[CVPR 2020] Orthogonal Convolutional Neural Networks
introduction
CNN의 압도적인 성공에도 불구하고, 여전히 몇가지 약점이 존재한다: overparametrization, gradient exploding/vanishing, etc...
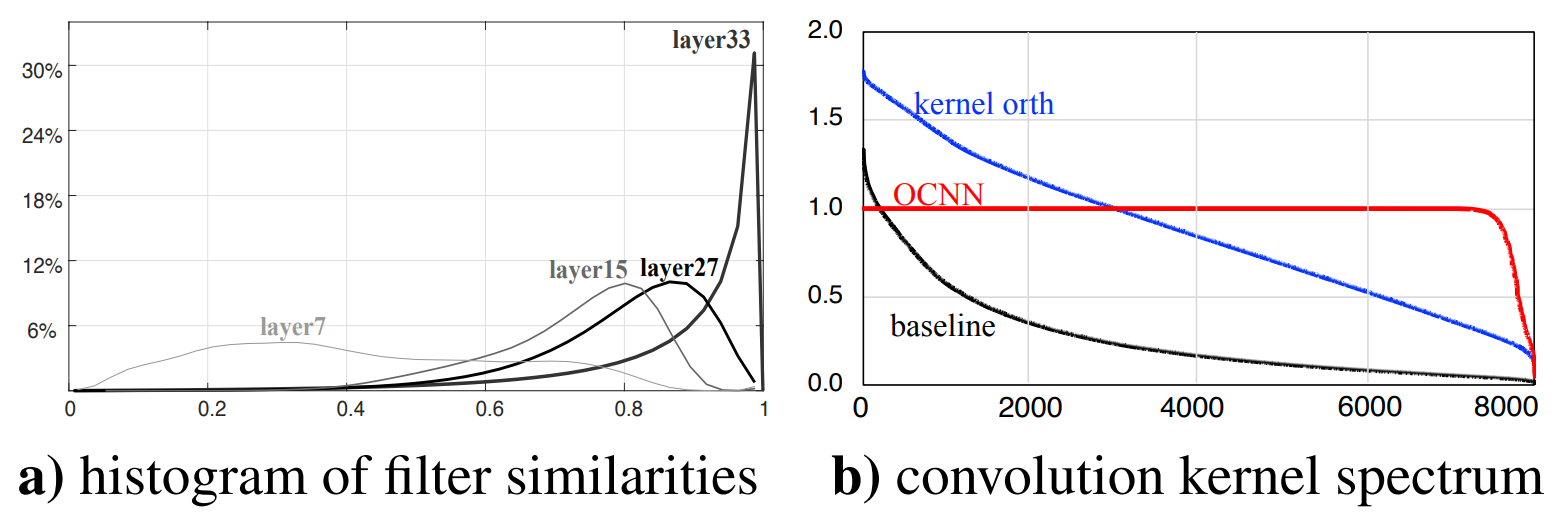
저자들은 이러한 약점의 원인이 convoltional filter간의 high correlation과 long-tailed spectrum에 의해 일어난다고 주장한다.
위의 그래프는 각각 layer의 깊이 별 filter similarity histogram과 kernel spectrum을 plot한것으로, 레이어가 깊어질수록 각 convolutioal kernel들이 비슷한 방향으로 수렴하여 redundant한 parameter들이 늘어나는것을 볼 수 있다.
또한 spectrum의 불균일한 분포는 convolution 연산 이후의 activation에 대한 scale을 일정하게 유지하지 못하게 만들고, 이는 결국 gradient의 불안정함으로 이어진다고 주장한다.
기존의 연구에서는 이러한 filter끼리의 similarity를 낮추고 spectrum을 일정하게 유지하기 위해 orthogonality regularization을 주었다.
하지만 이 논문에서는 기존 연구에서 regulrization을 정의하기 위해 convolution 연산을 matrix-matrix multiplication의 문제로 formulation하는 과정에서 불충분한 점이 있었음을 지적하며, 자신들의 새로운 formulation 방법이 기존의 방법을 커버하는 더 근본적인 방법임을 주장한다.
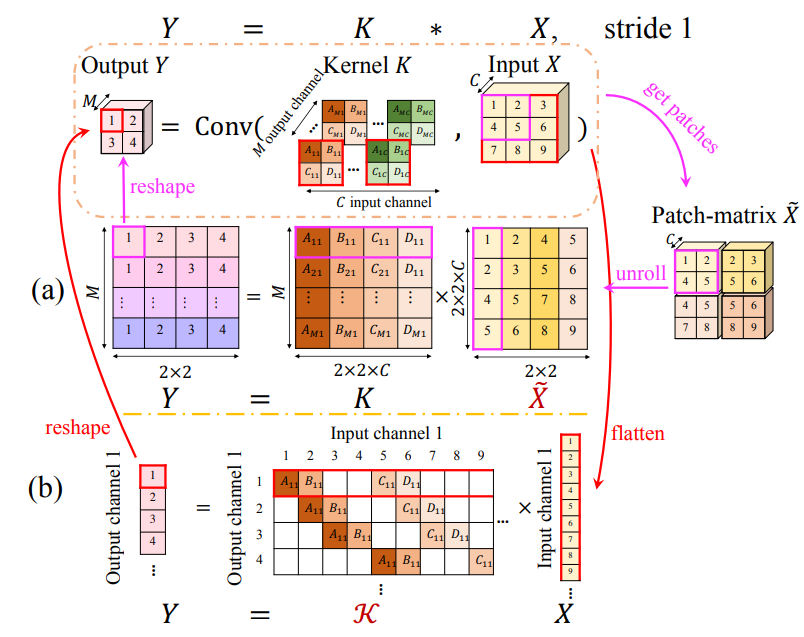
kernel orthogonality
기존의 연구에서는 convolutional operation을 각 patch가 column vector에 대응되는 im2col matrix 에 kernel matrix 가 행렬곱된
꼴로 해석하여, kernel matrix에 orthogonality regularization (i.e. )를 주었다.
하지만 이 formulation은 와 간의 direct relation을 제시해주지 않고 를 사용하기 때문에, 의 orthogonality가 uniform spectrum을 보장해주지 않는다.
orthogonal convolution
이 논문에서는 convolutional operation을 Kernel matrix를 변형하여
꼴의 representation을 가질 수 있는 Doubly block-toeplitz (DBT) matrix 를 정의한 뒤, 에 대해 orthogonality regularization을 주었다.
또한 를 계산하는 과정이 infeasible함을 지적하면서, 대신에 를 regularizer로 사용하는 것으로 의 orthogonality를 얻을 수 있음을 보였다.
Orthogonal Convolution
먼저, orthogonal convolution을 정의하기에 앞서 convolution을 matrix multiplication으로 정의하는 방법부터 살펴보자.
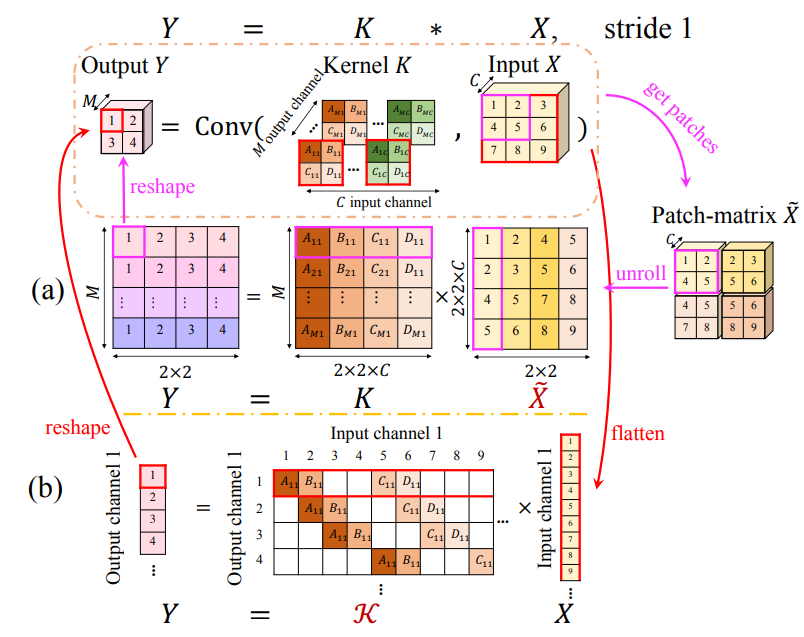
(이미지 재탕 죄송..) 간단하게 3x3 image에 2x2, stride 1 kernel을 적용하는 2d convolution의 예시를 생각해보면, flatten된 9 dimensional vextor 의 번째 component와 kernel의 번째 component를 곱하는 것으로 생각할 수 있다.
이를 matrix로 나타내면 에 doubly block-toeplitz matrix 를 곱한 것으로 이해할 수 있다.
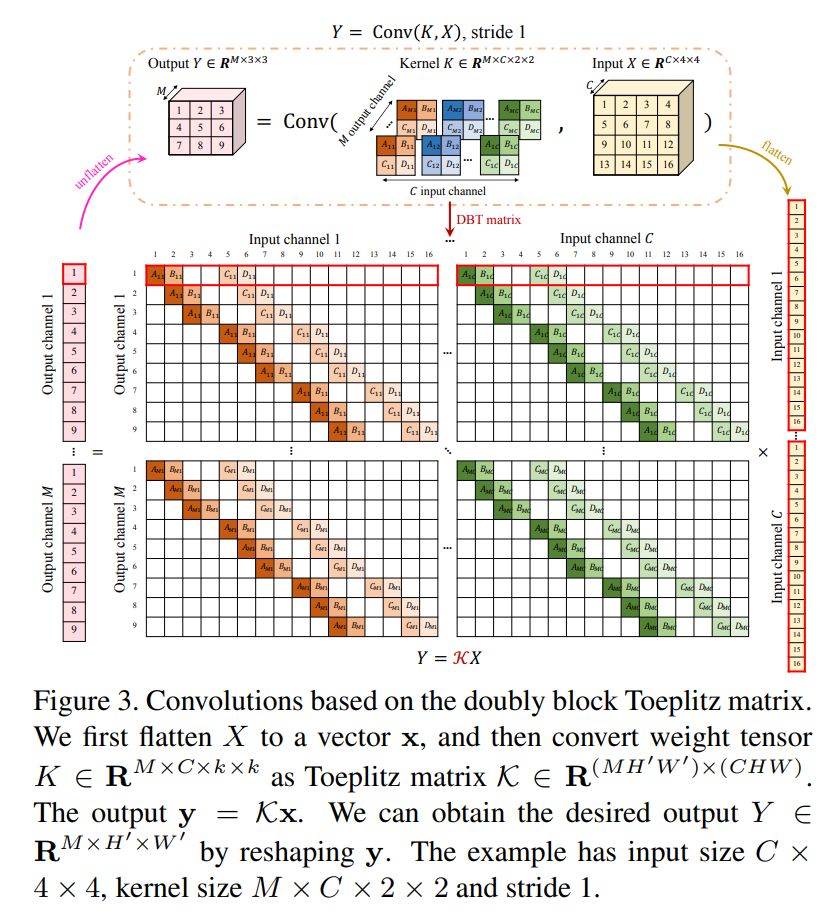
이제 Input tensor 에 M개의 kernel 를 사용하여 convolutional operation 를 행한다고 생각해보자.
이 때 를 flatten한 vector 에 대해 각 block이 번째 channel에 대한 번째 kernel의 convolution으로 작용하는 를 생각하면,
의 꼴로 연산을 나타낼 수 있다.
Convolutional Orthogonality
간단하게 인 케이스에 대해 먼저 생각해보자.
가 orthogonal하다는 것은 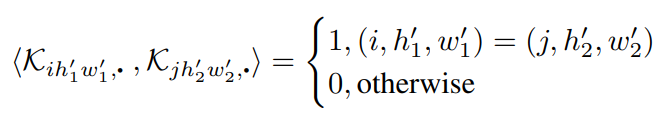
을 만족한다는 것이고, 이 때
iff and
이므로,
iff
이 된다.
또한 인 케이스에 대해서는
두 조건이 MSE sense에 대해 동일하므로 위의 regularizer를 사용하는게 문제가 없다.
마지막으로 kernel orthogonality에 대해서

위의 조건을 만족하여야 하는데, 이는 orthogonal convolution의 필요조건중 하나이므로, 이 regularization이 기존의 방법을 포함하는 방법임을 보여준다.
Result
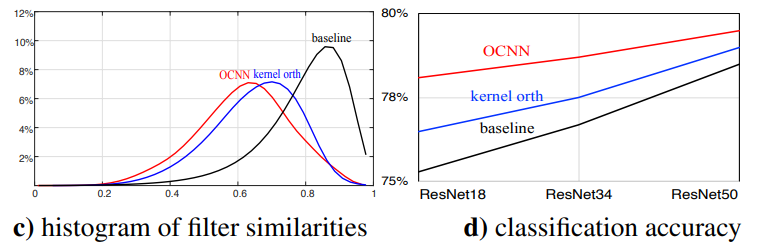
Similarity도 낮추고 성능도 올라갔다고 합니다.
와~
