MobileViT
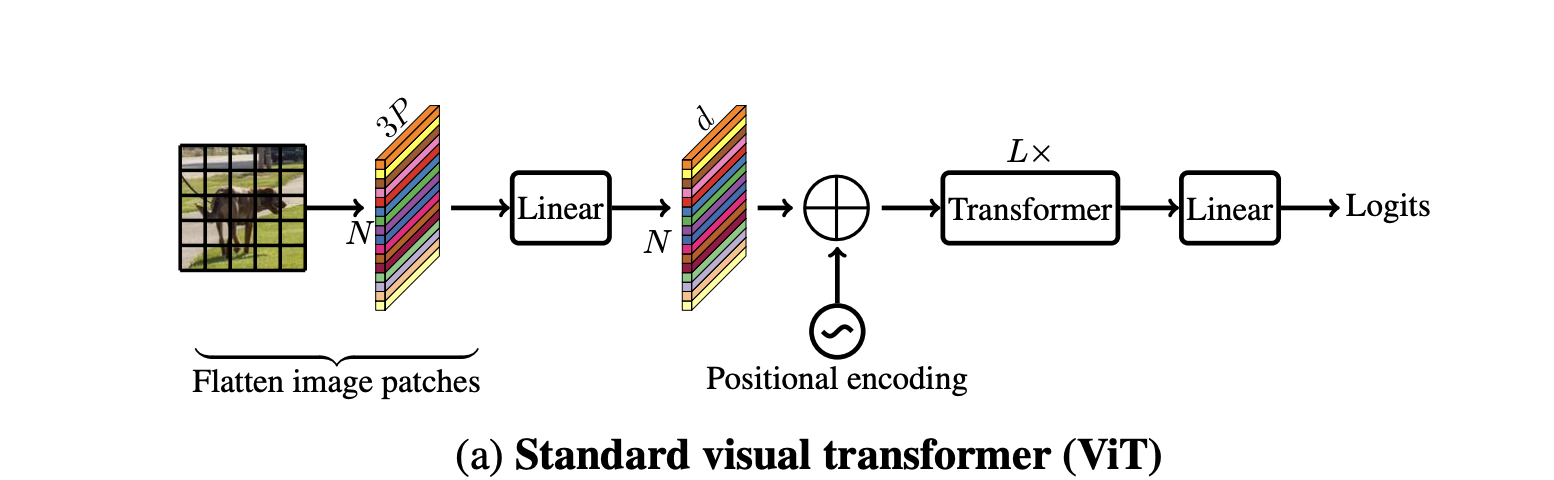
CNN vs ViT
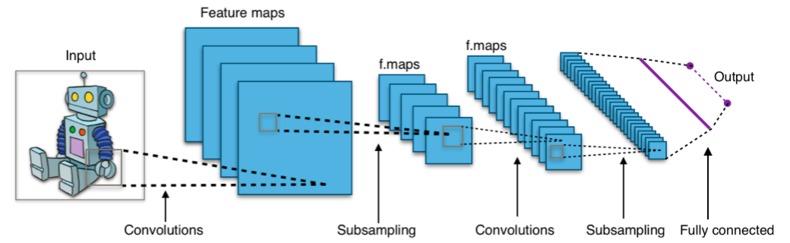
위의 그림은 CNN이고 아래 그림은 ViT이다
CNN은 전체 이미지를 조금씩 보면서 강조할 부분만 모아가면 점점 작아진다
ViT는 이와 다르게 전체 이미지를 처음부터 잘게 쪼갠 뒤 일렬로 들어간다
Transformer는 자연어처리에서 나온 방식이며, 한 문장을 만들기 위해 한 단어 씩 넣는 입력값으로 넣는다.
이를 이미지 처리에도 적용하기 위해 이미지를 일렬로 만드는 것이다
여기서 쪼갠 이미지 조각을 patch라고 한다
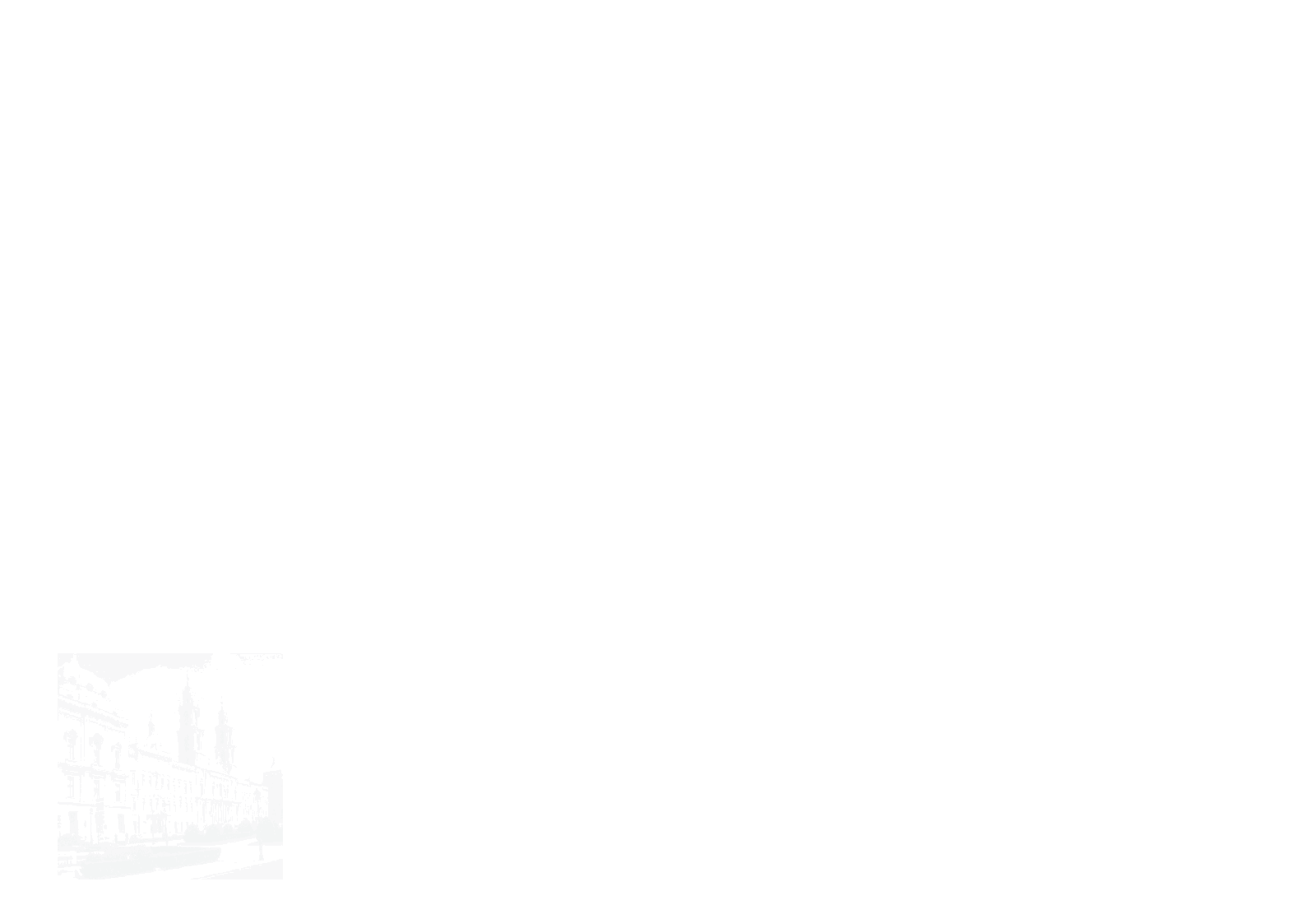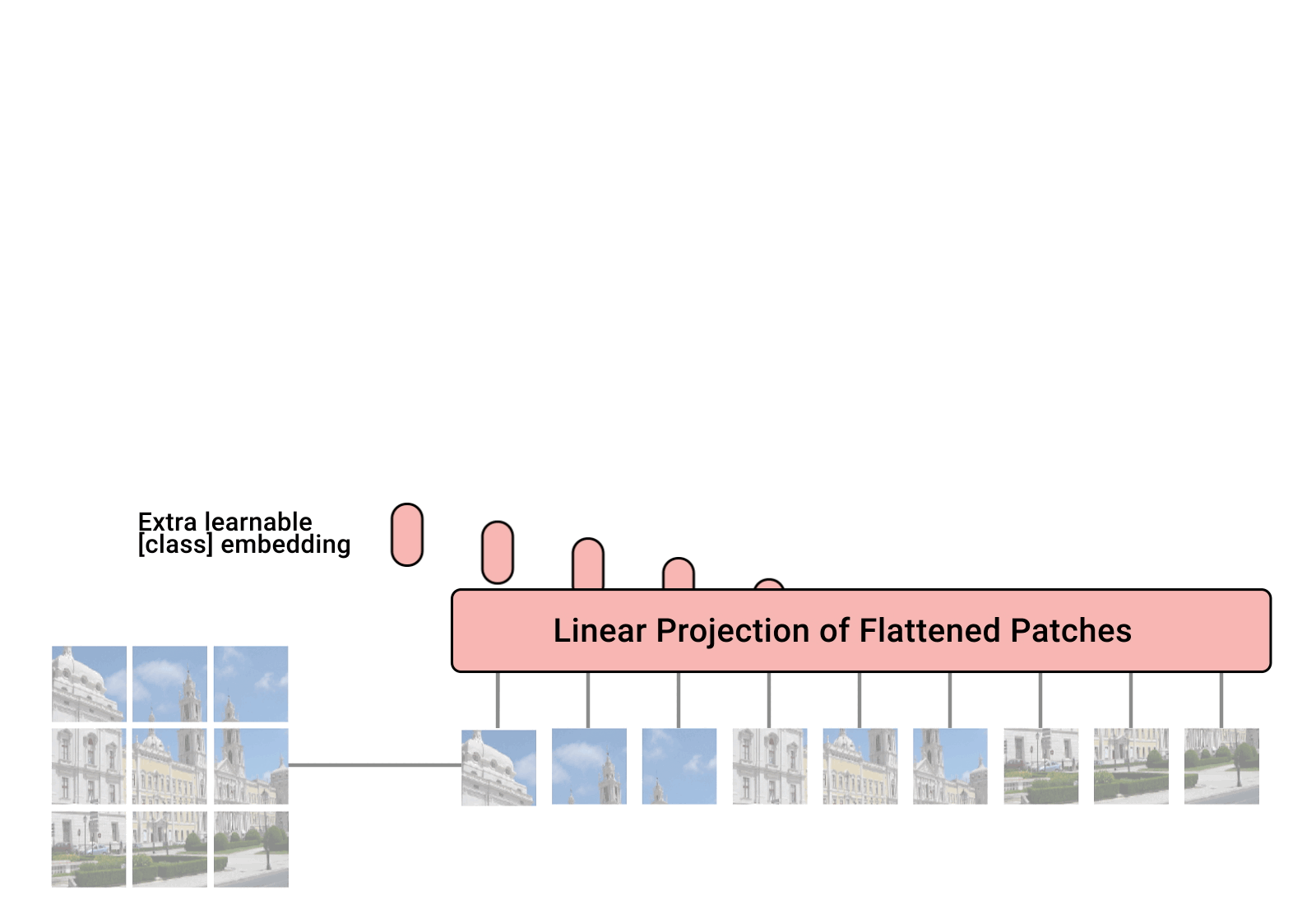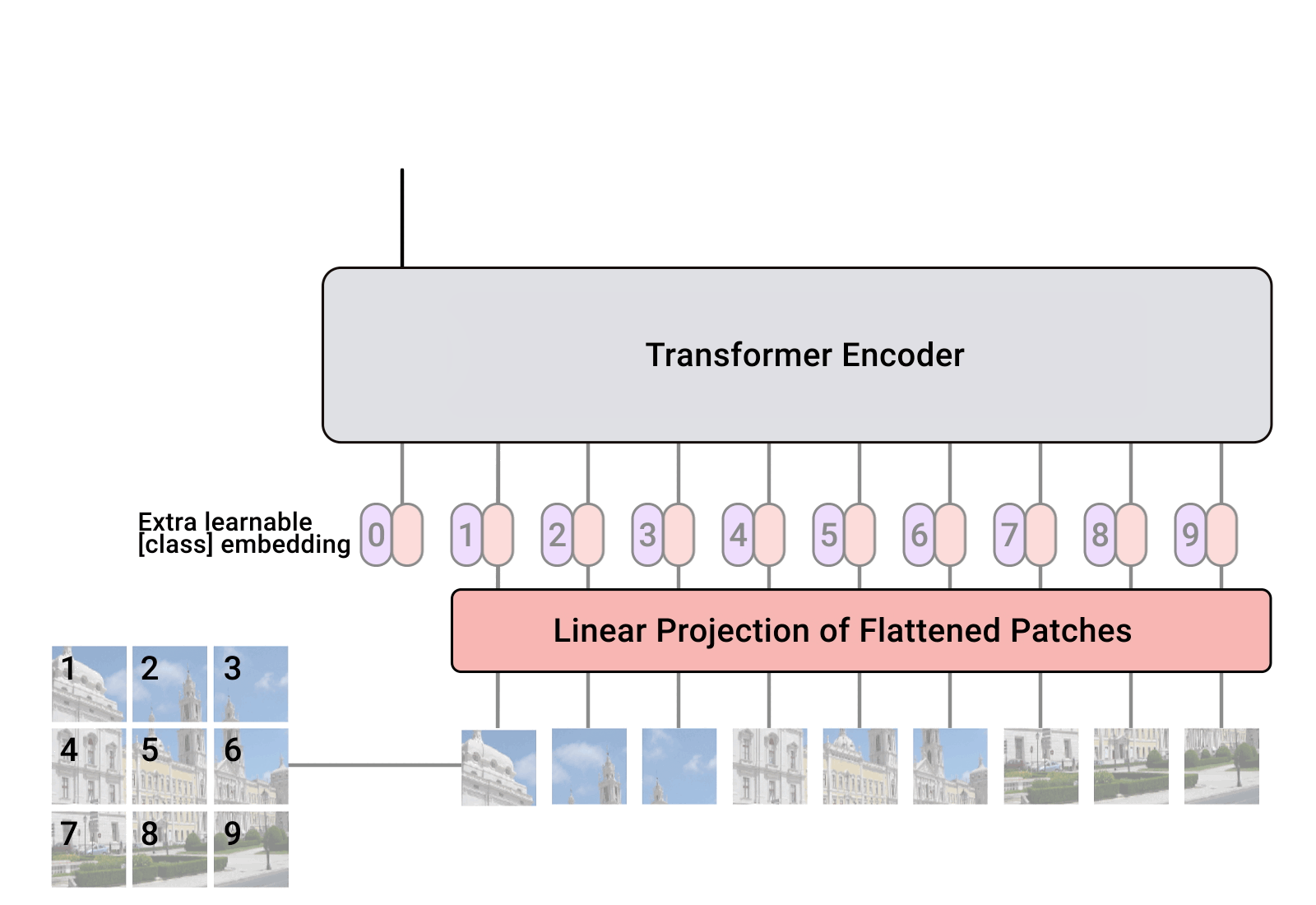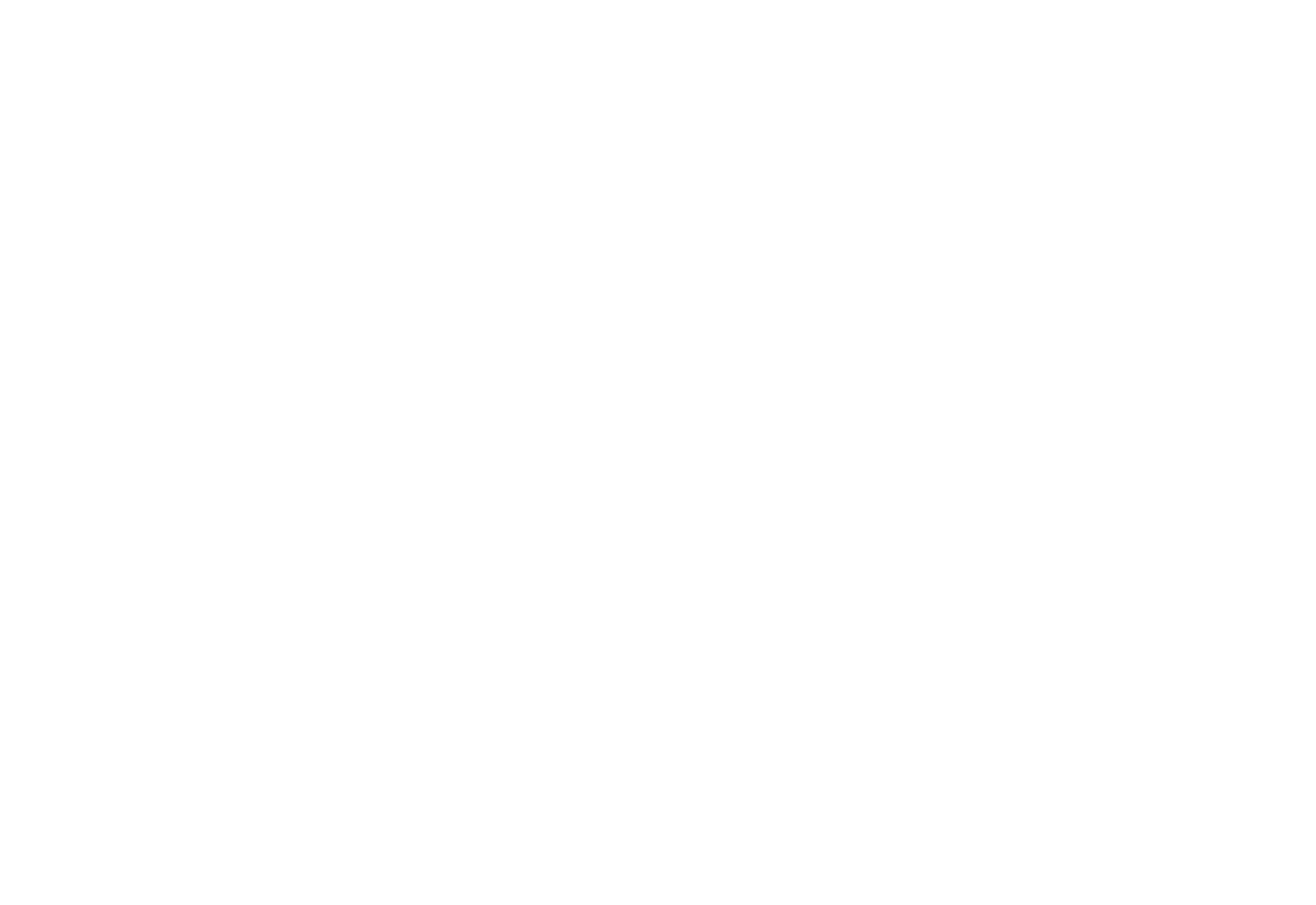
Introduction
일반적인 Convolution은 3단계로, unfolding, local processing, folding을 거친다.
여기서 MobileViT는 global information도 얻기 위해 local processing (matrix multiplication)을 global processing (a stack of transformer layers)를 이용한 global processing으로 교체했다
덕분에 CNN의 장점인 spatial inductive bias가 ViT에 적용되었다
더불어 실험해보니 MobileViT를 다른 모델의 backbone 모델로 교체해서 썼을 때 성능이 좋아진다는 점도 발견했다.
- ViT 구조
- MobileViT 구조
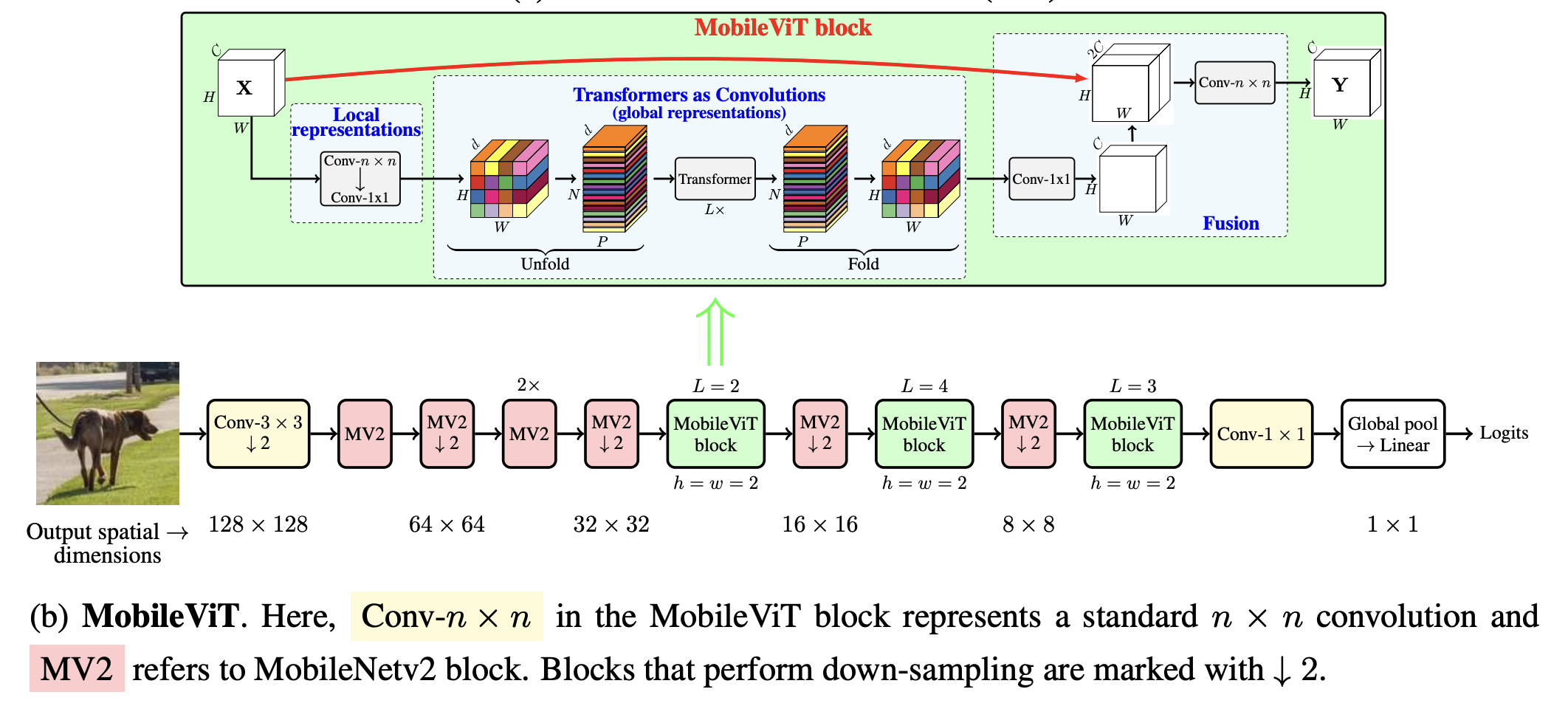
MobileViT Architecture
계산량(Computational cost)는 ViT와 MobileViT를 비교해보았을 때 각각 O(N^2d), O(N^2Pd)로 MobileViT가 비효율적이다. 그러나 ViT보다 가볍게 구성되었기에 training efficiency는 실제로 더 낫다.
MobileViT 속 MobileViT2(MV2) 블록은 주로 down-sampling 역할을 하며 이 덕분에 MobilViT가 더 얕아지고 좁아졌다. 그래서 light-weight할 수 있었다
CNN과 유사하기에 ViT에서는 필요한 positional embedding이 요구되지 않는다.
그래서 multi-scale inputs에 이점을 보인다. 또한 batch-size를 크게하면 spatial resolutions은 더 작아진다. 그래서 optimizer가 매 epoch마다 적게 업데이트하고 더 빠르게 훈련할 수 있게 된다.
검은색 선은 각 patch를 의미하며, 회색선은 각 픽셀을 의미한다.
중앙의 빨간색 픽셀은 다른 patch에 들어있는 픽셀을 본다.
아래 그림에서 blue 픽셀을 보게 되는 것.
이는 transforemer 덕분에 다른 patch의 위치를 알 수 있다.
그럼 하나의 patch 안에서 각각의 픽셀의 위치정보를 아는 것은 CNN 덕분이다.
그림 상에서 각 파란색 픽셀 주변의 파란 화살표를 의미하는 것.
그렇게 MobilViT는 전체 픽셀의 위치 정보를 인식할 수 있다.

Multi-scale Sampler for Training Efficiency
기존 ViT 모델은 positional embedding 과정에 필요하였기에 fine-tunning을 해야 했지만
MobileViT는 positional embedding이 필요없기에 fine-tunning도 필요없어졌다
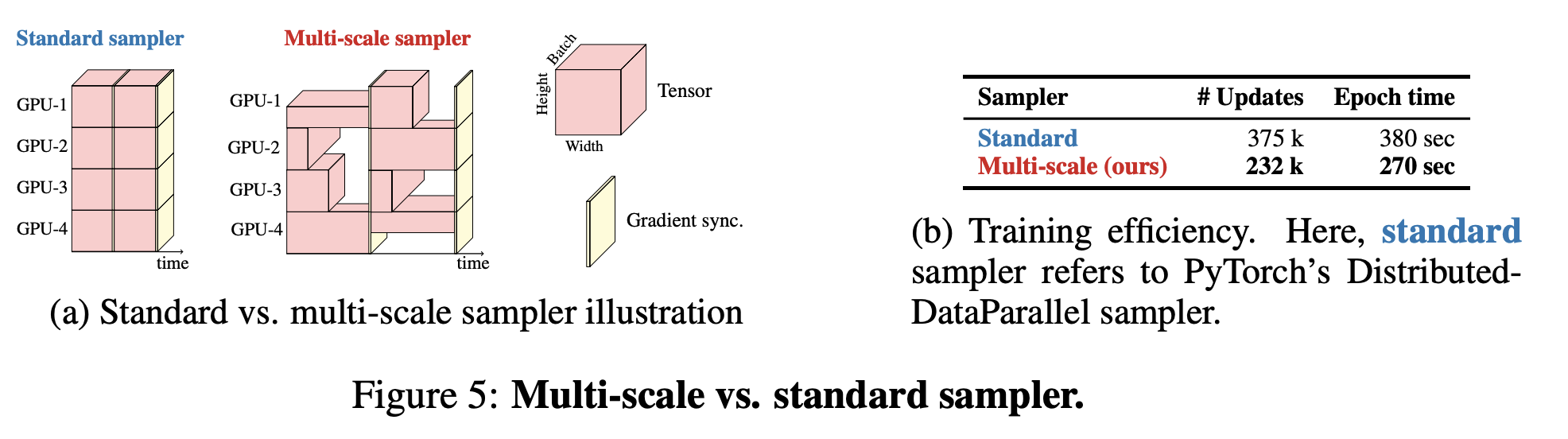
MobileViT는 CNN의 Multi-scale Sampler 방법을 차용해왔다
Multi-scale은 여러 해상도의 이미지들을 처리할 수 있음을 의미한다
CNN에서는 이를 위해 작은 이미지는 up-sampling을, 큰 이미지는 down-sampling을 한다
여기서는 작은 spatial resolution을 가지면 큰 batch size를 선택한다. 또한 GPU 별로 하나의 spatial resolution을 랜덤하게 sampling한다
이 덕분에 optimizer의 update 횟수가 줄어들어 빠르게 training할 수 있게 된다
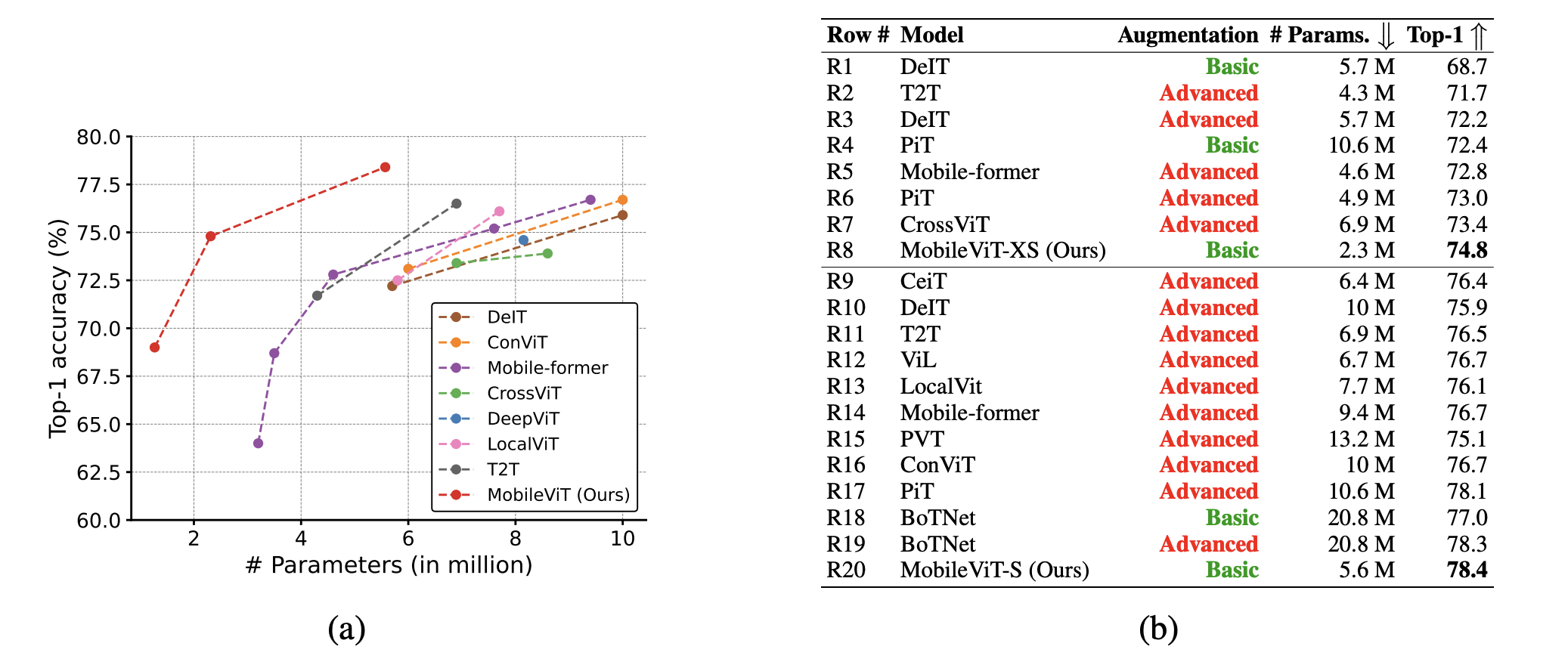
Result
CNN과 비교해보니 가벼운 CNN 중 하나인 EfficientNet-B0와 비교하였을 때 조금 더 나은 성능을 보였다.
MobileNet과 비교해보았을 때 parameter 수는 반으로 줄었지만 성능 면에서 1/5배 나았다.
MobileViT는 더 적은 parameter를 가지고 basic augmentation일 때 높은 성능을 보인다.
구현 코드 및 모델
