들어가는 말
공부한걸 블로그에 포스팅하는게 왜이리 힘든지 모르겠다 ㅎㅎ;; 오랜만에 깊게 고민한 사항이 있어 포스팅하기로 마음먹었다.
티켓팅 서비스는 순간적으로 많은 트래픽이 몰려 서비스가 장애가 일어날 수 있으므로 고가용성 구축이 필수 요소이다.
티켓팅 서비스를 구현하며 좌석의 선점권을 확인하기 위해 redis를 사용하기로 했다. redis를 사용하여 빠르게 데이터를 읽으며 좌석 선점 여부를 확인할 것이다. 좌석 선점 여부를 redis에 저장하고 상태를 pub/sub 구조를 통해 실시간으로 체크한다.
고민한 것
하지만, 이 redis 서버가 장애가 난다면??? redis는 캐시이기 때문에 그냥 모든 정보가 쓱싹 날아갈 것이다.
이로인해, 좌석을 선점했던 사람들, 이미 선점된 좌석을 선택한 사람들 모두 당황스러울 것이다!
redis 정보의 유실을 방지하고, 서버에 일시적인 장애가 발생하더라도 다른 redis 노드를 통해 데이터를 유지하고 서비스가 지속될 수 있도록 redis 고가용성을 위한 아키텍처를 도입할 예정이다.
고가용성 구성 방식
여러 레퍼를 찾아본 결과 sentinal을 사용하는 방법과 클러스터를 구성하는 방법 두가지를 통해 고가용성을 달성한다.
이중화 + 센티널(HA, 무중단 서비스)
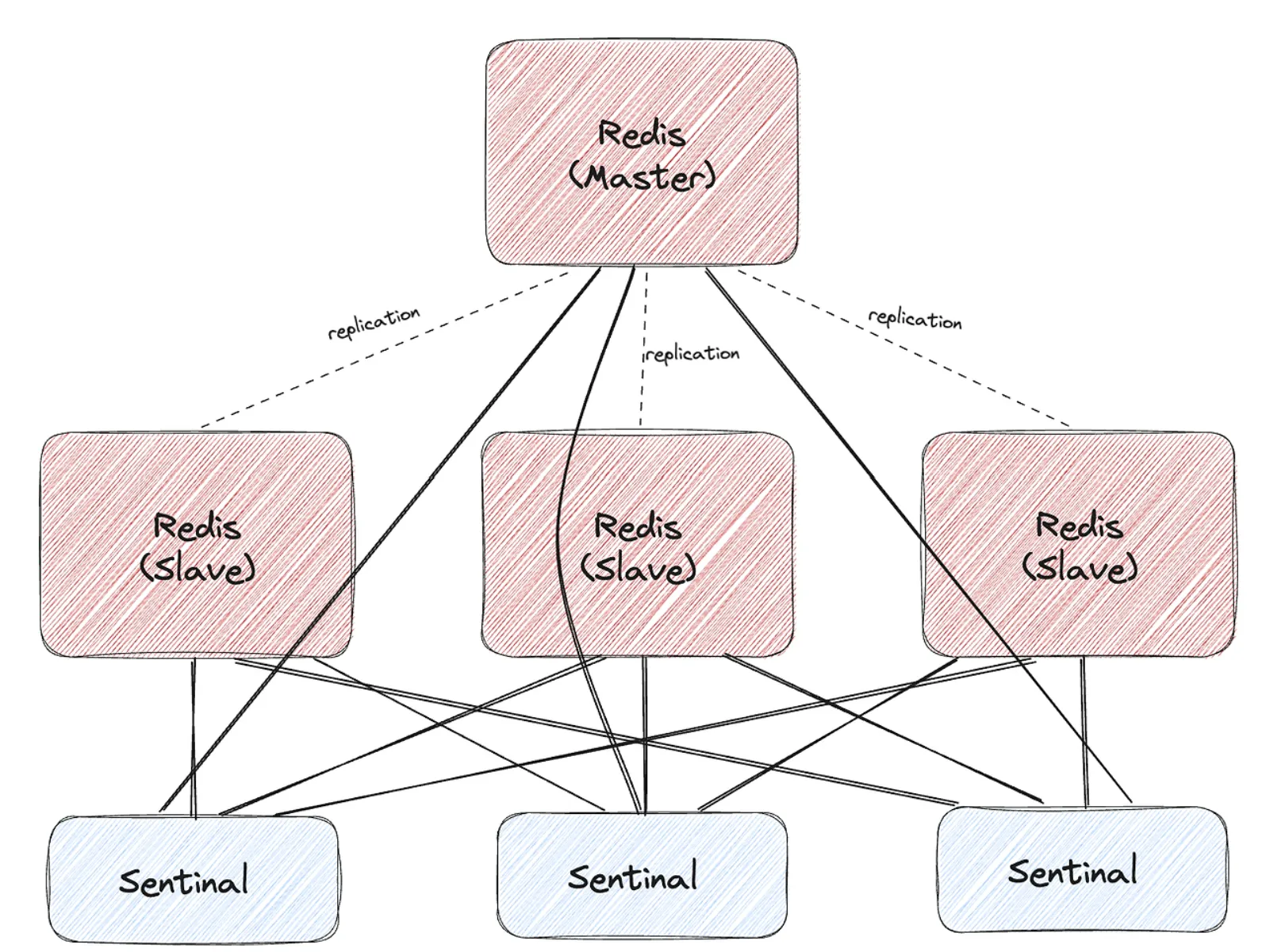
Master & Slave 구성에 각 서버를 감시하도록 하도록 하는 센티널을 추가해서 구성한 아키텍처를 말한다. 센티널은 Master를 감시하고 있다가 Master가 다운되면 Slave를 Master로 승격시킨다. Redis Client(즉 Application)은 새로운 Master로 접속해서 서비스를 계속한다. 센티널은 데이터 처리는 담당하지 않으며, 센티널 자체가 다운되는 상황을 고려해 일반적으로 3대의 센티널을 운용한다.
센티널이란 : Master와 Slave들을 감시하고 있다가 Master가 다운되면 이를 감지해서 관리자의 개입없이 자동으로 Slave를 Master로 올려주는 감시자(보초)를 말한다. 즉 센티널은 감시, 자동 장애조치(Automatic FailOver)의 역할을 하며 알림(FailOver될 때 관리자한테 메일 보내던가 하는..)의 역할도 맡을 수 있다.
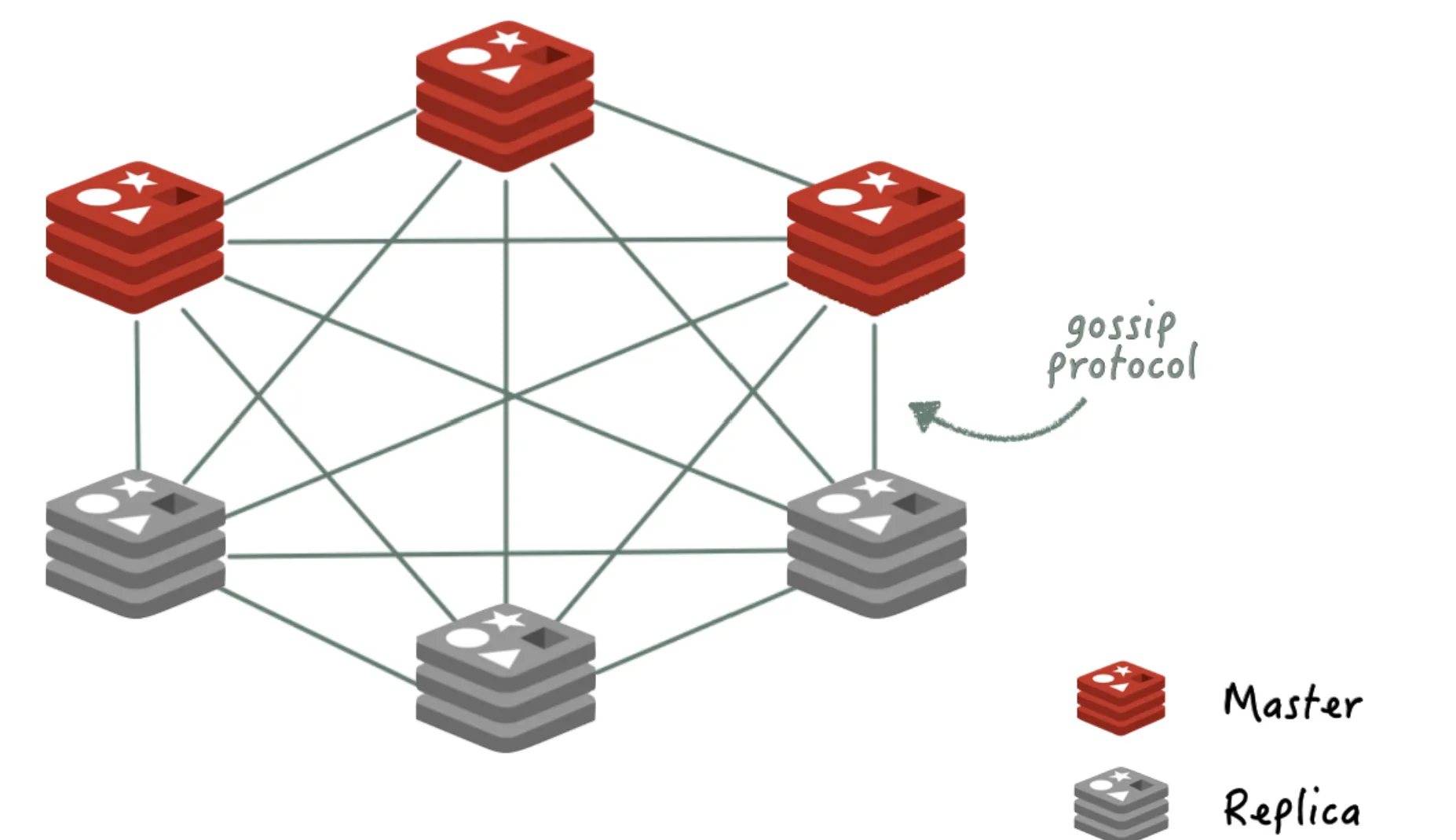
레디스 클러스터(HA)
샤딩을 사용하여 복수의 redis 노드에 데이터를 분할하는 방식으로 아키텍처를 구성하는 것을 말한다. Master가 3대라면, 전체 데이터를 3대에 나누어 저장하는 것이다. (100개가 있다면 1번에 33, 2번에 33, 3번에 34개 이런 식). 데이터들의 key에 hash 값에 따라 어느 Master 서버로 데이터를 둘지 결정하게 된다. 각 Master 서버가 데이터 처리 뿐만 아니라 센티널 역할도 같이 수행하며, 최소 3대의 Master 서버가 필요하다.
샤딩을 통해 데이터들을 분할해서 각 Master 서버에 저장하기 때문에 하나의 서버라도 다운되면 데이터 유실이 생기지 않을까라는 생각을 할 수 있으나, 위 그럼처럼 클러스터를 구성하면 아무리 Master들이 다운되도 하나의 서버만 살아있다면 정상적인 운용이 가능하다.
클러스터 방식을 통해 여러 대의 서버가 하나로 묶여 마치 1개의 시스템처럼 동작하게 되며, 여러 서버에 데이터를 분산하여 저장하기 때문에 부하를 여러 대의 서버로 분산시키므로 더 빠른 속도로 사용자에게 서비스를 제공할 수 있게 된다.
샤딩(Sharding)이란 : 대량의 데이터를 처리하기 위해 여러 개의 데이터베이스에 분할하는 기술 즉 DBMS안에서 데이터를 나누는 것이 아니라 DBMS 밖에서 데이터를 나누는 방식임에 유의하자.
클러스터 vs 센티널
우선 둘 다 고가용성을 챙길 수 있다. 그러나 클러스터는 확장성이 있는 반면, 센티널은 확장성이 없는 아키텍처다. 또한 클러스터는 센티널에 비해 빠른 액세스 속도를 보일 수 있다. 반면 센티널은 클러스터에 비해 배포 및 관리가 용이하다. 따라서, 일반적으로 중소 정도의 규모라면 센티널을, 수평적 확장이 필요한 대규모의 경우는 클러스터를 추천한다고 한다.
두 방식 중 현재 프로젝트에 도입하기 좋은 아키텍처는 클러스터 방식이라고 생각했다. 트래픽이 급격하게 몰림에 따라 발생할 서버의 부하를 줄이기 위해 서버도 추가 증설하여 운영할 계획이기 때문이다. 아래 아키텍처에 보이는 ec2 서버와 동일한 서버가 세 대가 있을 것이다. 아래는 초기에 러프하게 짠 아키텍처이기 때문에 빠진 것이 많다. sqs, ALB, subnet 구성, 레디스 클러스터 등(수정한 아키텍처 자료가 다른 PC에 있어 일단 이거라도 올린다.)
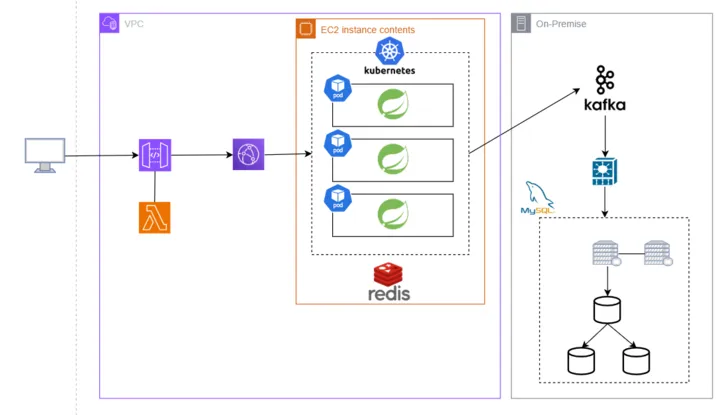
처음에는 위의 방식이 맞다고 생각하고 의심하지 않고 구성하려고 했다. 구현 방법을 찾기 위해 자료 조사를 하던 중 발견한 사실들이 있다.
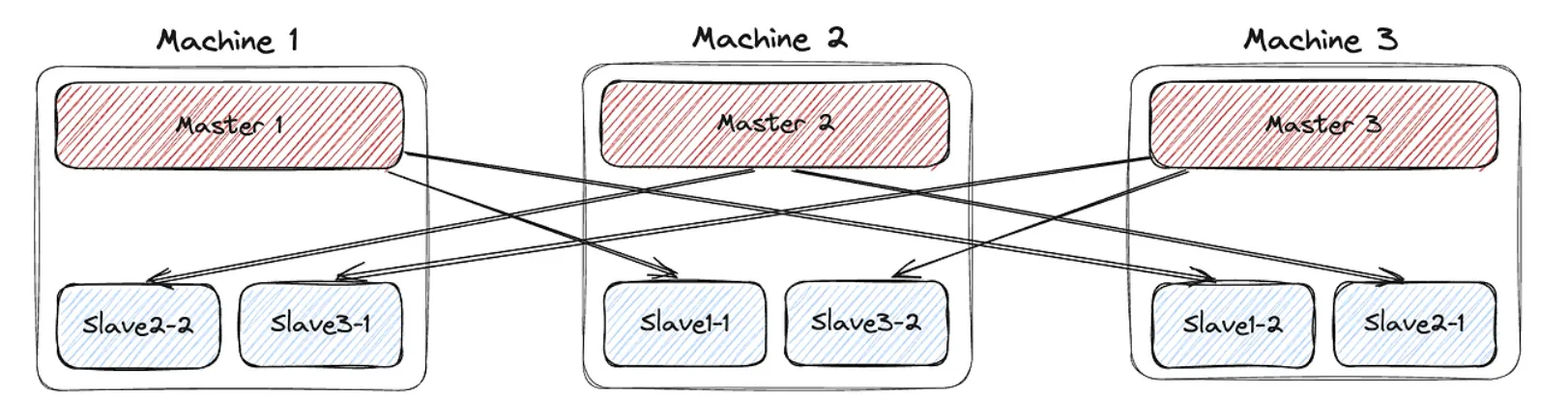
클러스터를 위와 같이 full mesh 형태로 구성하는 방식을 발견했다. 위의 사진처럼 레플리카를 하나만 둔다.
왜 이 구조는 레플리카를 하나만 두는가에 대하여 조사를 했다.
레디스는 싱글스레드 구조이므로 레플리카를 더 붙인다고 성능이 더 좋아지지 않는다. 또한, 레플리카가 마스터와 동기화가 되는데 걸리는 시간이 있기 때문에 레디스를 도입할 정도로 빠르게 정보를 조회해야 하는 서비스에서는 데이터 정합성이 보장되지 않아 치명적일 수 있다.
레디스를 더 붙이는 것이 성능면에서 이득이 없다면 그냥 슬레이브도 붙이지 말고 세개의 마스터만 사용할까?라는 생각도 했지만, hash 값의 범위를 기준으로 각 마스터에 정보가 찢어져서 저장되기 때문에 결국 마스터가 죽으면 해당 hash 값들의 정보를 확인할 수 없기에 이중화는 필수이다.
✅ 왜 Redis 클러스터에 슬레이브가 필요한가?
| 이유 | 설명 |
|---|---|
| 🧱 장애 복구 | 마스터 노드 하나 죽으면 → 해당 슬롯 범위의 모든 키에 접근 불가 |
| 🔁 자동 Failover | Redis Cluster는 마스터가 죽으면 슬레이브가 자동 승격 가능 |
| 💾 데이터 유실 방지 | 단일 노드에 장애 나면 그 슬롯의 데이터 날아감 |
| 📈 서비스 연속성 | 티켓팅 시스템처럼 실시간성이 중요한 서비스에서는 노드 중단 = 서비스 중단 |
서버에 문제가 생겨 (예를 들면 화재나 지진으로 인한 데이터센터 문제 발생?) 해당 서버의 레디스를 사용하지 못하는 상황에 슬레이브도 같은 서버에 있다면 이중화한 소용이 없을 것이다. 이를 위해, 자신의 슬레이브는 다른 영역에 설치한다고 한다.
이중화의 핵심은 물리적 분리이다.
ex) 마스터1, 2, 3과 슬레이브 1, 2, 3이 있고 az1, 2, 3이 있다면 az1에는 마스터1과 슬레이브2, az2에는 마스터2와 슬레이브3 이런식으로 교차 배치를 한다.
┌────────────┐
│ Master A │◄──► Slave A
│ Slot 0-5460 │
└────────────┘
▲
┌────────────┐
│ Master B │◄──► Slave B
│ Slot 5461-10921 │
└────────────┘
▲
┌────────────┐
│ Master C │◄──► Slave C
│ Slot 10922-16383 │
└────────────┘
여기서 의문이 드는 점은 그렇다면 마스터가 죽었을 때, 승격이 되는 슬레이브는 같은 AZ의 슬레이브인가? 죽은 마스터의 슬레이브인가? 라는 의문점이 들었다. 이를 주제로 함께 공부하는 친구들과 이야기를 나눈 결과, 의견이 분분했다. Multi-AZ 간 슬레이브 승격이 일어나면, AZ간 통신 비용도 발생하고 비효율적이어서 같은 AZ에서 승격이 일어날 것 VS 마스터가 죽은 것을 슬레이브가 인지할 방법이 없어서 자신의 슬레이브가 승격할 것이라는 의견이 존재했다. (사실 전자에 대한 의견이 더 우세했고 나 또한 그럴듯 하다고 생각했다)
검증
마스터 승격 방식에 대한 의문과 위의 클러스터 구성 방식 중 chat gpt에게 물어본 결과가 섞여 있기에 자료의 검증을 위해 추가 조사를 진행했다.
AWS의 Elastic Cache가 위와 같이 Multi-AZ로 구성되어있다고 한다.

또한 마스터 승격은 죽은 마스터의 슬레이브가 한다고 한다. 아무래도 슬레이브가 마스터와 통신을 하고 있어 그 흐름이 더 자연스러운게 맞는 것 같긴하다.
결론
결론적으로, 마스터-슬레이브 각각 한 개씩 쌍을 이룬 클러스터를 Multi-AZ로 구축하고 각 슬레이브를 교차배치하여 고가용성을 확보하는 전략을 쓰기로 했다. 이제 구축에 성공하기만 하면 된다^^.
참고 자료
Redis의 개념과 Redis에서 고가용성(High Availability)를 확보하는 방법
[AWS] Amazon ElastiCache란? 쉽게 특징 정리 (인메모리 DB, Redis, Memcached)
