[kotlin] 안드로이드 스튜디오에 CLOVA sentiment 구현하기
목차
- 들어가기에 앞서
- 네이버 클라우드 AI 서비스, CLOVA sentiment
- CLOVA sentiment 실제 구현
2-1. 클로바 API 등록하기.
2-2. API 명세서 확인
2-3. CODE- 실행 결과
- 마치며..
0. 들어가기에 앞서.
내가 현재 진행하고 있는 프로젝트는 다음과 같다.
- Screen OCR을 통해 소설 텍스트 데이터 수집 및 전처리
- 감성분석 모델을 이용해 텍스트를 다중감성으로 분류
- 문단별로 감성 퍼센트 데이터를 분석하여 주된 감성 파악
- 파악된 감성과 매치되는 음악 데이터를 연결하여 유저에게 제공
- 소설을 읽으며 감성이 달라질때마다 적절하게 음악을 자동으로 변경
나는 해당 프로젝트에서 분석의 핵심이 되는 자연어 처리 파트를 맡아 진행하고 있다. 이전 포스트에서는 KoBERT를 이용해, 한국어 대화 문장을 7가지의 감정(기쁨, 슬픔, 놀람, 분노, 공포, 혐오, 중립)으로 분류하는 모델을 학습시켰다.
하지만, 2021년 11월 12일 경 해당 모델 다운로드 서비스가 작동을 중지하면서 널리 알려져 있는 예시 코드들이 작동하지 않게 되었다. 이를 알지 못한 상태로 코랩 환경에서 구현까지 마쳤던 나는 서버 연결에서 이 사실을 알았다… (그 과정에서 삽질을 얼마나 했는지 모르겠다…) 이를 해결하기 위해 모델 다운로드 방식을 Hugging Face를 통한 모델 다운로드로 전환해야 하게 되었다. 이번 포스팅에서 이 부분을 소개할까 고민을 하다가, KoBERT와 내용이 많이 겹쳐서 트러블 슈팅 과정에서 경험했던 네이버 클라우드 서비스에 대해 A부터 Z까지 소개하려 한다.
1. 네이버 클라우드 AI 서비스, CLOVA sentiment
팬데믹 속에서 다양한 IT 기술이 주목받고 있다. 그 중 AI는 팬데믹 이후 우리의 삶을 가장 빠르게 변화시키는 기술이며, 앞으로 그 발전 속도는 더욱 더 가속화 되는 상황이다. 현재 진행 중인 한국판 뉴딜 중 AI는 큰 역할을 차지하고 있다. 네이버 클라우드는 NIPA의 주관 사업자로서 AI에 특화된 클라우드 사업을 추진하고 있으며, CLOVA를 통해 다양한 고객 Needs를 반영한 AI 서비스를 제공하고 있었다.
- 편리하게 사용하는 인공지능 서비스 고객이 AI 서비스를 손쉽게 구축하고 안정적으로 운영할 수 있도록 CLOVA, Papago 등 최신 기술을 기반으로한 네이버 클라우드 플랫폼의 다양한 인공지능 서비스를 API 형태로 제공합니다.
- 네이버의 풍부한 데이터를 활용한 학습 고객의 AI 서비스와 맞닿아 있는 네이버 클라우드 플랫폼의 AI Services 품질은 여러 분야에서 수집되는 네이버의 풍부한 데이터를 기반으로 스스로 학습함으로써 점점 더 향상됩니다.
- 높은 성능을 가진 컴퓨팅 파워 인공지능 서비스가 방대한 양의 데이터를 빠르고 안정적으로 처리할 수 있도록 고사양의 IT 자원을 사용하여 운영하고 있습니다. 서비스를 연속으로 제공할 수 있도록 이중화 구성은 물론 365일 24시간 모니터링도 함께 수행합니다.
이번 포스팅을 준비하면서 네이버 클라우드에 정말 다양한 서비스가 있고, 특히 AI분야에서 사용해보고 싶은 기술들이 정말 많다는 것을 다시 한번 확인할 수 있었다.
특히 NLP 분야에서는 한국어 자료가 영어보다는 당연히 부족하고, 영어보다 더 복잡한 문장 구조를 가지고 있어 난이도가 높다. 네이버와 같이 한국을 대표하고 보유한 데이터도 방대한 플랫폼에서 해당 연구를 진행하니 확실히 모델 자체의 성능이나 속도가 다르다는 생각이 들었다.
CLOVA sentiment
그 중 CLOVA sentiment는 글에 담긴 감정을 분석하고 감정이 표현된 부분을 추출해 주는 서비스로, 한국어에 최적화된 감정 분석 기술 서비스이다.

한국어에 최적화된 텍스트 분석:
네이버의 빅데이터와 형태소 분석기를 활용하여 한국어에 최적화된 방식의 사전 학습(pre-training)을 수행한다.
빠른 처리 속도:
인공 지능 모델 사이즈를 줄인 Shallow BERT를 적용하여, 기존 BERT(Bidirectional Encoder Representations from Transformers) 모델보다 4배 이상 빠르게 처리할 수 있다.
텍스트 내 주요 감정 표현 추출:
텍스트에서 느껴지는 분위기를 긍정, 부정, 중립으로 구분하고, 감정 판단의 핵심이 되는 주요 감정을 추출할 수 있다.
다양한 분야에 적용:
블로그, 댓글, SNS 등 텍스트 형태로 만들어진 콘텐츠라면 어디에든 적용할 수 있다.
2. CLOVA sentiment 실제 구현
본격적으로 CLOVA sentiment를 구현해보자.
CLOVA Sentiment는 비로그인 오픈 API이다.
감정 분석이 필요한 문서를 RESTful API 방식으로 전달하면 문장 단위로 나누어 감정 분석을 수행한다. 감정 분석을 요청할 때 POST 방식을 사용하며 HTTP Header에 애플리케이션을 등록할 때 발급받은 Client ID와 Client Secret 값을 전송하여 인증한다.
이후, JSON 형태로 감정 분석된 결과를 전달(긍정/부정/중립)받아 사용자가 원하는대로 사용하면 되는 간단한 구조를 가지고 있다. 직접 따라해보면서 구현해보자!
1. 클로바 API 등록하기.
클로바 API가 제공하는 가이드라인에 따라 API를 등록해보자.
[이렇게 사용하세요!] 텍스트 감정 분석 서비스 구현하기 (CLOVA Sentiment 활용기)
먼저, 네이버 클라우드에 들어가서 AI·NAVER API > AI·NAVER API > Application에서 애플리케이션을 등록해야 한다.
- ncloud.com 접속/로그인 후 우측 상단 Console(콘솔) 접속
- Products & Services > AI · NAVER API 클릭
좌측 Application 등록을 통해서 진행하자.
해당 화면에서, 우리가 구현하고자 하는 앱의 이름을 작성해주고, Service에 내가 사용하고자 하는 CLOVA sentiment를 선택하자.
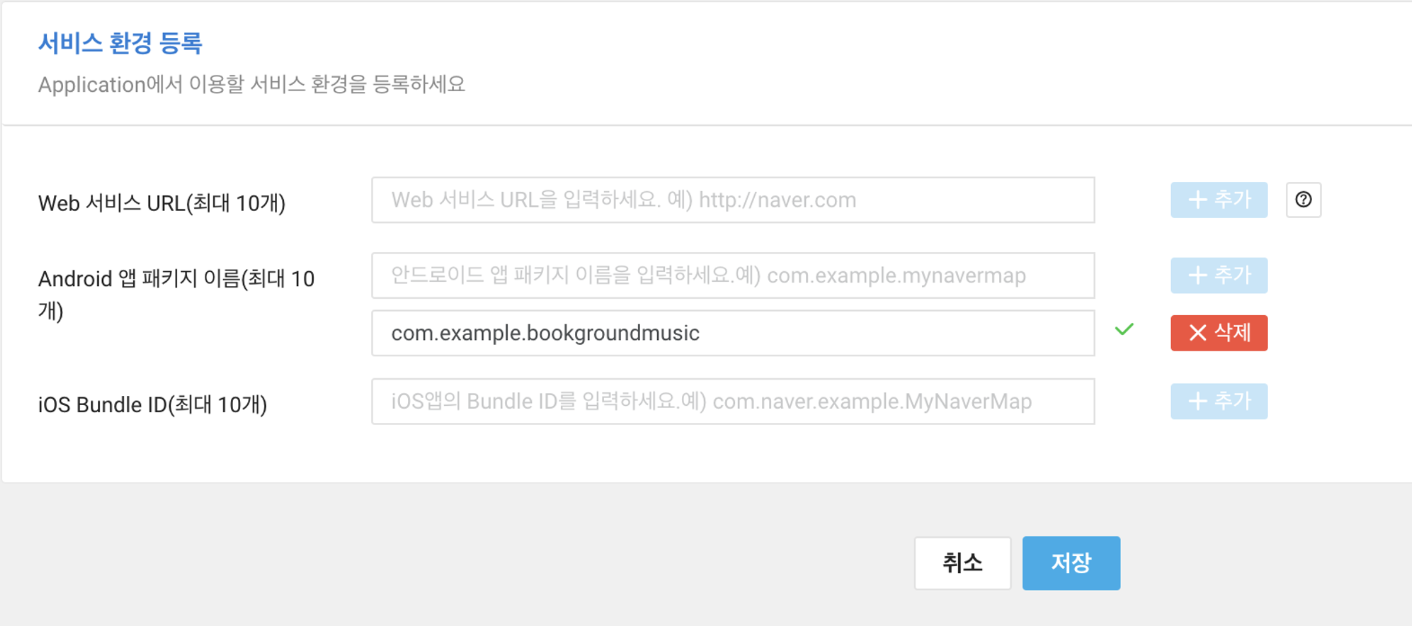
이후, 서비스 환경을 등록해야 한다. 사용할 패키지 이름을 추가해주고 저장하면 간단하게 애플리케이션이 등록된다.

등록 후에는 이렇게 본인이 사용하고 있는 서비스, 사용량 등을 한눈에 확인할 수 있다. 여기에서 가장 중요한 인증정보를 확인해보자.
해당 인증정보를 보면 Client ID와 Client Secret이 나온다. 해당 인증 정보를 헤더로 달아 POST 해야하기 때문에 반드시 기억해두자!
여기까지 진행하면 서비스를 진행할 준비가 모두 끝났다. 본격적으로 API를 사용해보자.
2. API 명세서 확인
네이버 클라우드에서 제공한 api 명세서를 바탕으로 코드를 짜보자.
먼저 요청에 필요한 내용과 응답 양식은 다음과 같다.
요청
HTTP POST
**https://naveropenapi.apigw.ntruss.com/sentiment-analysis/v1/analyze**요청 헤더
| 헤더명 | 설명 |
|---|---|
| X-NCP-APIGW-API-KEY-ID | 앱 등록 시 발급받은 Client IDX-NCP-APIGW-API-KEY-ID:{Client ID} |
| X-NCP-APIGW-API-KEY | 앱 등록 시 발급 받은 Client SecretX-NCP-APIGW-API-KEY:{Client Secret} |
| Content-Type | 바이너리 전송 형식Content-Type: application/json |
요청 바디
| 필드명 | 필수 여부 | 타입 | 설명 |
|---|---|---|---|
| content | Yes | String | 감정분석 Text |
| config.negativeClassification | No | Boolean | 부정구문 분석 옵션 |
응답
응답 바디
| 필드 이름 | 데이터 타입 | 설명 |
|---|---|---|
| document | Object | 전체 문장 관련 object |
| document.sentiment | String | 전체 문장에 대한 감정 |
| document.confidence | Object | 전체 문장에 대한 감정 confidence |
| document.confidence.neutral | Float | 중립 confidence (%) |
| document.confidence.positive | Float | 긍정 confidence (%) |
| document.confidence.negative | Float | 부정 confidence (%) |
| sentences | List of Object | 분류 문장 관련 list object |
| sentences.content | String | 분류 문장 |
| sentences.offset | Int | document.content 에서 문장 시작 위치 |
| sentences.length | Int | 분류 문장 글자 수 |
| sentences.sentiment | String | 분류 문장 감정 |
| sentences.confidence | Object | 분류 문장에 대한 감정 confidence |
| sentences.confidence.neutral | Float | 중립 confidence (%) |
| sentences.confidence.positive | Float | 긍정 confidence (%) |
| sentences.confidence.negative | Float | 부정 confidence (%) |
| sentences.highlights | List of Object | sentences.content 에서 감정분석 구간 |
| sentences.highlights.offset | Int | 주요 감정 구간 시작 위치 |
| sentences.highlights.length | Int | 주요 감정 구간 글자 수 |
| sentences.negativeSentiment.sentiment | String | 부정 감정일 경우, 세부 감정 |
| sentences.negativeSentiment.confidence | Float | 부정 감정일 경우, 세부 감정에 대한 confidence |
혹시 API가 어떻게 동작하지 모르는 사람을 위해 간단하게 설명하면,
api 서버 주소에 본인을 인증하기 위한 아이디와 시크릿 키, 그리고 감성분석을 원하는 텍스트를 Content-Type에 담아서 POST요청을 보낸다.
그에 대한 응답으로 위의 리스트에 구현된 필드의 데이터를 받아오는 구조이다. 해당 필드에는 텍스트 전체의 감성, 그리고 텍스트 안의 세부 문장에 대한 감성을 긍정,부정,중립의 세가지 비중으로 내용을 받아오는 구조이다.
직접 코드로 구현해보자.
3. CODE
먼저, 응답 명세서에 맞게 Data Class를 만들어준다. 참고로, 파일 위치는 MainActivity 파일이 존재하는 곳에 만들어주면 된다.
나의 경우, 해당 경로에 DataClass라는 폴더를 만들어 그 안에 모두 정리해두었다.
package com.example.bookgroundmusic.DataClass
data class SentimentAnalysisResponse(
val document: Document,
val sentences: List<Sentence>
)
data class Document(
val sentiment: String,
val confidence: Confidence
)
data class Confidence(
val neutral: Float,
val positive: Float,
val negative: Float
)
data class Sentence(
val content: String,
val offset: Int,
val length: Int,
val sentiment: String,
val confidence: Confidence,
val highlights: List<Highlight>
)
data class Highlight(
val offset: Int,
val length: Int
)이후, MainActivity에 감성분석을 진행하는 함수를 정의해준다.
//Clova sentiment 예시 코드
private fun callSentimentAnalysisAPI(text: String) : String {
val url = "https://naveropenapi.apigw.ntruss.com/sentiment-analysis/v1/analyze"
val client = OkHttpClient()
val jsonBody = JSONObject()
.put("content", text)
val requestBody = RequestBody.create("application/json".toMediaTypeOrNull(), jsonBody.toString())
val request = Request.Builder()
.url(url)
.addHeader("X-NCP-APIGW-API-KEY-ID", "**본인의 Client Key**")
.addHeader("X-NCP-APIGW-API-KEY", "**본인의 Client Secret**")
.post(requestBody)
.build()
client.newCall(request).enqueue(object : Callback {
override fun onFailure(call: Call, e: IOException) {
// API 호출 실패 처리
e.printStackTrace()
}
override fun onResponse(call: Call, response: Response) {
// API 호출 성공 처리
val jsonResult = response.body?.string()
val responseObject = gson.fromJson(jsonResult, SentimentAnalysisResponse::class.java)
Log.d("API Response", jsonResult ?: "")
if (responseObject.document == null){
Log.d("ERROR","분석이 제대로 완료되지 않았습니다.")
}
if (responseObject.document != null) {
// 전체 문장 감정 정보 로그 출력
Log.d("MainActivity", "전체 문장 감정: ${responseObject.document.sentiment}")
Log.d("MainActivity", "중립 감정 확률: ${responseObject.document.confidence.neutral}")
Log.d("MainActivity", "긍정 감정 확률: ${responseObject.document.confidence.positive}")
Log.d("MainActivity", "부정 감정 확률: ${responseObject.document.confidence.negative}")
sentiment = responseObject.document.sentiment
}
if (responseObject.sentences != null) {
for (sentence in responseObject.sentences) {
if (sentence.sentiment != null) {
// 분류 문장 감정 정보 로그 출력
Log.d("MainActivity", "분류 문장: ${sentence.content}")
Log.d("MainActivity", "문장 감정: ${sentence.sentiment}")
Log.d("MainActivity", "중립 감정 확률: ${sentence.confidence.neutral}")
Log.d("MainActivity", "긍정 감정 확률: ${sentence.confidence.positive}")
Log.d("MainActivity", "부정 감정 확률: ${sentence.confidence.negative}")
}
}
}
}
})
return sentiment
}함수의 전문은 다음과 같다. 혹시 해당 포스트를 보고 따라해보고 싶으면 Client ID, Secret만 변경하면 그대로 사용할 수 있을 것이다.
import okhttp3.*
import org.json.JSONObject참고로 함수 사용 전 먼저, OkHttpClient 및 관련 클래스를 사용하기 위한 okhttp3 라이브러리와 JSON 객체를 사용하기 위한 org.json 패키지를 가져와야 한다는 점 잊지 말자!
먼저 해당 호출 함수 구조를 자세히 보자.
private fun callSentimentAnalysisAPI(text: String) : String {
// API 엔드포인트 URL
val url = "https://naveropenapi.apigw.ntruss.com/sentiment-analysis/v1/analyze"
// OkHttpClient 생성
val client = OkHttpClient()
// 요청할 JSON 바디 생성
val jsonBody = JSONObject().put("content", text)
// RequestBody 생성
val requestBody = RequestBody.create("application/json".toMediaTypeOrNull(), jsonBody.toString())
// API 호출을 위한 Request 객체 생성
val request = Request.Builder()
.url(url)
.addHeader("X-NCP-APIGW-API-KEY-ID", "본인의 Client Key")
.addHeader("X-NCP-APIGW-API-KEY", "본인의 Client Secret")
.post(requestBody)
.build()내가 만든 callSentimentAnalysisAPI 함수는 String 타입의 text를 input으로 받는다. 즉, 감성분석을 하고 싶은 텍스트를 input으로 넣기만 하면 작동되는 구조다.
먼저 client, jsonBody, requestBody를 생성한다. 요청 바디에는 input을 넣어 생성하는걸 잊지 말자. 이후, API 명세서에 적힌대로 POST 요청을 위한 url, 개인 클라이언트 키와 시크릿을 RequestBody에 넣어 post요청을 하는 방식이다.
요청이 제대로 들어갔다면 이제 응답을 받을 수 있을 것이다.
client.newCall(request).enqueue(object : Callback {
override fun onFailure(call: Call, e: IOException) {
// API 호출 실패 처리
e.printStackTrace()
}
override fun onResponse(call: Call, response: Response) {
// API 호출 성공 처리
val jsonResult = response.body?.string()
val responseObject = gson.fromJson(jsonResult, SentimentAnalysisResponse::class.java)
Log.d("API Response", jsonResult ?: "")
if (responseObject.document == null){
Log.d("ERROR","분석이 제대로 완료되지 않았습니다.")
}
if (responseObject.document != null) {
// 전체 문장 감정 정보 로그 출력
Log.d("MainActivity", "전체 문장 감정: ${responseObject.document.sentiment}")
Log.d("MainActivity", "중립 감정 확률: ${responseObject.document.confidence.neutral}")
Log.d("MainActivity", "긍정 감정 확률: ${responseObject.document.confidence.positive}")
Log.d("MainActivity", "부정 감정 확률: ${responseObject.document.confidence.negative}")
sentiment = responseObject.document.sentiment
}
if (responseObject.sentences != null) {
for (sentence in responseObject.sentences) {
if (sentence.sentiment != null) {
// 분류 문장 감정 정보 로그 출력
Log.d("MainActivity", "분류 문장: ${sentence.content}")
Log.d("MainActivity", "문장 감정: ${sentence.sentiment}")
Log.d("MainActivity", "중립 감정 확률: ${sentence.confidence.neutral}")
Log.d("MainActivity", "긍정 감정 확률: ${sentence.confidence.positive}")
Log.d("MainActivity", "부정 감정 확률: ${sentence.confidence.negative}")
}
}
}
}
})
return sentiment
}혹시 모를 에러를 대비하기 위해 onFailure 메서드를 사용하여 API 호출 실패 시 예외 처리 먼저 해주자.
먼저, 요청이 제대로 처리된 경우response.body?.string()을 사용하여 API 응답의 본문을 문자열로 가져올 수 있다. 그리고 gson.fromJson(jsonResult, SentimentAnalysisResponse::class.java)를 사용하여 JSON 응답을 SentimentAnalysisResponse 객체로 변환한다.
분석이 제대로 되었는지 확인하기 위해 로그를 출력해보자.
if (responseObject.document != null) {
// 전체 문장 감정 정보 로그 출력
Log.d("MainActivity", "전체 문장 감정: ${responseObject.document.sentiment}")
Log.d("MainActivity", "중립 감정 확률: ${responseObject.document.confidence.neutral}")
Log.d("MainActivity", "긍정 감정 확률: ${responseObject.document.confidence.positive}")
Log.d("MainActivity", "부정 감정 확률: ${responseObject.document.confidence.negative}")
sentiment = responseObject.document.sentiment
}
if (responseObject.sentences != null) {
for (sentence in responseObject.sentences) {
if (sentence.sentiment != null) {
// 분류 문장 감정 정보 로그 출력
Log.d("MainActivity", "분류 문장: ${sentence.content}")
Log.d("MainActivity", "문장 감정: ${sentence.sentiment}")
Log.d("MainActivity", "중립 감정 확률: ${sentence.confidence.neutral}")
Log.d("MainActivity", "긍정 감정 확률: ${sentence.confidence.positive}")
Log.d("MainActivity", "부정 감정 확률: ${sentence.confidence.negative}")
}
}
}나는 전체 문장과 세부 문장을 확인할 수 있게끔 로그를 출력했다. 위에 상술된 API명세서에 따르면 해당 내용 뿐 아니라 주요 감정의 시작과 끝도 파악할 수 있는 내용들이 있으므로, 필요에 따라 추가해서 사용하면 될 것이다.
return sentiment이후, 최종적으로 감성분석된 결과를 sentiment변수에 담아 리턴하면 기본적인 감성분석 함수 구현이 끝난다.
해당 함수 내용을 사용하고 싶으면,
text = "분석을 원하는 텍스트를 String Type으로 담아서 준비하자."
sentiment = callSentimentAnalysisAPI(text)이런식으로 필요한 부분에 함수를 호출해서 결과값을 받아와 사용할 수 있다!
3. 실행 결과
이렇게 구현한 코드를 우리의 프로젝트에 넣어 실행해보자!
앞서 설명했던 것처럼, 우리는 실시간으로 전자책을 읽고 있는 사용자의 화면을 캡쳐한다. 이후, 캡쳐된 이미지를 비트맵으로 전환하여 OCR을 돌린다. 이를 바탕으로 받아온 텍스트를 감성분석 모델에 넣어 해당 캡쳐 페이지의 감성을 최종적으로 분석하는 것이다.
한번 부정적인 감성의 페이지를 캡쳐해서, 해당 api호출을 해보자. OCR특성상 화면 비율대로 텍스트를 가져오기 때문에, 밑의 내용처럼 문장이 줄바꿈이 되어 들어온다.
디어를 가지고 있었다는 것과 화함물 합성을 시도해보았
다는 정도는 사실일 것이다. 하지만 그 이상으로 그를 믿
을 수는 없었다. 그간 이루어졌던 수많은 서면 인터뷰의
태도로 보아, 이모셔널 솔리드의 대표는 자신의 아이디
어와 구현 과정을 과장되게 부풀려서 인터뷰하는 경향이
있었다. 내가 그의 말에 그다지 호응하지 않자, 그는 나
의 불신을 눈치 했는지 점점 피곤한 얼굴을 했다. 나는 이
런 한심한 질문들을 치우고 이제 묻고 싶은 것을 물어야
할 때임을 알았다.
"대표님. 저도 이 현상을 이해해보려고 노력했습니다.
이모셔널 솔리드의 제품들이 미친 듯이 팔려나가는 현상
을요. 어떤 점에서는 기분 전환을 위해 술을 마시거나 디
저트를 먹는 것과도 비슷하다는 점은 알겠습니다. 사람
들이 돈으로 행복을 사고 싶어 하는 건 이해가 가요. 그
게 실제로 효과적인 행복이 아니더라도 말이지요. 그런
데 제가 정말로 이해할 수 없었던 게 있어요."
그는 비딱하게 나를 보고 있었다. 나는 그가 답을 알고
있을지 궁금했다.
"대체 왜 어떤 사람들은 우울을 사는 접니까? 왜 '증
오'와 '분노' 같은 감정들이 팔려나가죠? 돈을 주고 그런
걸 사려는 사람이 있는 건가요? 애초에, 어떻게 그들이
부정적인 감정을 사고 싶어 할 것이라고 예상하셨습니
까?"처음에는 이 부분 때문에 각 문장별 분석이 제대로 될 수 있을지 걱정했으나, 로그를 보니 api에서 자체적으로 텍스트 전처리를 통해 문장부호를 기준으로 잘 분석되고 있음을 확인할 수 있다. 해당 텍스트를 input으로 넣어 받아온 로그를 확인해보면 다음과 같은 전체 감성을 확인할 수 있다.
전체 문장 감정: negative
중립 감정 확률: 17.36001
긍정 감정 확률: 0.023706794
부정 감정 확률: 82.61628- 구체적인 결과가 궁금하다면 여기에서 로그를 확인할 수 있다.
2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 전체 문장 감정: negative 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 중립 감정 확률: 17.36001 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 긍정 감정 확률: 0.023706794 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 부정 감정 확률: 82.61628 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 디어를 가지고 있었다는 것과 화함물 합성을 시도해보았 다는 정도는 사실일 것이다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 하지만 그 이상으로 그를 믿 을 수는 없었다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: negative 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 그간 이루어졌던 수많은 서면 인터뷰의 태도로 보아, 이모셔널 솔리드의 대표는 자신의 아이디 어와 구현 과정을 과장되게 부풀려서 인터뷰하는 경향이 있었다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 내가 그의 말에 그다지 호응하지 않자, 그는 나 의 불신을 눈치 했는지 점점 피곤한 얼굴을 했다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: negative 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 나는 이 런 한심한 질문들을 치우고 이제 묻고 싶은 것을 물어야 할 때임을 알았다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: negative 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: "대표님. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 저도 이 현상을 이해해보려고 노력했습니다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 이모셔널 솔리드의 제품들이 미친 듯이 팔려나가는 현상 을요. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 어떤 점에서는 기분 전환을 위해 술을 마시거나 디 저트를 먹는 것과도 비슷하다는 점은 알겠습니다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 사람 들이 돈으로 행복을 사고 싶어 하는 건 이해가 가요. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 그 게 실제로 효과적인 행복이 아니더라도 말이지요. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 그런 데 제가 정말로 이해할 수 없었던 게 있어요." 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: negative 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 그는 비딱하게 나를 보고 있었다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 나는 그가 답을 알고 있을지 궁금했다. 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: neutral 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: "대체 왜 어떤 사람들은 우울을 사는 접니까? 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: negative 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 왜 '증 오'와 '분노' 같은 감정들이 팔려나가죠? 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: negative 2023-05-10 20:43:02.553 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 돈을 주고 그런 걸 사려는 사람이 있는 건가요? 2023-05-10 20:43:02.554 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: negative 2023-05-10 20:43:02.554 8770-8962/com.example.bookgroundmusic D/MainActivity: 분류 문장: 애초에, 어떻게 그들이 부정적인 감정을 사고 싶어 할 것이라고 예상하셨습니 까?" 61% (201/330) 2023-05-10 20:43:02.554 8770-8962/com.example.bookgroundmusic D/MainActivity: 문장 감정: negative
몇번의 실험 결과를 해보니, 생각보다 더 정확하게 감성을 분석하는 것을 알 수 있다. 지금은 해당 api의 결과를 이전 포스팅에서 우리가 직접 설계하여 구현한 감성분석 모델과 비교해서 전반적인 분석 정확도를 확인하려는 목적으로 해당 api를 사용하고 있다.
4. 마치며..
이번 포스팅에는 네이버 클라우드의 AI Service를 이용해 감성분석을 진행해보았다. 이미 만들어져있는 API를 사용하는 만큼, 구체적인 세부 감성 분석이 불가능하고 긍정/부정/중립으로만 구분된다는 한계가 있었다. 그렇지만 사용이 정말 간편하고, 감성 분석된 결과가 생각보다 정확해 텍스트의 분위기를 제대로 파악하고 있다는 사실이 긍정적이었다. 앞으로도 감성분석, 더 나아가 더 많은 분야의 AI 서비스를 간단하게 api로 불러와서 사용한다면 상상을 현실로 구현하고자 하는 내 꿈에 한걸음 더 다다를 수 있을 것이라 생각된다.
짧은 회고를 끝으로 포스팅을 마무리하겠다.
