학습은 모델 파라미터를 변경
하이퍼 파리미터에 따라 더 좋은 모델이 나올 수 있다.
경험에 의해서 결정
예제 6-1 MINST 분류 모델 학습
# 모듈 임포트
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
- 본 예제를 수행하기 위해 필요한 tensor_flow와 matplotlib.pyplot 모듈을 불러왔습니다.
# MNIST 데이터셋 가져오기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 데이터 정규화: 입력 데이터에 대해서만 적용, 데이터 스케일링(data scaling)
x_train, x_test = x_train / 255.0, x_test / 255.0- MINIST 데이터셋을 가져와 데이터를 정규화하는 부분입니다.
텐서프로에서는 MINIST 데이터셋을 기본적으로 제공하고 있습니다.(사람의 손글씨 0~9 숫자를 이미지화한 데이터셋)
load_data() 함수를 이용해 학습 데이터셋과 테스트 데이터셋을 다운로드한 후 넘파이 배열 형태로 가져옵니다.
이때 x_train에는 학습에 필요한 60,000장의 숫자 이미지 데이터 저장
y_train에는 60,000장의 숫자 이미지의 라벨링된 실제 숫자값이 저장, 즉 학습 이미지에는 정답값이 저장
ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000)
train_size = int(len(x_train) * 0.7) # 학습데이터셋 : 검증데이터셋 = 7:3
print(train_size)
train_ds = ds.take(train_size).batch(20)
val_ds = ds.skip(train_size).batch(20)- 학습에 필요한 데이터셋을 랜덤으로 섞은 후 학습용 데이터셋과 검증용 데이터셋을 7:3 비율로 나누어 학습에 필요한 텐서플로 데이터셋 객체를 생성
60,000개의 학습 데이터셋의 70%는 실제 학습용 데이터셋 30%는 학습 검증용 데이터셋으로 사용
배치 사이즈는 20으로 배치 사이즈는 학습 시 샘플 수를 의미하며, 배치 사이즈가 작을수록 가중치 갱신이 자주 일어난다.
#MINST 분류 모델 구성(신경망 모델)
# 케라스의 시퀀셜 모델 방식
# 1) 모델 생성
# 2) 계층 객체를 추기
model = Sequential()
model.add(Flatten(input_shape= (28, 28)))
model.add(Dense(20, activation='relu')) # fully_connected
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='softmax'))
- 신경망 모델을 구성한 부분, 입력층 1개와 은닉층 2개, 출력층 1개로 구성되어 있는 간단한 심층 신경망
케라스에는 모델을 만드는 방법은 2가지입니다. 예전에는 순차 모델을 사용하였습니다. 예제에서 처럼 순차적으로 더해주기 때문에 순차 모델이라 부르며, 신경망을 구성하는 방법 중 가장 기본적인 방법
조금 복잡한 모델을 구성하기 위해서는 함수형 모델 방법을 사용. 이는 신경망 계층을 일종의 함수로 정의하여 모델을 설계하는 방식
신경망의 입력층으로 Flattens() 을 사용 -> 28X28 크기의 2차원 이미지를 1차원으로 평탄화
입력층에서는 활성화 함수 없이 입력된 데이터 그대로 다음 은닉층으로 전달
2개의 은닉층은 Dense()를 사용해 출력 크기가 20, 활성화 함수로 ReLU를 사용하도록 만들어짐.
마지막으로 활성화 함수로 Softmax를 사용하는 출력층을 만듬
숫자 이미지를 판별해야 하는 값은 -~9까지 총 10가징이기 때문에 출력층의 크기를 10으로 지정
출력층 활성화 함수 Softmax
소프트 맥스 함수는 입력받은 값을 출력으로 0~1사이의 값으로 정규화합니다. 이 함수는 출력값들의 총합이 항상 1이 되는 특징을 갖고 있어 결과를 확률로 표현할 수 있습니다.
가장 큰 출력값을 가지는 클래스가 결괏값으로 사용
# 모델 생성
# 컴파일: 1)최적화 함수, 2)손실 함수, 3)평가 지표
model.compile(loss='sparse_categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
- 4에서 정의한 신경망 모델을 실제로 생성하는 부분. 모델의 출력값과 실제 정답의 오차를 계산하는 손실 함수로는 sparce_categorical_crossentropy를 사용하며, 오차를 보정하는 옵티마이저론느 SGD를 사용합니다. 모델의 성능을 평가하는 데 사용하는 측정 항목은 accuracy를 사용합니다.
Optimizer
- optimizer 이라는 단어는 수학적으로 많이 사용되는 단어. 수리 계획 또는 수리 계획 문제라고도 하고 물리학이나 컴퓨터에서의 최적화 문제는 생각하고 있는 함수를 모델로 한 시스템의 에너지를 나타낸 것으로 여김으로써 에너지 최소화 문제라고도 부르기도 합니다.
- 딥러닝에서 Optimization은 학습속도를 빠르고 안정적이게 하는 것이라고 말할 수 있습니다.
출처 : https://gomguard.tistory.com/187
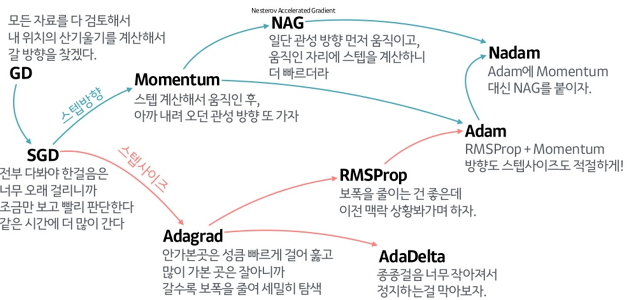
다중 클래스 분류 문제를 해결하는 신경망 출력층의 활성화 함수로 Softmax를 사용하며, 손실 함수로 sparse_categorical_crossentropy를 사용합니다.
# 모델 학습
hist = model.fit(train_ds, validation_data=val_ds, epochs=10)- 앞에서 생성한 모델을 실제 학습합니다. 케라스의 fit()함수를 이용해 학습하는데 인자론는 1)학습에 필요한 데이터셋(train_ds), 2)검증에 필요한 데이터셋(val_ds), 그리고 3)에포크값(epochs=10)을 사용한다.
에포크란 학습 횟수를 의미하며, 에포크값만큼 학습을 수행.
앞서 이야기한 배치와 에포크는 모델 학습 시 중요한 하이퍼파라미터이다. 실험을 통해 최적의 값을 찾는다.
오버피팅:
주어진 데이터에 과하게 학습된 상태를 이야기함. 불필요한 잡음 모델에 과도하게 반영된 상태
모델이 오버피팅 상태일 때는 학습 데이터로는 좋은 성능을 보이지만 실제 데이터에서는 성능이 급격하게 떨어짐
print('모델 평가')
model.evaluate(x_test, y_test)- 6에서 학습이 완료된 모델을 케라스의 evaluate() 함수를 이용해 성능을 평가합니다,
evaluate()함수의 인자에는 테스트용 데이터 셋을 사용
model.save('mnist_model.h5')- 학습이 완료된 모델을 h5 파일 포멧으로 저장합니다. 해당 모델을 사용할 때마다 학습을 다시 하는 것을 방지하기 위해 저장. 모델 파일에는 신경망 구성과 가중치 및 사태 정보 등이 저장되어 있으므로 해당 모델 파일을 다시 불러오면 모델 구성과 학습 없이 빠르게 사용가능
# 학습 결과를 그래프로 그리기
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.plot(hist.history['loss'], 'y', label='train loss')
loss_ax.plot(hist.history['val_loss'], 'r', label='val loss')
acc_ax.plot(hist.history['accuracy'], 'b', label='train acc')
acc_ax.plot(hist.history['val_accuracy'], 'g', label='val acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()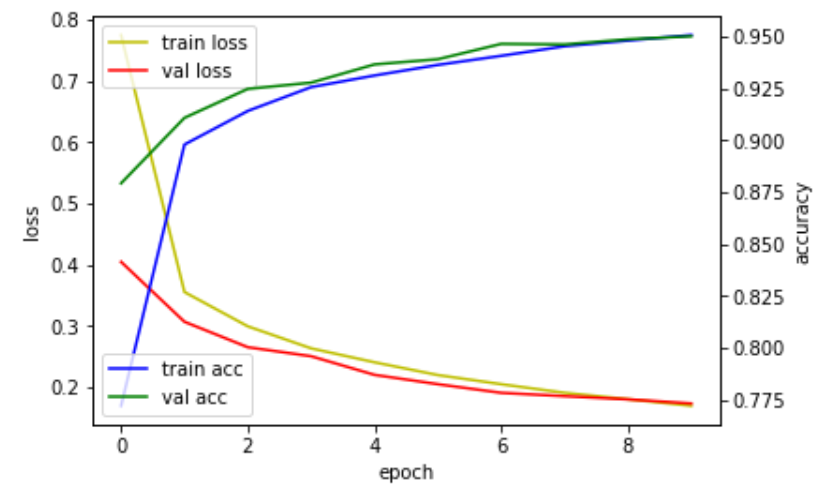
- 학습 과정에서 나온 학습 히스토리 데이터를 그래프로 출력합니다. 그래프에는 손실값과 학습 정확도를 보여줌
X축은 에포크를 의미, Y축은 손실값과 정확도를 의미
6.1.3 학습된 딥러닝 모델
아까 예제에서 저장했던 mnist_model.h5 를 불러와 테스트셋에 포함되어 있는 임의의 숫자 이미지를 분류하는 전체 코드입니다.
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
import numpy as np_, (x_test, y_test) = mnist.load_data()
x_test = x_test / 255.0- MINIST 데이터셋을 가져와 데이터를 정규화
본 예제에서는 이미 학습된 모델을 사용
model = load_model('./mnist_model.h5')
model.summary()
model.evaluate(x_test, y_test, verbose=2)- 케라스의 load_model()함수를 이용해 모델 파일을 불러옴. 성공적으로 모델 파일을 불러왔다면 합습된 모델 객체 반환
summary로 모델 정보 확인
테스트셋 데이터를 이요해 모델 성능을 평가
plt.imshow(x_test[picks], cmap='gray')
plt.show()- matplotlib.pyplot의 imshow()함수를 이용해 테스트셋의 20번째 숫자 이미지를 흑백으로 출력.
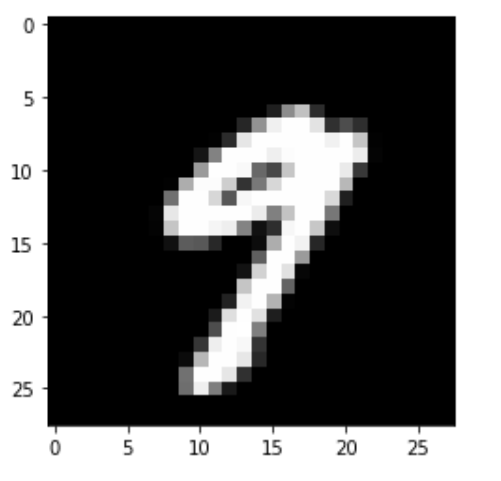
predict = np.argmax(model.predict(x_test[[picks]]))
print(f'손글씨 이미지 예측값: {predict}')케라스 모델의 predict_class를 사용할 수 없어서 np.argmax를 이용해 에측한 값 중 가장 큰 값을 찾아서 출력해줍니다.

6.2 문장 분류를 위한 CNN 모델
CNN(Convolutional Neural Network)모델:
합성곱 신경망으로 불리움
교재에서는 문장 의도 분류를 위해 사용
이미지 분류해내는데 좋은 성능을 가지고 있음
6.2.1 CNN 모델 개념
CNN을 이해하려면 합성곱과 풀링연산이 무엇인지 알아야 합니다.
합성곱이란 합성곱 필터로 불리는 특정 크기의 행렬을 이미지 데이터 행렬에 슬라이딩하면서 곱하고 더하는 연산을 의미
합성곱 필터는 경우에 따라 마스크, 윈도우, 커널 등 다양하게 불림
합성곱을 통해 나온 결과를 특징맵이라 부릅니다. 합섭곱 연산을 거칠 때마다 필터 크기와 스트라이드값에 따라 특징맵의 크기가 작아지는데 이를 방지하기 위해 패딩을 사용
패딩은 주로 출력 크기를 조정할 목적으로 사용, 패딩 처리된 영역은 0으로 채워집니다.
정리하자면 입력 데이터 크기와 패딩, 스트라이드 값에 의해 출력 데이터의 크기가 결정됩ㄴ디ㅏ.
풀링 연산이란 합성곱 연산 결과로 나온 특징맵의 크기를 줄이거나 주요한 특징을 추출하기 위해 사용하는 연산
풀링 연산에는 1)최대 풀링, 2)평균 풀링 연산이 있는데, 주로 최대 풀링 연산을 사용
풀링 연산에도 합성곱 연산에서 사용하는 윈도우(필터) 크기, 스트라이드, 패딩 개념이 동일하게 적용
