환경 모델이 필요 없는 model-free에 대해서 알아본다.
model-based에서는 planning이 중요하지만

model-free에서는 learning이 중요하다
공통점으로는 value function을 계산한다는 점.
미래의 사건을 내다보고 backed-up value를 계산하여
그것을 estimated value function을 위한 update goal로 사용한다.
이전까지는 MC와 TC를 구별한 뒤, n-step 방법으로 통합됨을 보였다.
여기서는 통합된 모델과 model-free가 어떻게 융합되는지 알아보려 한다.
Model & Planning
Model
- distribution model : 모든 가능성을 제공하고, 각 가능성에 해당하는 확률을 제공하는 모델
시작 상태와 정책이 주어지면, distribution model은 모든 가능한 에피소드와 그들의 확률를 생성
고로, simulated experience을 만들기 위해 모델을 사용
ex) 블랙잭 - sample model : 모든 가능성 중 확률에 따라 추출된 하나의 가능성만을 제공하는 모델
시작 상태와 정책이 주어지면, sample model은 하나의 완전한 에피소드를 도출함
고로,환경을 시뮬레이션하기 위해 모델을 사용
ex) 주사위

Planning & Learning
- Planning : 계획이 모델로부터 생성된 시뮬레이션된 경험을 사용한다
- Learning : 환경으로부터 생성된 진짜 경험을 이용한다
Planning
== 모델링된 환경과의 상호작용을 위해 모델을 입력으로 하여 정책 생성 및 향상 시키는 모든 계산 과정
- state-space planning : 주로 최적 정책이나 목표를 향한 최적 경로를 찾기 위해 상태 공간 탐색
행동을 통해 상태에서 상태로 전이하고 가치함수가 각 상태에 대해 계산된다 - plan-space planning : plan-space에 대한 탐색을 통해, 학습자는 한 계획에서 다른 계획으로 전이하고, 가치함수가 존재한다면 그것은 plan-space에서 정의된다.
stochastic sequential decision을 적용하기 어렵기에 강화학습에서 잘 사용되지 않음.
State-Space Planning
- 모든 상태 공간 계획법은, 가치 함수 계산을 정책 향상을 위한 핵심 단계로 포함해야 함
- 이 방법은 시뮬레이션된 경험에 적용된 갱신 또는 보강 과정에 의해, 가치 함수를 계산한다.
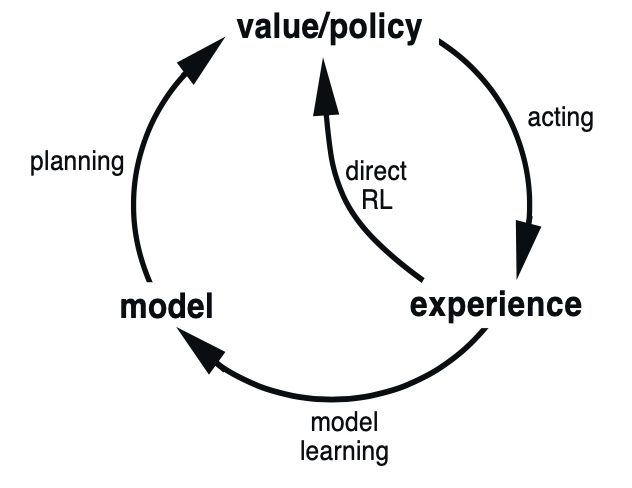
Dyna: Intergration of Plan, Action, Learn
- model-learning : 실제 경험은 모델 향상에 사용됨
- direct reinforcement learning : 이전 장에서 논의한 강화학습 방법을 이용하여 가치 함수와 정책을 직접 향상시킴
훨씬 더 간단하고 모델 설계에 의한 편차에 영향을 받지 않음. - indirect reinforcement learning : 모델을 통해서 경험이 가치 함수와 정책을 간접적으로 향상시킴
종종 제한된 경험을 좀 더 충실히 이용해서 환경과 더 적게 상호작용하고도 더 좋은 정책을 획득
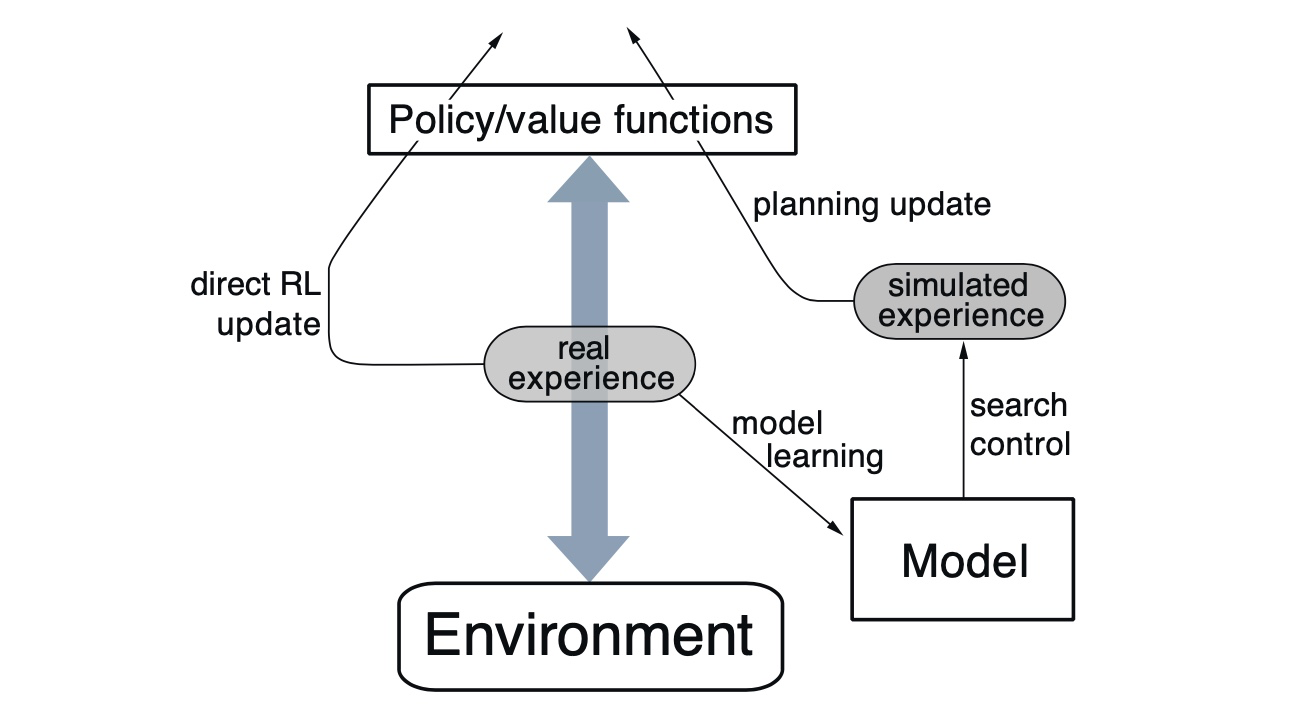
Dyna Q에서는 실제 경험이 환경과 정책 사이를 왔다갔다 하며
정책과 가치함수에 영향을 준다
이는 환경 모델이 생성한 시뮬레이션된 경험과 같은 방식이다.
그리고 정책과 가치함수에 실제 경험을 직접적으로 이용하면서
모델에서 생성된 시뮬레이션된 경험을 통해 계획을 갱신한다.
Dyna Q + : Bonus
탐험과 활용 간 trade-off를 푸는 새로운 방법의 하나.
계획에서
탐험은 모델 향상을 위한 행동을 시도하는 것이지만,
활용은 현재 모델을 기반으로 최적의 방식으로 행동하는 것을 의미한다.
즉, 학습자가 환경의 변화를 찾기 위한 탐험을 원하지만 이로인한 큰 성능 저하는 원하지 않는다.
그래서 오랫동안 시도되지 않은 행동에 대한 시뮬레이션된 경험에
bonus reward를 부여한다.
시간 동안 전이가 일어나지 않았을 때 만큼 보상에 보너스를 추가한다.
이는 학습자로 하여금 접근 가능한 모든 상태 전이에 대해 계속 테스트하고,
이에 필요한 긴 행동의 나열을 찾도록 장려한다.
