
# NoSQL의 특성에 맞게 데이터 모델링하기
-
RDBMS의 데이터 모델링을 수정한 이유
-
토이 프로젝트로 서울 지하철 역 정보를 제공하는 API를 만든 적이 있다. 클라이언트가 역 이름을 입력하고 요청(Request)을 보내면, 해당 역에 관한 정보(호선, 환승역 여부, 첫차 및 막차 시간 등)를 불러오는 API였다.
-
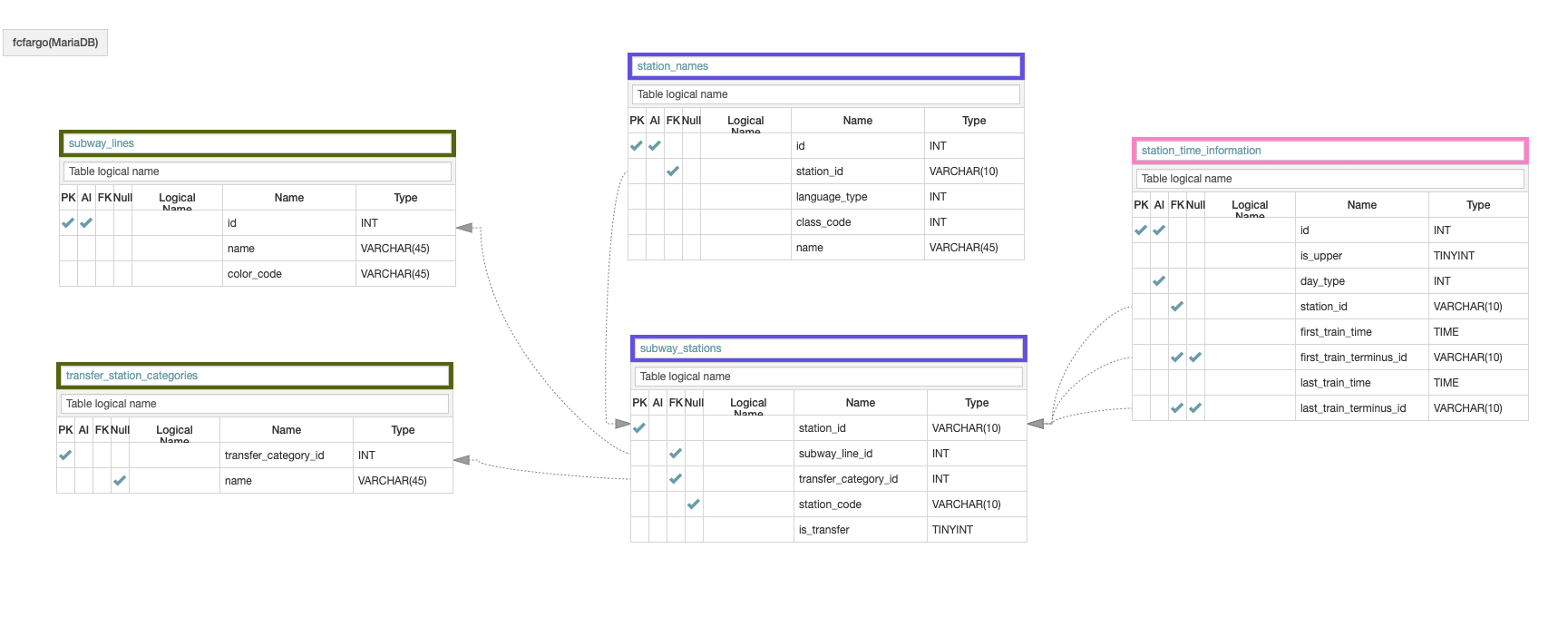
위 모델링은 RDBMS(관계형 데이터베이스) 중 하나인 MySQL에서 사용하려고 설계한 테이블 관계도이다. 평범해 보이지만, 나름 정규화, 데이터 확장성에 대해 고민하며 만들었다 . 원래 MongoDB에도 위 데이터 모델링을 똑같이 적용하려 했는데, 한 가지 고민이 생겼다. 그것은 NoSQL 데이터베이스인 MongoDB의 특성에 맞춰, 기존 모델링에도 변화를 줘야 하는지에 관한 고민이었다.
-
사실, 굳이 모델링을 바꾸지 않아도 API를 구현하는데는 문제가 없었다. MongoDB의 Reference 저장 방식을 쓰면 RDBMS처럼 데이터를 관리하는 게 가능하기 때문이었다. 하지만 그렇게 될 경우, MongoDB만의 특화된 장점을 사용하지 못할 게 뻔했다. 결국 오랜 고민 끝에 나는 모델링을 수정하기로 했다.
-
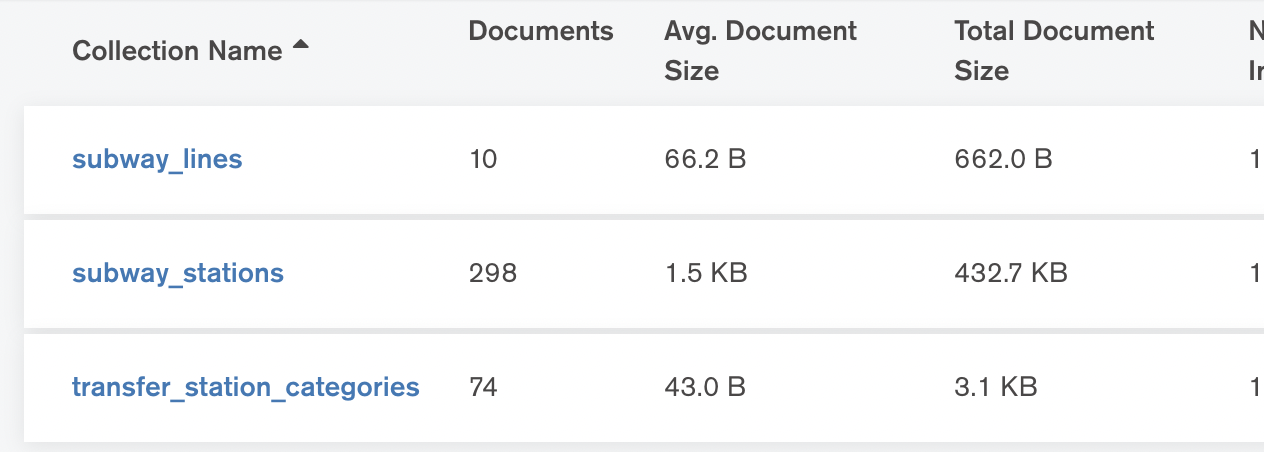
우선 테이블을 5개에서 3개로 줄였다. 사라진 테이블(collection)
station_names와station_time_information의 데이터는 Embedded 방식으로subway_stations(collection)에 필드값으로 저장하기로 했다.-
Collection 목록
-
subway_stations(Collection)의 구조

-
-
여기서 한 가지 의문이 생긴다. 바로 Embedded 방식으로 저장할 테이블(MongoDB에선 Collection이지만 편의상 테이블이라 하겠다...)을 고른 기준이 무엇이냐는 것이다. 기준은 두 가지였다. 첫 번째는 '해당 테이블의 데이터가 앞으로 얼마큼 자주 변경(Update)될 것인가?'이고 다른 하나는 '해당 테이블의 데이터를 부모 객체와 별개로 단독 사용이 가능한지의 여부'였다. (이전 글에서 다뤘던 주제다.) 우선,
subway_stations테이블은 단독 사용하는 데이터를 담고 있었다. 또한 향후 역 정보가 추가되면 데이터 확장 가능성이 높기 때문에, Reference 저장 방식을 택했다. -
반면,
station_time_information과station_names의 데이터는 부모 테이블인subway_stations의 데이터와 함께 제공되는 특징을 갖고 있었다. 또한 데이터의 확장성과 수정 가능성도 낮았다. 그래서 두 테이블을subway_stations의 SubDocument로 지정하여 Embedded 방식으로 저장했다. 사실,station_names의 데이터는 추후 새로운 언어가 추가될 가능성이 높아서 Reference 방식으로 저장할 수도 있었다. 하지만 역 이름에 관한 데이터가 단독으로 사용될 가능성은 낮을 뿐더러, Reference 방식을 선택하면 쿼리문이 추가되면서 읽기 성능을 감소시킬 우려가 있어, Embedded 방식을 최종적으로 선택했다.
-
# Mongoose 설치 및 실행하기
-
Mongoose란?
-
Mongoose는 MongoDB 기반 ODM(Object Data Mapping)으로, Node.JS 전용 라이브러리다. ODM이 무엇인지 궁금하다면, 아래의 인용문을 참고하자.
ODM은 데이터베이스(Data)와 객체지향 프로그래밍 언어(Ojbect) 사이 호환되지 않는 데이터를 변환하는 프로그래밍 기법입니다. 즉 MongoDB에 있는 데이터를 여러분의 Application에서 JavaScript 객체로 사용 할 수 있도록 해줍니다.
쉽게 말해 ODM은 프로그래밍 언어(여기선 javascript를 가리킨다)를 써서 쉽게 데이터베이스를 CRUD하도록 도와준다.
-
-
Mongosse의 장점
-
스키마(schema)를 사용할 수 있다.
- NoSQL은 테이블이 존재하지 않는다. 그래서 테이블의 Column 형식에 맞춰 데이터를 삽입해야 하는 RDBMS와 달리, 형식의 제약을 받지 않고 데이터를 넣을 수 있다. 이는 형식에 얽매이지 않고 사용자가 원하는 데이터를 삽입할 수 있어서 장점이 되기도 하지만, 다른 한편으로는 잘못 입력된 데이터가 필터링 없이 저장될 수도 있다는 걸 의미한다. 이 문제를 해결하기 위해 Mongoose에선 스키마(Schema)기능을 제공한다. 스키마는 입력된(추가된) 데이터를 검사하여 스키마 형식에 어긋나는 경우 에러를 반환한다. 또한 스키마를 통해 기본값(default)과 인데스(index)를 지정할 수 있다.
-
프로미스(promise)를 사용할 수 있다.
- javscript를 사용할 땐 비동기 처리(특정 코드의 연산이 끝날 때까지 코드의 실행을 멈추지 않고 다음 코드를 먼저 실행하는 자바스크립트의 특성)와 관련된 문제와 마주할 수밖에 없는데, Mongoose는 이러한 문제를 해결하도록 프로미스(promise) 기능을 제공한다. 가독성 향상을 원한다면 프로미스 대신 async/await을 사용하는 것이 좋다.
-
편리한 쿼리빌더
- ODM을 쓰는 이유는 쿼리 빌더에 있다고 해도 과언이 아니다. 쿼리 빌더를 사용하면 쉽게 쿼리문을 만들 수 있다.
-
populate
- populate를 활용하면 NoSQL인 MongoDB에서도 SQL의 join과 비슷한 효과를 낼 수 있다. populate는 Reference 방식으로 참조한 Collection의 Documnet 객체(데이터)를 한 번의 쿼리문으로 가져오게 해준다. 단 명심할 것은 populate가 중첩될수록 읽기 성능의 저하가 초래된다는 사실이다.
-
-
Mongoose 설치 및 실행
-
Mongoose를 사용할 프로젝트 폴더로 이동(package-lock.json이 있는 경로)
-
npm install mongoose: Mongoose 설치 -
var mongoose = require("mongoose");:.js파일에 입력하여 mongoose 모듈 가져오기 -
var Schema = mongoose.Schema: 스키마(schema) 활성화 코드를 변수 'Schema'에 할당 -
MongoDB와 연결하기
var mongoose = require("mongoose"); const Schema = mongoose.Schema mongoose.connect("mongodb://127.0.0.1:27017/연결하려는 db명", { useNewUrlParser: true, useCreateIndex: true, useUnifiedTopology: true, "auth": { "authSource": "계정에 인증받은 db명" }, "user": "root", "pass": "password" }).then(() => console.log( 'Successfully connected to mongoDB!' )).catch(e => console.error(e));
-
-
Collection 생성
-
_id: _id 필드는 MongoDB에 존재하는 모든 Collection의 Primary key(기본 키)라 할 수 있다. Collection에 데이터가 추가될 때마다 저절로 필드 값이 추가되기 때문에 Schema 생성 시 따로 필드를 지정하지 않아도 된다. 하지만, 사용자가 직접 _id 필드값을 지정하고 싶다면, Schema에서 필드를 지정하여 데이터를 넣을 수 있다. -
required: true: SQL의null=Fasle과 동일하다. -
ref: Collection 이름: 다른 Collection을 Reference 방식으로 참조하고 싶을 때 사용한다. -
[]: 배열 형식으로 데이터를 저장하고 싶을 때 사용한다. 또한 데이터를 Embedded 방식으로 저장할 때도 사용한다. 이러한 경우[Schema 변수명]형식으로 데이터 타입을 지정하면 된다. -
unique: true: SQL의UNIQUE KEY지정과 동일하다. -
mongoose.model("사용할 Collection 이름", Schema 변수명): 인자로 지정한 Schema를 활용하여 model 생성
-
// station_names
// Schema 생성
const StationName = new Schema({
station_id : {type: String, required: true, unique: true},
language_type : Number,
class_code : Number,
name : {type: String, required: true},
});
// model 생성
const station_names = mongoose.model("station_names", StationName)
// subway_stations
const SubwayStation = new Schema({
_id : String,
subway_line_id : {type: Number, ref: 'subway_lines', required: true}, // Reference 방식으로 다른 Collection 참조
transfer_category_id : {type: Number, ref: 'transfer_station_categories'}, // Reference 방식으로 다른 Collection 참조
station_code : String,
is_transfer : {type: Boolean, required: true},
station_names : [StationName], // Embedded 방식으로 데이터를 저장
time_information : [TimeInformation], // Embedded 방식으로 데이터를 저장
});
const subway_stations = mongoose.model("subway_stations", SubwayStation) -
Documnet 생성(데이터 추가)
-
아래의 코드는 위에서 정의된 Schema를 활용해 만든 model
subway_stations을 통해 데이터를 추가하는 함수다. for 반복문 안의 변수data_list는 CSV파일을 배열 형태로 가공한 것이다. -
비동기 처리를 위해 async/await를 사용했다.
-
// data_list에 저장된 데이터를 활용해 Collection에 데이터(Documnet)를 추가하는 함수 생성
const db = async () => {
for (var index in data_list){
var data = data_list[index]
index = parseInt(index)
await subway_stations.create({
_id: data[0],
subway_line_id: parseInt(data[1]),
transfer_category_id: parseInt(data[2]),
station_code: data[3],
is_transfer: Boolean(data[4].replace('\r', '')),
});
};
}
db() // 함수 실행-
Documnet 업데이트(데이터 수정)
-
아래 코드는 위에서 생성한
subway_stations의 station_names필드에 대한 값을 업데이트하는 함수다. station_names필드는 Embedded 방식을 사용했기 때문에, modelsybway_names의 객체들을 데이터로 갖는다. 데이터 추가 방식은 아래와 같다. Embedded 방식으로 저장되는 Document를 SubDocument라고 한다. -
findOneAndUpdate({필드 name : 데이터 },{$push : {필드 name : 데이터}});메서드를 사용하였다. 첫 번째 인자로 업데이트할 Documnet를 찾는 조건을, 두 번째 인자로 수정할 필드값를 지정하면 된다.$push를 사용하면, 새롭게 수정하는 데이터가 기존 데이터를 대체하는 것이 아니라 기존 데이터에 더해 추가된다.
-
// sub_documnet 추가
const db = async () => {
for (var index in data_list){
var data = data_list[index]
index = parseInt(index)
console.log(data);
await subway_stations.findOneAndUpdate({_id : data[0]},{
$push : { station_names : {
station_id : data[0],
language_type : parseInt(data[1]),
class_code : parseInt(data[2]),
name : data[3],
}
}
});
};
}
db()👉 다음 글에선 MongoDB를 활용해 API를 생성하는 방법을 알아볼 예정입니다.
