
KoBERT를 이용한 다중감성분류모델 구현하기
0.KoBERT란?
KoBERT SKT Brain에서 배포한 한국어 버전의 자연어 처리 모델이다. KoBERT를 이해하기 위해서는 먼저 BERT 모델이 무엇인지 알아야 한다.
- BERT(Bidirectional Encoder Representations from Transformers)는 2018년에 구글이 공개한 사전 훈련된 모델이다. 해당 모델은 방대한 양의 데이터(약 33억개 단어)로 먼저 학습(pretrain)되어 있고, 자신의 사용 목적에 따라 파인튜닝(finetuning)이 가능하다는 점에서 많은 인기를 얻었다.
- KoBERT는 그러한 BERT 모델에서 한국어 데이터를 추가로 학습시킨 모델로, 한국어 위키에서 5백만개의 문장과 54백만개의 단어를 학습시킨 모델이다. 따라서 한국어 버전의 BERT라고도 할 수 있다.
첫 포스트로는 그러한 KoBERT모델을 통해 텍스트에 담긴 7개의 감정을 분류하는 다중감성분류모델을 구현하고자 한다.
1. 프로젝트 설명
내가 현재 학교에서 진행하고 있는 프로젝트는 다음과 같다.
- Screen OCR을 통해 소설 텍스트 데이터 수집 및 전처리
- KoBERT를 이용해 텍스트를 다중감성으로 분류
- 문단별로 감성 퍼센트 데이터를 분석하여 주된 감성 파악
- 파악된 감성과 매치되는 음악 데이터를 연결하여 유저에게 제공
- 소설을 읽으며 감성이 달라질때마다 적절하게 음악을 자동으로 변경
나는 해당 프로젝트에서 분석의 핵심이 되는 NLP, 즉 KoBERT를 이용한 자연어 처리 파트를 맡아 진행하고 있다. 이를 위해 첫 포스트는 KoBERT를 이용해, 한국어 대화 문장을 7가지의 감정(기쁨, 슬픔, 놀람, 분노, 공포, 혐오, 중립)으로 분류하는 모델을 학습시키려고 한다.
이번에 소개할 코드는 SKT Brain에서 제공하는 KoBERT 깃허브에 있는 naver_review_classifications_pytorch_kobert를 바탕으로 작성했다.
2. 데이터 수집 및 병합
데이터 수집
내가 이번 프로젝트를 위해 사용한 한국어 대화 문장 데이터는 총 2개이다.

- SNS 글 및 온라인 댓글에 대한 웹 크롤링을 실시하여 선정된 AIHUB의 공공 데이터셋
- 약 3만 9천건의 데이터 셋 (기쁨, 슬픔, 놀람, 분노, 공포, 혐오, 중립의 7개 감정)
- 한국어 감성 데이터셋을 상세한 감정 라벨링(감정 대분류와 소분류로 구분)과 함께 제공하는 AIHub의 공공 데이터셋
- 약 사만 건의 데이터 셋 (기쁨, 당황, 분노, 불안, 상처, 슬픔의 6개 감정)
- 데이터 병합을 위해 감정 대분류와 사람문장을 남기고, 감정 소분류는 누락
데이터 병합
두 데이터셋을 수집한 후 어떤 데이터를 사용해야 가장 정확하고 효율적인 감성분석이 가능할지 비교하기 위해 모델을 각각 구현시켜 비교해보려 했다.
이때, 한국어 단발성 대화 데이터셋과 감성대화말뭉치는 감성 레이블 종류와 개수가 서로 달라 비교 기준을 어떻게 해야할 지에 대한 고민이 들었다. 적절한 기준을 사용하여 병합해야 모델의 정확도를 높일 수 있기 때문이다.
그래서 일단 데이터셋 두개를 대략적으로 살펴보면서 각각의 감성이 구체적으로 어떻게 분류되어 있는지 판단하였다. 단, 이는 저자의 주관에 의해 분류한 것이기 때문에 혹시 비슷하게 따라하게 된다면 한번쯤 데이터셋을 관찰해 보길 바란다.
나는 일단 감성 레이블이 많은 한국어 단발성 대화 데이터셋을 주된 바탕으로 삼고 거기에 감성대화말뭉치를 병합하는 형태로 데이터를 처리했다. 이전 결과와 병합한 결과는 다음과 같다.
한국어 단발성 대화 데이터셋 (7)
: 공포 놀람 분노 슬픔 중립 행복 혐오
감성대화말뭉치 (6)
: 기쁨 당황 분노 불안 상처 슬픔
<병합된 결과>
한국어 단발성 대화 데이터셋 (7)
: 공포 놀람 분노 행복 슬픔 중립 혐오 (7)
: 불안 당황 분노 기쁨 슬픔,상처 (5)감성대화말뭉치 데이터셋을 살펴본 결과, 상처와 슬픔의 감성이 매우 유사하다는 판단이 들었다. 그래서 상처-슬픔의 데이터는 하나의 감성으로 병합하여 감성대화말뭉치의 최종 감성 클래스를 5개로 줄여 한국어 단발성 대화 데이터셋에 추가했다. 또한 불안은 공포로, 당황은 놀람으로, 기쁨은 행복으로, 분노는 슬픔으로 분류했다.
중립과 혐오의 경우 감성대화말뭉치 데이터에서는 분류하기 어려워 공란으로 두었다. 그런 결정에는 여러 이유가 있는데 내가 NLP분석을 하려는 주된 목적이 소설 텍스트를 분석하는 것이기 때문에, 혐오 데이터는 누락해도 괜찮다고 생각하여 진행해보았다.
3. 데이터 분석 후 최적의 데이터 채택
나는 그렇게 총 세개의 데이터셋을 구축하여 학습 모델을 구축했다.
- 한국어 단발성 대화 데이터셋만 사용
- 감성대화말뭉치 데이터셋만 사용
- 한국어 단발성 대화+감성대화말뭉치를 병합한 데이터셋 사용
그 후, 만들어진 모델에 각각 특정 감성이 적용된 16개의 문장을 일괄적으로 테스트해보았고, 그 정확도를 따지기로 했다. 실행 결과는 다음과 같다.
-
한국어 단발성 대화 데이터셋 사용 (7emotions_model_1)
→ 16개의 문장 중 7개의 문장에 오류(!!)가 발생했다.
-실행결과
말을 입력해주세요 : 아들에게는 없었는데 아내에게는 가끔 당혹스러울 때가 있어. 공포가 느껴집니다. !!말을 입력해주세요 : 친구가 우리 가게에 외상만 계속하고 결제를 미뤄 스트레스 받아. 슬픔이 느껴집니다. 말을 입력해주세요 : 새로운 사업에 투자하고 싶은데 너무 조심스러워. 어떻게 해야 할지 모르겠어. 공포가 느껴집니다. !!말을 입력해주세요 : 대책 없이 계속 물건을 사들이는 아내 때문에 매일 말다툼한다니까. 공포가 느껴집니다. !!말을 입력해주세요 : 계속해서 핵심을 잡지 못하고 겉도는 회의가 계속되어 답답해. 슬픔이 느껴집니다. 말을 입력해주세요 : 내가 수술받은 의사가 의료 사고가 잦은 의사였어. 그 사실을 알게 되니 화가 많이 나네. 분노가 느껴집니다. 말을 입력해주세요 : 요즘 배가 많이 나왔어. 건강을 위해 운동을 해야 하는데 그러지 못해서 한심해. 슬픔이 느껴집니다. 말을 입력해주세요 : 친구들과 노후에 대한 이야기를 하다 보니 서로 노후 자금 차이가 상당히 컸어. 슬픔이 느껴집니다. !!말을 입력해주세요 : 지금 갑자기 경찰서에서 연락이 왔는데 내 여자 친구가 거기 있대. 이게 무슨 일이야. 놀람이 느껴집니다. 말을 입력해주세요 : 나 대학에 쉽게 갈 수 있을 것 같아. 학원 선생님들 실력이 정말 믿을 만해! 행복이 느껴집니다. 말을 입력해주세요 : 아들이 늦게 자식을 봤는데 몸이 약해서 인큐베이터에 있었는데 다행히 건강하게 퇴원했다고 해. 정말 다행이야. 행복이 느껴집니다. !!말을 입력해주세요 : 이제 곧 결혼해. 바로 아이가 생길 거라 믿어. 중립이 느껴집니다. !!말을 입력해주세요 : 일 할 곳이 없어 폐지를 주우러 다니고 있는 내 모습을 보니 너무 초라한 것 같아. 놀람이 느껴집니다. 말을 입력해주세요 : 요즘 허리가 아파 모임에도 못 나가고 하루 종일 집에만 있어. 슬픔이 느껴집니다. 말을 입력해주세요 : 이제 취업을 해야 되는데 전공에 맞는 일자리가 없어. 너무 막막해. 슬픔이 느껴집니다. !!말을 입력해주세요 : 집 앞 골목에서 어린애들이 담배를 피우고 있기에 나갔더니 세상이 무너지더라. 놀람이 느껴집니다. -
감성 대화 말뭉치 사용(7emotions_model_2)
→ 16개의 문장 중 4개의 문장에 오류가 발생했다.
실행결과
말을 입력해주세요 : 아들에게는 없었는데 아내에게는 가끔 당혹스러울 때가 있어. 공포가 느껴집니다. 말을 입력해주세요 : 친구가 우리 가게에 외상만 계속하고 결제를 미뤄 스트레스 받아. 공포가 느껴집니다. !!말을 입력해주세요 : 새로운 사업에 투자하고 싶은데 너무 조심스러워. 어떻게 해야 할지 모르겠어. 슬픔이 느껴집니다. 말을 입력해주세요 : 대책 없이 계속 물건을 사들이는 아내 때문에 매일 말다툼한다니까. 분노가 느껴집니다. !!말을 입력해주세요 : 계속해서 핵심을 잡지 못하고 겉도는 회의가 계속되어 답답해. 공포가 느껴집니다. 말을 입력해주세요 : 내가 수술받은 의사가 의료 사고가 잦은 의사였어. 그 사실을 알게 되니 화가 많이 나네. 분노가 느껴집니다. 말을 입력해주세요 : 요즘 배가 많이 나왔어. 건강을 위해 운동을 해야 하는데 그러지 못해서 한심해. 놀람이 느껴집니다. 말을 입력해주세요 : 친구들과 노후에 대한 이야기를 하다 보니 서로 노후 자금 차이가 상당히 컸어. 놀람이 느껴집니다. 말을 입력해주세요 : 지금 갑자기 경찰서에서 연락이 왔는데 내 여자 친구가 거기 있대. 이게 무슨 일이야. 놀람이 느껴집니다. 말을 입력해주세요 : 나 대학에 쉽게 갈 수 있을 것 같아. 학원 선생님들 실력이 정말 믿을 만해! 행복이 느껴집니다. 말을 입력해주세요 : 아들이 늦게 자식을 봤는데 몸이 약해서 인큐베이터에 있었는데 다행히 건강하게 퇴원했다고 해. 정말 다행이야. 행복이 느껴집니다. 말을 입력해주세요 : 이제 곧 결혼해. 바로 아이가 생길 거라 믿어. 행복이 느껴집니다. !!말을 입력해주세요 : 일 할 곳이 없어 폐지를 주우러 다니고 있는 내 모습을 보니 너무 초라한 것 같아. 놀람이 느껴집니다. !!말을 입력해주세요 : 요즘 허리가 아파 모임에도 못 나가고 하루 종일 집에만 있어. 놀람이 느껴집니다. 말을 입력해주세요 : 이제 취업을 해야 되는데 전공에 맞는 일자리가 없어. 너무 막막해. 슬픔이 느껴집니다. 말을 입력해주세요 : 집 앞 골목에서 어린애들이 담배를 피우고 있기에 나갔더니 세상이 무너지더라. 슬픔이 느껴집니다. -
두 데이터를 병합하여 사용(7emotions_model)
→ 16개의 문장 중 2개의 문장에 오류가 발생했다.
실행결과
말을 입력해주세요 : 아들에게는 없었는데 아내에게는 가끔 당혹스러울 때가 있어. 공포가 느껴집니다. 말을 입력해주세요 : 친구가 우리 가게에 외상만 계속하고 결제를 미뤄 스트레스 받아. 공포가 느껴집니다. 말을 입력해주세요 : 새로운 사업에 투자하고 싶은데 너무 조심스러워. 어떻게 해야 할지 모르겠어. 공포가 느껴집니다. 말을 입력해주세요 : 대책 없이 계속 물건을 사들이는 아내 때문에 매일 말다툼한다니까. 분노가 느껴집니다. !!말을 입력해주세요 : 계속해서 핵심을 잡지 못하고 겉도는 회의가 계속되어 답답해. 공포가 느껴집니다. 말을 입력해주세요 : 내가 수술받은 의사가 의료 사고가 잦은 의사였어. 그 사실을 알게 되니 화가 많이 나네. 분노가 느껴집니다. 말을 입력해주세요 : 요즘 배가 많이 나왔어. 건강을 위해 운동을 해야 하는데 그러지 못해서 한심해. 놀람이 느껴집니다. 말을 입력해주세요 : 친구들과 노후에 대한 이야기를 하다 보니 서로 노후 자금 차이가 상당히 컸어. 놀람이 느껴집니다. 말을 입력해주세요 : 지금 갑자기 경찰서에서 연락이 왔는데 내 여자 친구가 거기 있대. 이게 무슨 일이야. 놀람이 느껴집니다. 말을 입력해주세요 : 나 대학에 쉽게 갈 수 있을 것 같아. 학원 선생님들 실력이 정말 믿을 만해! 행복이 느껴집니다. 말을 입력해주세요 : 아들이 늦게 자식을 봤는데 몸이 약해서 인큐베이터에 있었는데 다행히 건강하게 퇴원했다고 해. 정말 다행이야. 행복이 느껴집니다. 말을 입력해주세요 : 이제 곧 결혼해. 바로 아이가 생길 거라 믿어. 행복이 느껴집니다. !!말을 입력해주세요 : 일 할 곳이 없어 폐지를 주우러 다니고 있는 내 모습을 보니 너무 초라한 것 같아. 놀람이 느껴집니다. 말을 입력해주세요 : 요즘 허리가 아파 모임에도 못 나가고 하루 종일 집에만 있어. 슬픔이 느껴집니다. 말을 입력해주세요 : 이제 취업을 해야 되는데 전공에 맞는 일자리가 없어. 너무 막막해. 슬픔이 느껴집니다. 말을 입력해주세요 : 집 앞 골목에서 어린애들이 담배를 피우고 있기에 나갔더니 세상이 무너지더라. 슬픔이 느껴집니다.
세 모델을 비교 분석한 결과, 두가지 데이터를 모두 사용하여 병합한 세번째 모델의 정확도가 가장 높았다. 그래서 해당 데이터셋을 활용한 모델을 채택하였다.
자, 이제 위에서 채택한 데이터셋을 바탕으로 내가 모델을 어떻게 분석했는지 본격적으로 설명해보도록 하겠다.
다중감성분류모델 실습 설명
1. Colab 환경 설정
먼저 Colab에서 환경을 구현하기 위해 필요한 라이브러리와 모듈을 설치해주자.
#필요 패키지 설치
!pip install mxnet
!pip install gluonnlp pandas tqdm
!pip install sentencepiece
!pip install transformers==3.0.2
!pip install torch
!pip install pandas
#KoBERT 깃허브에서 불러오기
!pip install git+https://git@github.com/SKTBrain/KoBERT.git@masterimport torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm, tqdm_notebook
import pandas as pd#KoBERT
from kobert.utils import get_tokenizer
from kobert.pytorch_kobert import get_pytorch_kobert_model
#transformer
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup#GPU 설정
device = torch.device("cuda:0")#bertmodel의 vocabulary
bertmodel, vocab = get_pytorch_kobert_model()2. 데이터셋 전처리
앞서 수집해온 데이터셋을 불러오기 위해 구글드라이브를 연동해준다. 이후 자신의 데이터셋이 저장된 경로를 통해 데이터셋을 2차원 리스트를 매개변수로 저장하는 데이터프레임 형식으로 chatbot_data 에 받아오자.
이때, 데이터프레임은 pandas 라이브러리에서 사용하는 데이터 구조를 칭한다. pandas는 파이썬을 이용한 데이터 분석과 같은 작업에서 필수 라이브러리로 알려져있다.
참고로 파일이 xlsx형식이라면 pd.read_excel을 사용하여 읽어줘야 하고 csv형식이라면 pd.read_csv를 사용하여야 한다는 것을 주의하자.
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
chatbot_data = pd.read_excel('/content/drive/MyDrive/데이터셋/data.xlsx')데이터가 잘 불러와졌는지 확인하기 위해 데이터 개수와 10개의 샘플 데이터를 랜덤으로 출력해보자.
len(chatbot_data) #79473
chatbot_data.sample(n=10)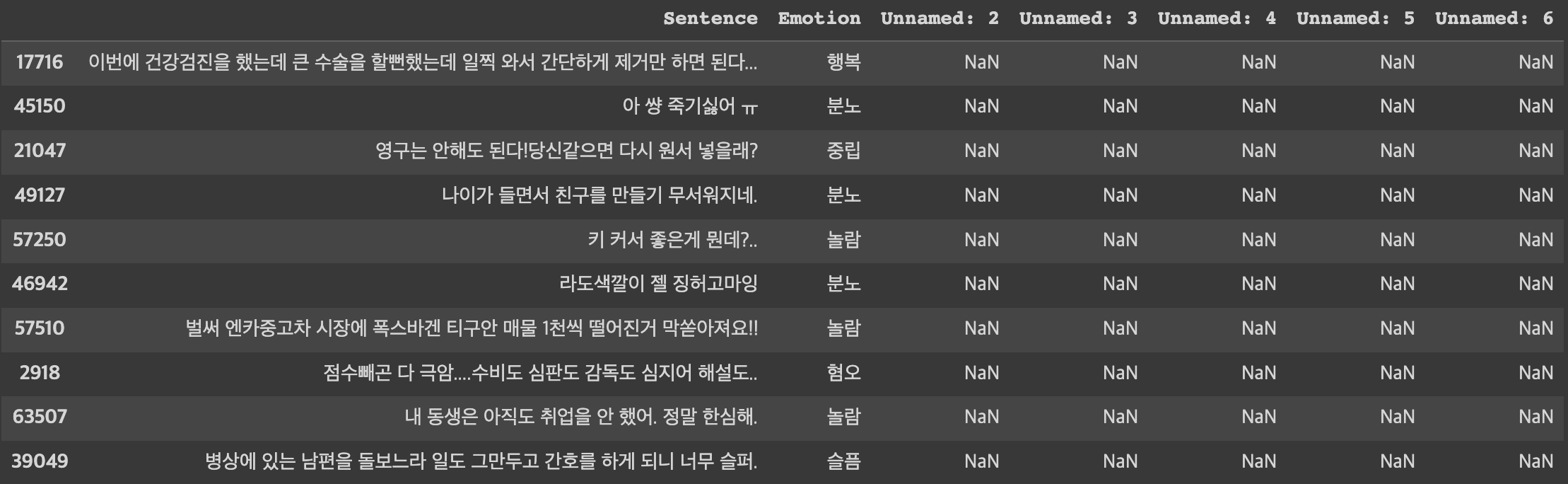
제대로 불러와졌다. 해당 데이터는 사람문장sentence과 감성레이블emotion로 구성되어 있다. 먼저, 데이터 분석을 위해 감성 레이블을 정수로 변환해주자. (0~6)
chatbot_data.loc[(chatbot_data['Emotion'] == "공포"), 'Emotion'] = 0 #공포 => 0
chatbot_data.loc[(chatbot_data['Emotion'] == "놀람"), 'Emotion'] = 1 #놀람 => 1
chatbot_data.loc[(chatbot_data['Emotion'] == "분노"), 'Emotion'] = 2 #분노 => 2
chatbot_data.loc[(chatbot_data['Emotion'] == "슬픔"), 'Emotion'] = 3 #슬픔 => 3
chatbot_data.loc[(chatbot_data['Emotion'] == "중립"), 'Emotion'] = 4 #중립 => 4
chatbot_data.loc[(chatbot_data['Emotion'] == "행복"), 'Emotion'] = 5 #행복 => 5
chatbot_data.loc[(chatbot_data['Emotion'] == "혐오"), 'Emotion'] = 6 #혐오 => 6그리고 우리가 사용할 데이터는 sentence와 emotion이니 사용하지 않는 unnamed열과 NaN을 무시하고 필요한 데이터만 가져오도록 하자. data_list 를 선언하여 필요한 데이터만 배열에 넣어주자.
data_list = []
for q, label in zip(chatbot_data['Sentence'], chatbot_data['Emotion']) :
data = []
data.append(q)
data.append(str(label))
data_list.append(data)data_list에 데이터가 잘 저장되었는지 확인하기 위해 길이와 문장을 각각 출력해보자. 결과값은 하단에 함께 첨부했다. 앞서 확인한 chatbot_data와 length가 일치하는 것을 바탕으로 누락 없이 데이터들이 잘 입력되었음을 확인할 수 있다. 데이터들도 [’sentence’, ‘class’]의 형태로 잘 저장되어 있다.
print(len(data_list))
print(data_list[0])
print(data_list[20000])
print(data_list[40000])
print(data_list[60000])
print(data_list[-1])79473
['저러니까 자신보다 어린 사람한테 미개하다는 소리듣지', '6']
['컴백까지 건강챙기시고 멋있는모습으로 만나요?', '5']
['친구들이 나를 힘들게 해서 전학을 가게 되었어. 새로운 곳에서는 천천히 친구들을 사귀어보고 싶어.', '5']
['나는 이직한 지금 회사에 불만이 없어.', '5']
['자꾸만 화가나고 욕을하게됩니다', '3']
['나 너무 우울하고 외로워.', '3']
['친구 관계가 너무 힘들어. 베푸는 만큼 돌아오지 않는 것 같아.', '0']3. 데이터 분리 (train&test)
이제 학습 모델 훈련을 위해 데이터셋을 사이킷런을 이용해 train데이터와 test데이터로 분리해준다.
여기서 사이킷런(Scikit-learn)은 파이썬 머신러닝 라이브러리이다. 사이킷런을 통해 나이브 베이즈 분류, 서포트 벡터 머신 등 다양한 머신 러닝 모듈을 불러올 수 있다.
해당 코드에는 사이킷런 중 train_test_split 모듈을 이용해 4:1로 train&test 데이터를 분류하기로 한다. 분류된 데이터셋의 length를 확인하면 잘 분류된 것을 확인할 수 있을 것이다.
from sklearn.model_selection import train_test_split
dataset_train, dataset_test = train_test_split(data_list, test_size=0.25, random_state=0)
print(len(dataset_train)) # 59604 출력
print(len(dataset_test)) # 19869 출력4. 데이터 전처리 (토큰화, 정수 인코딩, 패딩)
이제 학습 모델을 위한 데이터를 나눠주었다. 그렇다면 바로 학습시켜주면 되냐? 아니다. KoBERT에 입력되기 위해서는 데이터가 적절히 전처리(토큰화, 정수 인코딩, 패딩)가 되어야 한다. 데이터 전처리의 경우 이미 예시코드에 잘 정리되어 있어서 이를 똑같이 불러와 전처리해주기로 했다. 해당 개념은 간단하게 설명하고 넘어가겠다.
- 토큰화 : 주어진 말뭉치에서 토큰(token)이라 불리는 단위로 나누는 작업이다. 토큰의 단위는 상황에 따라서 다르게 적용될 수 있다.
- 정수 인코딩 : 텍스트에 등장하는 단어의 빈도수에 따라 정렬하여, 자주 등장하는 단어에 정수를 부여하여 컴퓨터가 처리하기 쉽게 만들어 주는 것이다.
- 패딩 : 컴퓨터는 길이가 동일한 문서는 하나의 행렬로 보고 한꺼번에 묶어서 처리할 수 있기에, 병렬 연산을 위해서 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업이다.
먼저, BERTSentenceTransform 클래스를 정의해준다. 그리고 전처리와 모델 분석에 필요한 parameters들을 선언해준다.
class BERTDataset(Dataset):
def __init__(self, dataset, sent_idx, label_idx, bert_tokenizer, max_len,
pad, pair):
transform = nlp.data.BERTSentenceTransform(
bert_tokenizer, max_seq_length=max_len, pad=pad, pair=pair)
self.sentences = [transform([i[sent_idx]]) for i in dataset]
self.labels = [np.int32(i[label_idx]) for i in dataset]
def __getitem__(self, i):
return (self.sentences[i] + (self.labels[i], ))
def __len__(self):
return (len(self.labels))## Setting parameters
max_len = 64
batch_size = 64
warmup_ratio = 0.1
num_epochs = 5
max_grad_norm = 1
log_interval = 200
learning_rate = 5e-5위에서 정의된 BERTSPTokenizer를 바탕으로 data_train과 data_test 를 전처리하고 처리된 결과를 각각 train_dataloader , test_dataloader 에 저장해준다.
#tokenize
tokenizer = get_tokenizer()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False)
data_train = BERTDataset(dataset_train, 0, 1, tok, max_len, True, False)
data_test = BERTDataset(dataset_test, 0, 1, tok, max_len, True, False)
train_dataloader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, num_workers=5)
test_dataloader = torch.utils.data.DataLoader(data_test, batch_size=batch_size, num_workers=5)이제 데이터에 대한 모든 준비가 끝났다. 학습하러 가보자!
5. KoBERT 학습모델
해당 모델은 앞서 말했지만 SKTBrain에서 제공된 네이버 영화평 이중분류 코드에서 받아올 수 있는 코드이다. 해당 코드에서는 영화평을 분석하여 긍정/부정의 두가지 클래스로 분류한다. 하지만 나는 AIHUB에서 제공하는 한국어 대화 문장을 바탕으로 분석을 진행할 예정으로, 클래스 수를 7개로 변경하고 그대로 사용하였다.
class BERTClassifier(nn.Module):
def __init__(self,
bert,
hidden_size = 768,
num_classes=7,
dr_rate=None,
params=None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size , num_classes)
if dr_rate:
self.dropout = nn.Dropout(p=dr_rate)
def gen_attention_mask(self, token_ids, valid_length):
attention_mask = torch.zeros_like(token_ids)
for i, v in enumerate(valid_length):
attention_mask[i][:v] = 1
return attention_mask.float()
def forward(self, token_ids, valid_length, segment_ids):
attention_mask = self.gen_attention_mask(token_ids, valid_length)
_, pooler = self.bert(input_ids = token_ids, token_type_ids = segment_ids.long(), attention_mask = attention_mask.float().to(token_ids.device))
if self.dr_rate:
out = self.dropout(pooler)
return self.classifier(out)#정의한 모델 불러오기
model = BERTClassifier(bertmodel, dr_rate=0.5).to(device)
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
loss_fn = nn.CrossEntropyLoss()
t_total = len(train_dataloader) * num_epochs
warmup_step = int(t_total * warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_step, num_training_steps=t_total)
def calc_accuracy(X,Y):
max_vals, max_indices = torch.max(X, 1)
train_acc = (max_indices == Y).sum().data.cpu().numpy()/max_indices.size()[0]
return train_acc
train_dataloader6. 모델 학습시키기
위에서 준비한 학습 모델을 바탕으로 데이터를 학습시켜보자.
for e in range(num_epochs):
train_acc = 0.0
test_acc = 0.0
model.train()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(train_dataloader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
if batch_id % log_interval == 0:
print("epoch {} batch id {} loss {} train acc {}".format(e+1, batch_id+1, loss.data.cpu().numpy(), train_acc / (batch_id+1)))
print("epoch {} train acc {}".format(e+1, train_acc / (batch_id+1)))
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_acc += calc_accuracy(out, label)
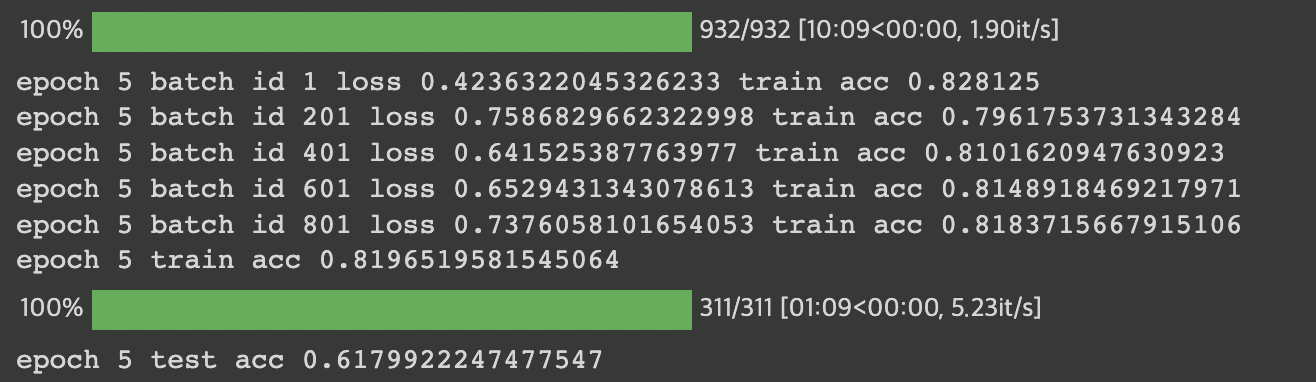
print("epoch {} test acc {}".format(e+1, test_acc / (batch_id+1)))epoch=5으로 학습된 결과를 보면 train데이터와 test데이터에 대해서 각각의 정확도가 나왔다. 0.82와 0.62면 높은 수준의 정확도가 아니라 아쉽지만, 아마도 서로 다른 두개의 데이터를 병합하는 과정에서 적절히 분류되지 못한 데이터가 있었을 것이라고 유추된다. 앞으로 정확도를 더 높여나가는 데이터셋을 구축해야겠다는 생각이 들었다.
7. 결과물 테스트
자, 이제 우리가 완성한 모델이 제대로 되어있는지 확인하기 위한 테스트 단계이다.
우리가 원하는 문장을 입력하면 KoBERT 입력 형태로 변환되어 모델에 들어가고, 그에 따른 감성을 출력해주는 함수이다. 이를 이용하여 원하는 결과가 잘 나오는지 확인해보자.
#토큰화
tokenizer = get_tokenizer()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False)
def predict(predict_sentence):
data = [predict_sentence, '0']
dataset_another = [data]
another_test = BERTDataset(dataset_another, 0, 1, tok, max_len, True, False)
test_dataloader = torch.utils.data.DataLoader(another_test, batch_size=batch_size, num_workers=5)
model1.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(test_dataloader):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model1(token_ids, valid_length, segment_ids)
test_eval=[]
for i in out:
logits=i
logits = logits.detach().cpu().numpy()
if np.argmax(logits) == 0:
test_eval.append("공포가")
elif np.argmax(logits) == 1:
test_eval.append("놀람이")
elif np.argmax(logits) == 2:
test_eval.append("분노가")
elif np.argmax(logits) == 3:
test_eval.append("슬픔이")
elif np.argmax(logits) == 4:
test_eval.append("중립이")
elif np.argmax(logits) == 5:
test_eval.append("행복이")
elif np.argmax(logits) == 6:
test_eval.append("혐오가")
print(test_eval[0] + " 느껴집니다.")#질문 무한반복하기! 0 입력시 종료
end = 1
while end == 1 :
sentence = input("하고싶은 말을 입력해주세요 : ")
if sentence == 0 :
break
predict(sentence)
print("\n")해당 모델을 바탕으로 일반 대화의 데이터를 테스트한 결과값은 포스트 초반부에 이미 보여주었다. 17개의 문장 중 2개의 문장이 예상된 결과값과 다르긴 했지만 그럼에도 불구하고 예상값과 유사한 감정선을 예측해주는 것을 확인할 수 있다. 일반 문장에 대해서는 정확도가 꽤나 높은 모습을 보여준다.
이를 바탕으로 나는 초기 프로젝트의 목적에 부합하도록 실제 소설 장면에서 가져온 데이터를 입력해보기로 했다. 내가 모델을 학습한 데이터셋은 현대인들의 일상 대화 데이터셋이기 때문에 사실 장르소설에 적용하기에는 해당 장르가 현대사회를 배경을 삼는 소설이 아니라면 사실상 사용하는 어휘, 감정 등이 달라 어려움이 있다. 그래서 일단 최대한 감정이 잘 드러나는 장면을 찾아 분석해보기로 했다. 추후 소설문장 데이터셋이 잘 구축한다면 전이학습을 통해 프로젝트 목적에 맞는 모델을 더 발전시킬 수 있을 것이다.
- 슬픈 장면
이가 부러질 듯 맞물린다. (슬픔)
움켜쥔 주먹에 얼마나 힘이 들어갔는지, 손톱이 손바닥을 파고들어 검붉은 피가 흘러나온다. (분노)
경련하는 몸을 주체할 수가 없다. (공포)
머리를 새하얗게 만들어 버릴 것 같은 분노가 그를 덮쳤다. (분노)
모두가 죽었다. (슬픔)
함께 이 산을 오르며, 강호를 수호하고 화산의 이름을 천하에 떨치리라 맹세했던 사형제들은 모두 돌아오지 못할 곳으로 떠났다. (분노)
그들을 따라 이 산에 오른 사질들도 모두. (놀람)
청명이 이를 악물었다. (혐오)
고귀한 희생이다. 더없이 위대하고 협의(俠義) 넘치는 죽음이다. (행복)
하지만 이 죽음을 누가 감히 칭송할 수 있다는 말인가? (분노)첫번째로 저자가 아주 좋아하는 화산귀환의 프롤로그 페이지를 분석해보았다. 해당 장면은 모든 것을 잃은 주인공의 처절하고 비통한 감정이 잘 드러나는 장면이다.
모델에 직접 한 문장씩 입력해본 결과, 슬픔, 분노 등 부정적인 감정들이 전반적으로 잘 분석되었다. 장르소설이긴 하지만 분위기 자체가 직관적으로 드러나기 때문에 이러한 정확도를 보여주었다고 사료된다.
- 기쁜 장면
기적과도 같은 일이다.(공포)
일주일 뒤면 거리에 나앉게 생겼던 화산이 아니던가.(놀람) 하지만 이 증서들과 장부만 있다면 화산의 전각들을 지킬 수 있음은 물론이고 저 화음의 사업장들도 모조리 되찾을 수 있다.(중립)
그야말로 대박이 터진 것이다.(놀람)
재경각주 현영(玄永)이 껄껄 웃었다.(중립)
"그럴 리는 없겠지만, 설사 이 모든 것들이 가품이라고 해도 당장의 위기는 넘겼습니다.(행복) 궤짝 안에 들어 있던 재물이 못해도 십만 냥은 훌쩍 넘습니다.(놀람) 저들이 갚으라 요구하는 돈을 모조리 갚고도 남습니다."(슬픔)
"다행이야. 정말 다행이야."(행복)
"이 돈만 있다면 화산의 재정 문제를 단숨에 해결할 수 있습니다.(행복) 그리고 저들의 사업체를 몰수할 수 있다면 앞으로도 돈 걱정은 하지 않아도 될 겁니다."(중립)
들어도 들어도 좋은 소리만 흘러나온다.(행복) 현종의 귀에는 그 목소리가 절세가인의 옥음처럼 들렸다.(슬픔)
"그뿐만이 아닙니다."(공포)
무각주(武閣主) 현상(玄商)이 부드럽게 웃으며 말했다.(중립)
"칠매검(七梅劍) 역시도 진본인 모양입니다.(행복) 조금 더 연구를 해 보아야겠지만, 지금까지 확인한 바로는 특별한 오류가 없습니다.(중립) 그리고 화산 무학 특유의 쾌(快)와 환(換), 그리고 호연지기가 있습니다."(행복)같은 소설의 다른 장면을 가져와봤다. 해당 장면의 경우 주인공 덕분에 위기에 처한 화산이 전화위복을 하는 즐거운 장면이다. 하지만, 무협 소설의 특성상 현대에 쓰이지 않는 어휘도 많고, 상황 설명 파트를 모델이 잘 이해하지 못해 분석이 상대적으로 부정확한 것을 볼 수 있다.
앞서 분석한 장면에 비해 정확도가 많이 떨어지는 것에 아쉬움이 느껴져 다른 장면을 찾아와 다시 한번 분석해보기로 했다.
청명이 눈을 크게 떴다. 호흡이 가빠지고 심장이 두방망이질한다.(중립) 피가 얼굴로 몰려 금방이라도 터질 것 같다.(분노)
하지만 아무려면 어떤가?(공포)
"으헤헤헤헤헤!"(놀람)
좋아 죽겠는데!(행복)
그의 눈앞에 행복이 있다.(행복)
한쪽에 가지런히, 소담스레 쌓여 있는 금괴들.(놀람)
그리고 다른 쪽에 각을 맞추어 정리된 각종 보검들.(행복)
그리고⋯⋯.(공포)
"이, 이거 묘안석인가?"(놀람)
정체를 알 수 없는 보석들과 비급들까지!(놀람)
"으헤헤헤헤헤헤헤!"(놀람)
자꾸만 웃음이 터져 나온다.(행복) 자제하려고 해도 바보 같은 웃음이 걷잡을 수 없이 흘러나왔다.(슬픔)
"으헤헤헤헤헤헤헤헤헤!"(놀람)
그래. 웃자! 웃어!(행복)
"나는 이제 부자다아아아아아아아아아!"(행복)해당 장면 전, 조금 더 직관적으로 행복함이 드러나는 장면을 가져왔다.
문장별로 분석하다보니 맥락을 알 수 없어 부정적인 감정이 출력되기도 했지만, 전반적으로 놀람과 행복이 잘 드러나도록 분석되어 보인다. 하지만 역시 보완이 필요하다는 생각이 든다.
Result
이번 포스팅에는 KoBERT를 이용해 다중감성분석을 진행해보았다. 일상 대화의 분석은 비교적 잘 수행되었지만, 아무래도 우리의 최종 목표는 소설 텍스트의 맥락 분석이다보니 추가적인 공부가 더 필요할 것 같다는 생각이 든다.
일단 이에 대해서 현재 생각하고 있는 방법은 소설의 한 문단 등을 전체적으로 가져와서 해당 문단 자체에 주로 포함되어 있는 감성을 퍼센테이지로 분석해보는게 가장 효과적일 것이라는 생각이 들었다. 하지만 문단이 잘 구분되어 있지 않은 웹소설의 경우 이를 적용하기 애매하기도 했고, 노래와 같이 틀어주니 노래의 길이에 맞춰서 조화롭게 변경될 수 있도록 많은 방법이 필요할 것 같다.
또한, AIHUB에서 제공하는 데이터가 아무래도 일상 대화 데이터다보니 소설의 문어체와 잘 맞지 않아 분석의 정확도가 떨어진다는 생각이 들었다. 이를 보완할 수 있는 방법도 열심히 찾아봐야겠다.
짧은 회고를 끝으로 포스팅을 마무리하겠다.

3개의 댓글

올려주신글 너무 감사하게 잘 읽었습니다.
혹시 지금 코랩으로 실행보니깐 import gounnlp 부터 안되고 있는데 혹시 방법을 알고 계실까요?
4월말 까지는 너무 잘사용했는데 갑자기 코랩이 업데이트(python 10.0으로 업데이트)되더니 문제가 발생합니다.
python version: 3.6, 3.7, 3.8, 3.9 까지 진행 결과 오류가 발생합니다.1

잘 읽었어요~