 방법으로 3명 이상 화자를 EEND가 다룰수 있도록 함
- Teacher-Forcing(TF) Training 방법 제안
결과
- Contribution
- 3명 이상의 화자에 대해서도 다룰 수 있게 됨
- 기존 SA-EEND 성능을 뛰어넘음
- Limitation
- Speaker Conditional 방법으로 이전 출력의 오류가 전파되기 쉬움
- Network 자체가 이전 화자를 Conditional 하게 모델링이 잘 될지 모호하다고 생각됨
- 학습 시에 보지 못한 화자 수에 대해서는 찾기 못하는 한계점 보임 (5명 이상인 경우 전혀 못 찾아냄)
Related work
Similar work
- SC-EEND는 기존 Speech separation task에서 제안된
Listening to each speaker one by one with recurrent selective hearing networks라는 ICASSP 2018 논문 모델에서 제안한residual speaker mask에 영감을 받았다.- 이 residual speaker mask 는 speaker에 있을 것 같은 frequency bin position의 masking 값으로, 각 화자에 대해서 mask로 Speech separation 을 진행한다.
- 하지만 이는 speaker diarization task가 아니며 아래와 같은 제한을 한다.
- In paper,
Speaker mask are additive and sum to one for each time-frequency bin- 위와 같은 가정은 speaker diarization에는 맞지 않으며, 이 논문에서는 이러한 가정을 보완하기 위한 방법을 제안한다.
Another approach work
- variable number of speaker을 위해서 기존에는
AHC와UIS-RNN이 연구되었다.- AHC (Agglomerative Hierarchical Clustering)
- clustering 기반 기법으로 특정 score threshold 값이 넘지 않을 때 까지 cluster 를 merging 하여 화자 수를 알아낸다.
- UIS-RNN
- Bayesian nonparameteric model 을 이용하여 새로운 화자를 online으로 찾아낸다.
- 위 방법은 overlapping speech을 다루지 못하는 단점을 가지고 있다.
Method
Speaker-wise Chain rule (SC-EEND)
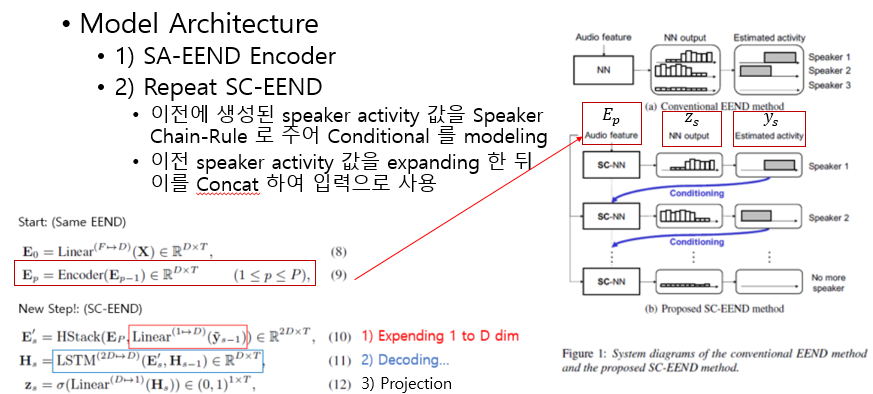
- Model
- 기존 SA-EEND와 동일한 입력(Stacked Sub-Sampling)과 Encoder Block를 사용한다.
- 단, 각 화자에 대한 출력은 SC-NN를 통해
순차적으로 예측 된다 - SC-NN의 입력은 SA-EEND에서 생성된 Audio Feature와 이전 화자의 Speaker Activity 정보가 같이 사용되며, 이러한 점에서 Speaker-wise Chain rule이 적용 된다고 설명한다.

Encoder-Decoder architecture
- Model
- Step 1. Encoder : Make Embedding using SA-EEND
- 기존에 사용하던 SA-EEND로 Embedding E_{P} 를 생성해 냅니다. (Eq.8-9)
- Step 2. Decoder : Find speaker using SC-EEND
- 위에서 추출한
Encoder embedding과 이전에 구한speaker 발화 시간 위치 정보를 concat합니다. (Eq.10)- 이때, 1-dim 인 이전 speaker activation 정보 y_{s-1}를 Linear로
Feature Expending해준다.
- 이때, 1-dim 인 이전 speaker activation 정보 y_{s-1}를 Linear로
- concated embedding를 LSTM의 입력으로 주어 Hidden state를 계산해 냅니다.
- Hidden state 값으로 부터 Linear+Sigmoid를 이용해 speaker activition을 계산해 냅니다.
- 위에서 구한 z는 일정 threshold(#paper: 0.5) 이상인 경우 speaker의 speech 영역인 y_{s} 으로 정합니다.
- 발화가 존재하지 않을때 까지 Step 2를 반복합니다.
- 반복 횟수가 N인 경우 N-1 명의 화자를 예측하며, 결국 Variable number of speaker task 가 가능합니다.
- 위에서 추출한
- Step 1. Encoder : Make Embedding using SA-EEND
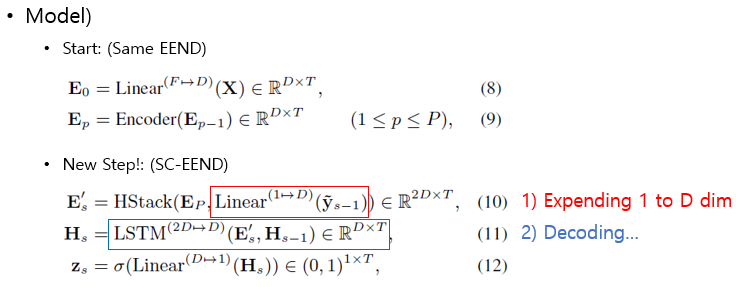
Teacher-forcing during training
- Teacher-forcing의 필요성
- chain rule의 특성
- 이전 예측에 오류가 있는 경우, 오류가 다음 예측 성능에 손상을 줄 수 있다.
- 이를 위한 대처 방안이 필요
- Model의 PIT loss 관점
- 위 문제를 해결하기 위해서 이전에 찾은 화자 speech activation 정보를 GT로 부터 가져오고 싶다.
- But, 우리는 학습 시에 어떤 화자에 대한 출력인지 알 수 없다.
- 논문에서는 이러한 문제를 해결하기 위한 2가지 방법을 제안한다.
- speaker-wise greedy loss
- Two-stage permutation-invariant training (PIT) loss
- chain rule의 특성

Speaker-wise greedy loss
- Greedy algorithm 답게 굉장히 직관적인 방법이다.
- 현재
예측한 결과와 정답 Label간 BCE loss가 가장 작은 화자를 정답으로 취하는 방법이다.- 하지만, 이는
이전에 어떤 화자를 선택했는지에 대한 정보를 포함하지 않으며, 이는한 화자가 두 번 이상 예측되는 등, 최적의 상황을 대변하지 못한다.
Two-stage Permutation-Invariant Training Loss
- 이러한 문제를 해결하기 위해, 본 논문에서는
Two-stage PIL loss를 제안한다.- 방법
- Step 1: 우선, Teacher forcing 즉 Ground Truth 정보를 사용하지 않고, 이전 network에서 구한 y 값으로 SCNN를 inference 한다. 즉
일단 SCNN 네트워크를 믿는다!- Step 2: Step 1에서
구해진 speaker와 정답 간 가장 작은 PIT loss를 가지는 permutation 쌍을 구한다.- Step 3: Step 2에서
구한 화자 permutation으로Ground truth 정보를 주어 inference 진행한다.화자 수 또한 wav의 Ground truth를 사용한다.- Step 4: Step 3에서 구한 prediction에 대한 BCE loss를 계산한다.
- 여기서 L_{PIT2}의 2번째 계산 식은 실제 우리가 찾지 못한 Speaker에 대한 loss term이다.
- L_{PIT2} loss 만을 이용하여 SCNN 에는 permutation 에 대한 loss는 반영되지 않았다. 즉,
잘못된 Permutation 을 예측한 것에 대한 Loss 정보를 반영하지 않았음을 의미한다.

Experimental Setup
Dataset
- 기존 SA-EEND와 동일한 방법으로 simulation 데이터를 생성한다.
- 여기서 추가로 1~4명에 speaker에 대한 simulation 데이터를 추가로 생성한다.
- adaptation set 또한 2-speaker 경우 뿐 아니라 다양한 경우를 모두 사용한다.
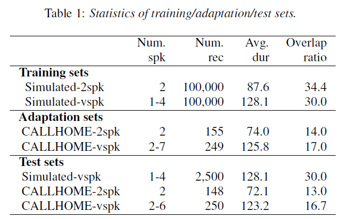
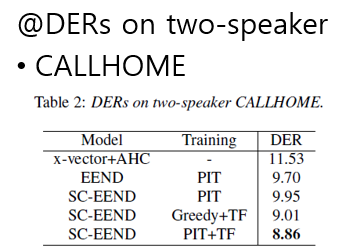
DERs on two-speaker CALLHOME data
- SC-EEND를 PIT로만 사용한 경우 EEND보다 성능이 좋지 않다.
- 하지만 teacher-forcing 방법을 추가하면 더 좋은 성능을 보인다.
- Two-stage PIT loss에 대해서 가장 좋은 성능을 가지는 것을 볼 수 있다.
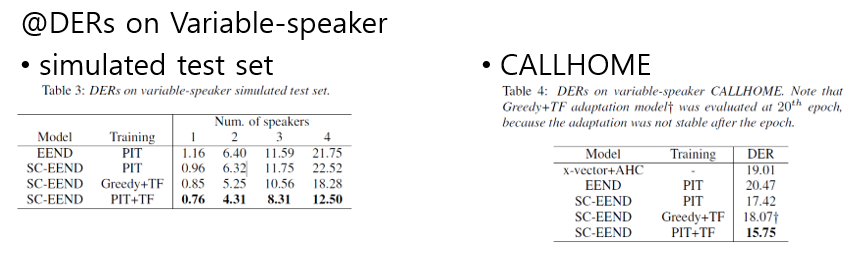
DERs on Variable-Speakers
- variable Number of Speakers에 대한 실험 결과는 아래와 같다.
- Simulation
- 굉장히 의미있는 성능을 보인다. 특히 4명 이상의 speaker에 대해서 굉장한 성능 향상을 보여준다.
- CALLHOME
- 재밋는게 Greedy Teacher-forcing이 그냥 PIT 보다 않좋은 성능을 보인다.
- 역시나 Two-stage PIT loss 가 가장 좋은 성능을 보인다.
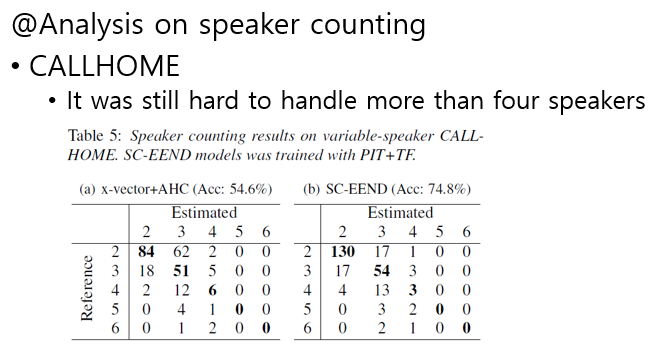
Speaker Counting 분석
- 각 화자수에 따른 화자 수 예측 결과는 아래와 같다.
- 아래의 왼쪽은 x-vector, 오른쪽은 SC-EEND 결과이다.
- 분석
- 기존 x-vector보다 SC-EEND가 2,3명 화자에 대해서 더 좋은 성능을 보인다.
- 하지만, 4명 이상인 경우 x-vector 보다 성능이 떨어지며, 여전히 잘 되지 않는다.
- 위 문제는, 학습 시 50초 Chunk에 대해서 학습이 진행되는데, 50초 내에 4명 이상의 화자가 들어갈 확률이 보다 적어진다. 또한 5명 이상의 화자에 대한 학습이 이루어 지지 않아 5명 이상은 SC-EEND 모델에서 전혀 예측하지 못하는 것을 볼 수 있다.
- 이후 이러한 post processing과 online 방법을 위한 방법은 이후에 다음 논문 리뷰에서 다루겠다.

Audio & Speech AI Researcher 입니다.