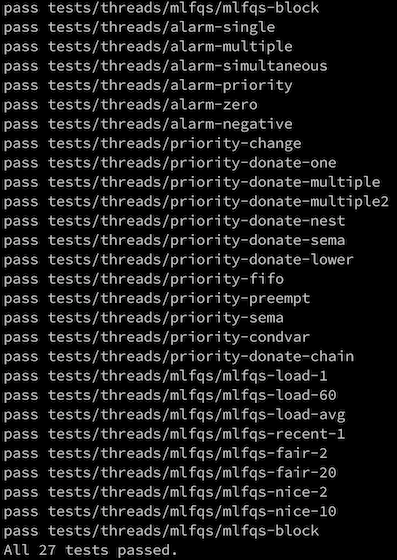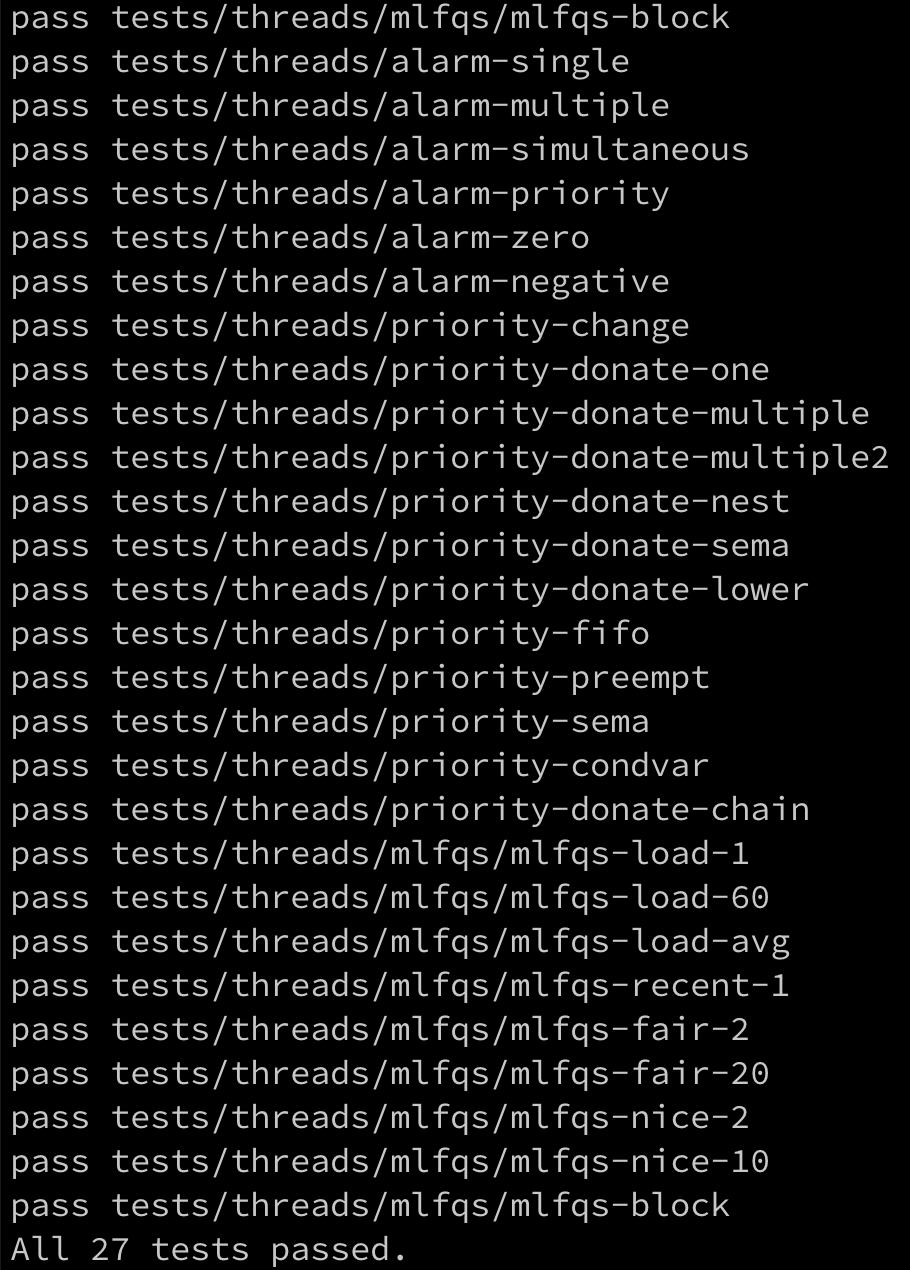
1. alarm
busy waiting 방식 -> 자는 thread가 thread_yield함수를 호출하며 CPU를 소모하며 대기하고 있다.
이를 개선하여 sleep list를 만들어 자는 thread를 추가하여 이 리스트에 포함된 thread는 CPU를 부여하지 않는다. ready_list에 존재하는 thread만 스케줄하기 때문이다.
하지만, 매 tick마다 thread_wakeup함수를 호출하는 것은 똑같다. 이 함수 에서 sleep_list내의 모든 thread의 wakeuptime과 현재 시간을 비교하기 때문에 여전히 개선되어야 하지만, 그럼에도 자는 thread에게 CPU를 주지 않는다는 것은 고무적이다.
2. priority scheduling
- Preemptive 구현
ready_list의 맨 앞의 thread를 스케줄하기 때문에 thread의 priority를 내림차순으로 sort하거나, 현재 thread의 priority에 맞게 저장할 곳을 찾아서 저장한다.
그리고 우선순위가 바뀌거나(thread_set_priority) 새로운 thread가 추가되었을 때 그 우선순위가 현재 running thread보다 높은 경우, 바로 양보하도록 하여 preemptive scheduling을 구현한다. - priority sort 구현
간단한 내부함수를 사용한다.
list_insert_ordered: 자신의 우선순위에 맞는 위치에 저장
list_sort: 리스트를 우선순위로 sort
저장을 ordered로 하거나, 마음대로 저장하고 sort하거나 선택할 수 있다.
그런데 스케줄링하기 전에list_sort함수를 호출하지 않으면 안되는 경우도 존재하기에 그냥 막 넣고 sort하는 것을 추천한다.
3. priority donation
struct lock {
struct thread *holder; /* Thread holding lock (for debugging). */
struct semaphore semaphore; /* Binary semaphore controlling access. */
};락을 잡고있는 스레드는 holder에 저장된다.
그렇다면, lock을 잡고자하는 여러 스레드들은 어디에 존재하게 되는걸까?
struct semaphore {
unsigned value; /* Current value. */
struct list waiters; /* List of waiting threads. */
};바로 여기 lock의 구조체 내부에 존재하는 semaphore 구조체를 공유하는 semaphore_elem의 필드인 semaphore의 waiters에 저장되게 된다.
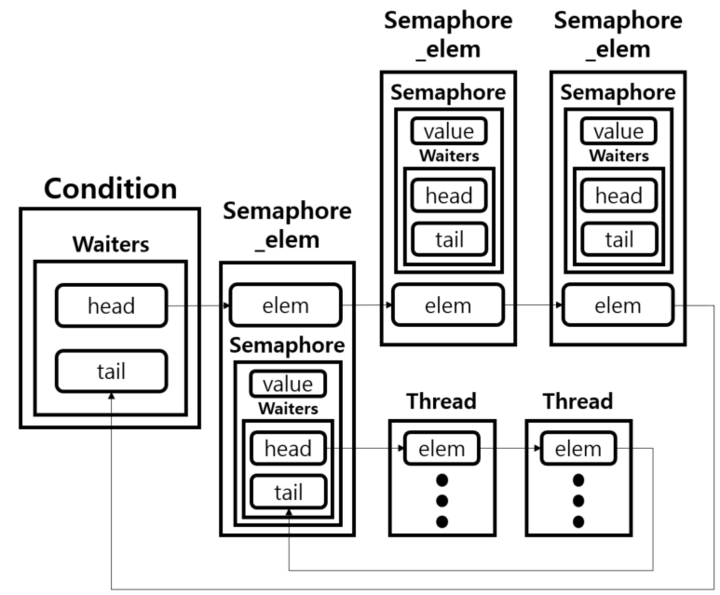
즉, semaphore_elem하나는 하나의 lock에 대응되고 같은 semaphore구조체를 공유한다.
한편, Thread의 elem의 prev와 next는 하나씩 존재한다. 즉, 기다리는 락은 무조건 1개여야 한다.
다시 말해, 락을 2개 이상 잡을 수는 있지만, 2개 이상 기다릴 수는 없다. 왜 그럴까?🤔
생각해보면 당연하다. 락을 요청하고 기다리게 되면, sema_down에서 잠자게 된다. 따라서, 또 다른 락을 잡기 위해 요청하는 코드를 실행할 수 없기 때문에 2개 이상을 잡을 수 없는 것이다.
4.4 BSD scheduler
MLFQ like scheduler without the queues
구현 시 주의사항
- fixed point arithmetic 매크로 만들기
priority,nice,ready_threads= integer
recent_cpu,load_avg= real number
Philosophy
-
priority
A. For all threads, priority is recalculated once in every fourth clock tick
B. The result is truncated to its nearset integer(rounding to nearest)priority = PRI_MAX - (recent_cpu / 4) - (nice * 2) -
recent_cpu
A. Increaserecent_cpuof the currently running process by 1 in every timer interrupt
B. Decayrecent_cpubydecayfactor in every second
C. Adjustrecent_cpubynicein every secondrecent_cpu = decay * recent_cpu + nice -
decaydecay = (2*load_average) / (2*load_average+1) -
load_average
A.load_avgis initially set to 0
B.ready_threads: the number of threads inready_listand threads in executing at the time of update(except idle thread)load_avg = (59/60)*load_avg + (1/60)*ready_threads
summary
-
every fourth tick, recompute the priority of all threads
=>timer_ticks() % 4 == 0 -
every clock tick, increase the running thread's
recent_cpuby one -
every second, update every thread's
recent_cpu
=>timer_ticks() % TIMER_FREQ == 0
QNA
- 위의 업데이트와 관련된 thread는 ready_list에 존재하는 thread에2 한정되는가? 아니면 존재하는 모든 thread인가?
=> 존재하는 모든 thread! - 1초마다 모든 thread의
recent_cpu를 갱신하는 것과 현재 running thread의recent_cpu에 1을 더하는 것 중 어느것을 먼저 계산해야 하는가?recent_cpu+= 1 먼저 -> 이후에 decay!- 1번을 마치고, 맨 마지막에 4틱마다 priority 갱신하는 함수 적용
load_avg는 언제 갱신하는가?
=>recent_cpu와 마찬가지로 1초마다!thread_get_load_avg와thread_get_recent_cpu함수는 각각의 값에 100을 곱한 값을 리턴한다. 그렇다면, 위 값을 이용하여recent_cpu를 갱신할 때 다시 100을 나눈 값을 이용하여 갱신해야 하는가?
=> No. 100을 곱한 값을 리턴하는 위 함수들은 순전히 test를 위한 용도이다. 따라서 갱신 및 저장에는 100을 곱하거나 나눌 필요가 없다.
TO DO LIST
timer_inturrupt함수에서 계속 인자들을 갱신하면서 priority를 갱신시켜줌.- 스케줄링 함수를 만들어서
schedule에서 호출 - fixe-point를 위한 매크로를 이용하여 계산하는 함수 추가
- multi queue 방식일 때 - multi queue의 역할에 해당하는 64개의 요소를 가진 배열을 추가하여 각 배열 요소에 해당하는 priority를 가진 thread를 연결하는 함수 추가
- single queue 방식일 때 -
schedule함수에서 priority로 sort된ready_list의 맨 앞을 스케줄함
구현 과정
1. 매크로 선언
/* macros for mlfqs
n : integer,
x,y : fixed point numbers*/
#define FC 16384 // 2^14, 고정소수점에서의 소수부를 나타내는 비트 수
#define convert_n_to_fp(n) ((n) * (FC)) // 정수 n을 고정소수점으로 변환
#define convert_x_to_int_round_to_zero(x) ((x) / (FC)) // 고정소수점 수 x를 정수로 변환 (반내림)
#define convert_x_to_int_round_to_nearest(x) ((x) >= 0 ? (((x) + ((FC) / 2)) / FC) : ((((x) - ((FC) / 2)) / FC))) // 고정소수점 수 x를 정수로 변환 (반올림)
#define add_x_and_y(x,y) ((x) + (y)) // 두 고정소수점 수 x와 y의 합
#define sub_y_from_x(x,y) ((x) - (y)) // 두 고정소수점 수 x와 y의 차 (x - y)
#define add_x_and_n(x,n) ((x)+((n) * (FC))) // 고정소수점 수 x와 정수 n의 합
#define sub_n_from_x(x,n) ((x) - ((n) * (FC))) // 고정소수점 수 x에서 정수 n을 뺀 값 (x - n)
#define mul_x_by_y(x,y) (((int64_t) (x)) * (y) / (FC)) // 두 고정소수점 수 x와 y의 곱
#define mul_x_by_n(x,n) ((x) * (n)) // 고정소수점 수 x와 정수 n의 곱
#define div_x_by_y(x,y) (((int64_t) (x)) * (FC) / (y)) // 고정소수점 수 x를 y로 나눈 값
#define div_x_by_n(x,n) ((x) / (n)) // 고정소수점 수 x를 정수 n으로 나눈 값
2. 인터럽트마다 갱신사항 추가
/* Timer interrupt handler. */
static void
timer_interrupt (struct intr_frame *args UNUSED) {
ticks++;
thread_tick ();
thread_wakeup(ticks);
/* check sleep list and the global tick.
find any threads to wake up,
move them to the ready list if necessary.
update the global tick.
*/
if(thread_mlfqs){
enum intr_level old_level = intr_disable (); // 업데이트 시 인터럽트 비활성화
thread_current()->recent_cpu += 16384; // for every tick
if( timer_ticks() % TIMER_FREQ == 0 ) { // 1초 마다
// update everty thread's recent_cpu
int decayed_load_avg = div_x_by_n(mul_x_by_n(LOAD_AVG,59),60);
READY_THREADS = list_size(&ready_list);
if(thread_current() != idle_thread) // idle이 아니라면 +1 , 맞으면 그냥 0
READY_THREADS += 1;
int fp_ready_thread = convert_n_to_fp(READY_THREADS);
int decayed_ready_threads = div_x_by_n(fp_ready_thread,60);
LOAD_AVG = add_x_and_y(decayed_load_avg,decayed_ready_threads); // update load average in every sec
update_recent_cpu();
}
if ( timer_ticks() % 4 == 0){ // 4틱 마다
recompute_priority(); // recompute the priority of all threads
}
intr_set_level (old_level);
}
}
3. recent_cpu, priority 갱신 함수 추가
void
update_recent_cpu(void){
struct list_elem *e;
struct thread *thrd;
int decay_factor = div_x_by_y(mul_x_by_n(LOAD_AVG,2),add_x_and_n(mul_x_by_n(LOAD_AVG,2), 1));
thread_current()->recent_cpu = add_x_and_n(mul_x_by_y(decay_factor,thread_current()->recent_cpu),thread_current()->nice);
for (e = list_begin (&ready_list); e != list_end (&ready_list); e = list_next (e)){
thrd = list_entry(e,struct thread,elem);
thrd->recent_cpu = add_x_and_n(mul_x_by_y(decay_factor,thrd->recent_cpu),thrd->nice);
}
for (e=list_begin(&sleep_list); e != list_end(&sleep_list); e = list_next(e)){
thrd = list_entry(e,struct thread,elem);
thrd->recent_cpu = add_x_and_n(mul_x_by_y(decay_factor,thrd->recent_cpu),thrd->nice);
}
}
void
recompute_priority(void){
struct list_elem *e;
struct thread *thrd;
thread_current()->priority = convert_x_to_int_round_to_nearest(sub_n_from_x(sub_y_from_x(convert_n_to_fp(PRI_MAX),(div_x_by_n(thread_current()->recent_cpu,4))),(2 * thread_current()->nice)));
for (e = list_begin (&ready_list); e != list_end (&ready_list); e = list_next (e)){
thrd = list_entry(e,struct thread,elem);
thrd->priority = convert_x_to_int_round_to_nearest(sub_n_from_x(sub_y_from_x(convert_n_to_fp(PRI_MAX),(div_x_by_n(thrd->recent_cpu,4))),(2 * thrd->nice)));
if (PRI_MAX < thrd->priority) thrd->priority = PRI_MAX;
else if (PRI_MIN > thrd->priority) thrd->priority = PRI_MIN;
}
for (e=list_begin(&sleep_list); e != list_end(&sleep_list); e = list_next(e)){
thrd = list_entry(e,struct thread,elem);
// recent_cpu를 fp로 바꿀까?
thrd->priority = convert_x_to_int_round_to_nearest(sub_n_from_x(sub_y_from_x(convert_n_to_fp(PRI_MAX),(div_x_by_n(thrd->recent_cpu,4))),(2 * thrd->nice)));
if (PRI_MAX < thrd->priority) thrd->priority = PRI_MAX;
else if (PRI_MIN > thrd->priority) thrd->priority = PRI_MIN;
}
}개선 사항
1. 너무 길다

위 식의 코드:
thread_current()->priority = convert_x_to_int_round_to_nearest(sub_n_from_x(sub_y_from_x(convert_n_to_fp(PRI_MAX),(div_x_by_n(thread_current()->recent_cpu,4))),(2 * thread_current()->nice)));
리팩토링 하기 싫은 코드다. 😡
급한 마음에 따로 변수를 선언하지 않고 한번에 쓰려다보니 너무 길어서 읽기가 어렵다.
만약 코드에 에러가 발생하면 디버깅이 쉽지 않을 것이다.
따라서 아래와 같이 리팩토링 할 수 있다.
int calculate_thread_priority(struct thread *thrd) {
int max_priority_fixed_point = convert_n_to_fp(PRI_MAX);
int recent_cpu_divided = div_x_by_n(thrd->recent_cpu, 4);
int priority_sub_part = sub_y_from_x(max_priority_fixed_point, recent_cpu_divided);
int nice_double = 2 * thrd->nice;
int priority = sub_n_from_x(priority_sub_part, nice_double);
return convert_x_to_int_round_to_nearest(priority);
}
// 함수 내에서 아래와 같이 함수를 호출하여 priority를 갱신
thrd->priority = calculate_thread_priority(thrd);2. 비슷한 구조의 두 함수
update_recent_cpu, recompute_priority 두 함수는 똑같이 running thread와 ready_list,sleep_list를 탐색하며 갱신을 시켜준다. 따라서 중복되는 코드가 존재하므로, 함수를 새로 만들어 인자를 넘겨주는 방식으로 리팩토링할 수 있다.
void process_threads_in_list(struct list *thread_list, void (*thread_action)(struct thread *t, void *arg), void *arg) {
struct list_elem *e;
for (e = list_begin(thread_list); e != list_end(thread_list); e = list_next(e)) {
struct thread *thrd = list_entry(e, struct thread, elem);
thread_action(thrd, arg);
}
}
void update_thread_recent_cpu(struct thread *thrd, void *arg) {
int decay_factor = *(int *)arg;
thrd->recent_cpu = add_x_and_n(mul_x_by_y(decay_factor, thrd->recent_cpu), thrd->nice);
}
void recompute_thread_priority(struct thread *thrd, void *arg UNUSED) {
thrd->priority = calculate_thread_priority(thrd);
if (PRI_MAX < thrd->priority) thrd->priority = PRI_MAX;
else if (PRI_MIN > thrd->priority) thrd->priority = PRI_MIN;
}
void update_recent_cpu(void) {
int decay_factor = div_x_by_y(mul_x_by_n(LOAD_AVG, 2), add_x_and_n(mul_x_by_n(LOAD_AVG, 2), 1));
update_thread_recent_cpu(thread_current(), &decay_factor);
// 리스트 내부의 스레드들의 recent_cpu 업데이트
process_threads_in_list(&ready_list, update_thread_recent_cpu, &decay_factor);
process_threads_in_list(&sleep_list, update_thread_recent_cpu, &decay_factor);
}
void recompute_priority(void) {
recompute_thread_priority(thread_current(), NULL);
// 리스트 내부의 스레드들의 우선순위 업데이트
process_threads_in_list(&ready_list, recompute_thread_priority, NULL);
process_threads_in_list(&sleep_list, recompute_thread_priority, NULL);
}걱정
for문 내부에서 thread action함수가 리스트의 크기만큼 호출되서 오히려 오버헤드가 너무 커지는 거 아니야?🤔
해결
컴파일러 최적화
현대 컴파일러는 함수 호출과 관련된 오버헤드를 최소화하기 위한 다양한 최적화 기법을 사용한다. 특히 작은 함수의 경우, 인라인화(inline)를 통해 함수 호출이 실제 코드 내에 직접 삽입되어 오버헤드가 감소한다.
성능 대 가독성 및 유지보수성의 트레이드오프
코드의 재사용성과 유지보수성을 높이는 것은 종종 약간의 성능 저하를 수반할 수 있지만, 이는 대부분의 애플리케이션에서 받아들일 만한 수준이다. 특히, 코드가 더 깔끔하고 관리하기 쉬워지면, 장기적으로 소프트웨어의 품질과 유지보수가 향상된다.
TIP
tests/threads/tests.c 파일에서 원하지 않는 테스트는 주석처리하여 make check 시 시간을 줄일 수 있다.
static const struct test tests[] =
{
{"alarm-single", test_alarm_single},
{"alarm-multiple", test_alarm_multiple},
{"alarm-simultaneous", test_alarm_simultaneous},
{"alarm-priority", test_alarm_priority},
{"alarm-zero", test_alarm_zero},
{"alarm-negative", test_alarm_negative},
{"priority-change", test_priority_change},
{"priority-donate-one", test_priority_donate_one},
{"priority-donate-multiple", test_priority_donate_multiple},
{"priority-donate-multiple2", test_priority_donate_multiple2},
{"priority-donate-nest", test_priority_donate_nest},
{"priority-donate-sema", test_priority_donate_sema},
{"priority-donate-lower", test_priority_donate_lower},
{"priority-donate-chain", test_priority_donate_chain},
{"priority-fifo", test_priority_fifo},
{"priority-preempt", test_priority_preempt},
{"priority-sema", test_priority_sema},
{"priority-condvar", test_priority_condvar},
// {"mlfqs-load-1", test_mlfqs_load_1},
// {"mlfqs-load-60", test_mlfqs_load_60},
// {"mlfqs-load-avg", test_mlfqs_load_avg},
// {"mlfqs-recent-1", test_mlfqs_recent_1},
// {"mlfqs-fair-2", test_mlfqs_fair_2},
// {"mlfqs-fair-20", test_mlfqs_fair_20},
// {"mlfqs-nice-2", test_mlfqs_nice_2},
// {"mlfqs-nice-10", test_mlfqs_nice_10},
// {"mlfqs-block", test_mlfqs_block},
};예를 들어, mlfqs와 관련된 테스트는 시간이 오래걸리기 때문에, 위 처럼 주석화하면 시간이 훨씬 단축된다.
결과