
경험을 통해 학습하는 점에 있어 다른 머신러닝 기법과 다르다
모델 스스로 생성한 결과를 학습에 이용한다는 점
자신의 행동에 대해
상점과 벌점을 통한 보상을 바탕으로
다음 행동을 결정하는 방식
이를 위해 시간에 따른 결과를 받을 수 있는
환경이 조성되어야만 구현할 수 있다
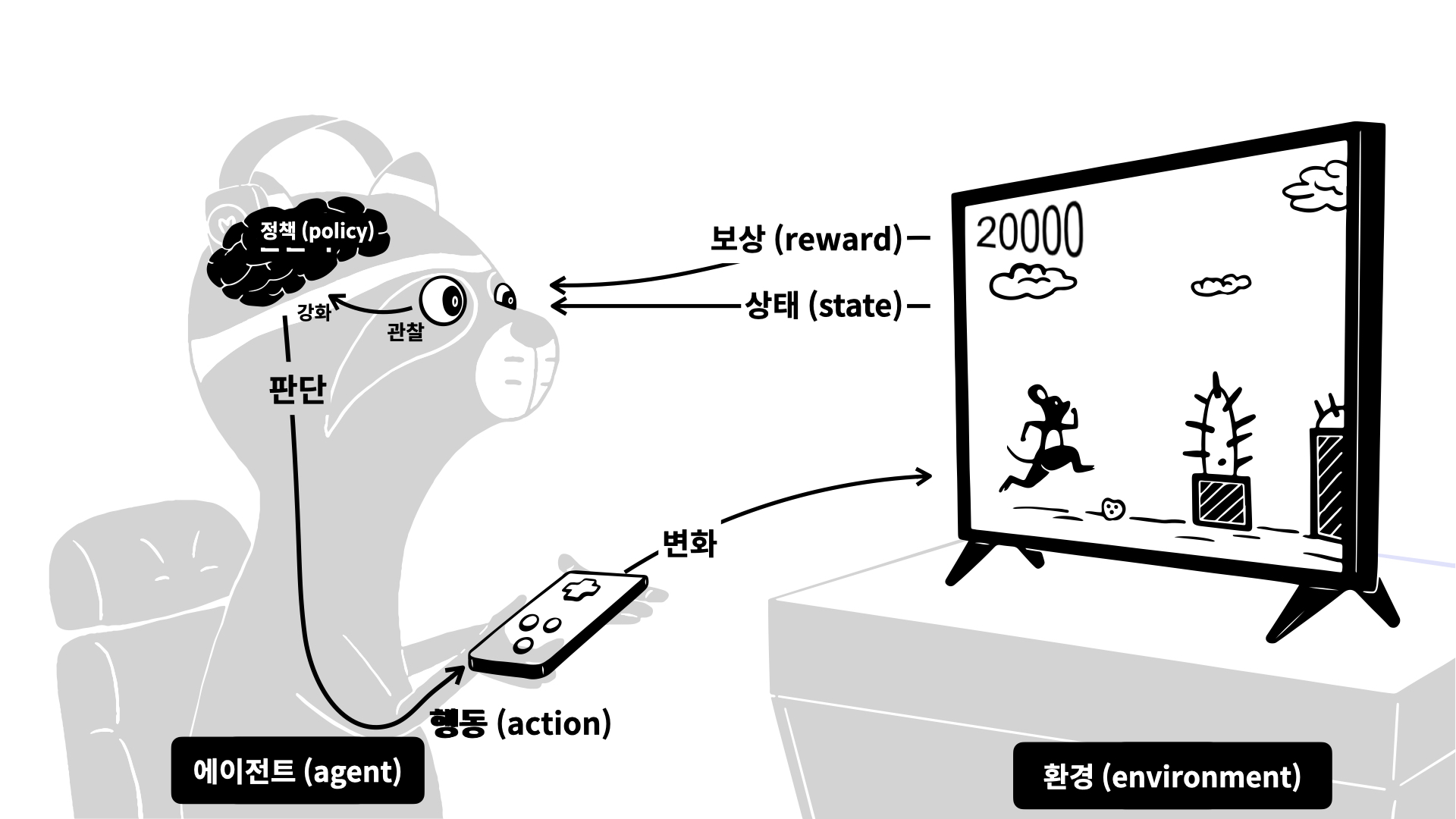
가볍게 설명하면 다음과 같다
아래 그림을 바탕으로 보면
- agent가 어떤 action을 취하냐에 따라 게임의 진행은 달라진다
- 즉, environment(게임)에서 특정 action에 따라 특정 state에 가게 된다
- 그 action에 대한 점수는 reward를 통해 agent에게 돌아온다
- 방금 했던 action에 대한 reward와 state를 바탕으로
- 다음에 어떤 action을 취해야하는지 policy를 기반으로 고민하여
- 다음 action을 정한다
이 과정을 반복하며 경험을 통해 self-learning을 하게 된다
여기서 (St, At, Rt) 각각 state, action, reward를 의미하며
이들을 묶은 튜플은 경험 experience라고 불린다
t가 0부터 끝까지 한 번 진행한 구간을 에피소드 episode라고 한다
한 에피소드 내 경험의 연속이자 누적을 궤적 trajectory는 𝝉 = ∑(St, At, Rt)
policy
일반적으로 확률론적으로 action을 선택. 각 action에 선택될 확률를 부여.
- 무조건 확률이 높은 action만 선택하다보면 지름길을 찾기 어렵다. 계속 갖고 있는 지식을 이용/활용 exploting 하지 않고 때로는 탐험 exploring을 통해 새로운 방식을 탐색할 필요가 있다
reward
각 state마다 reward가 지급된다
강화학습의 목표는 reward의 총합을 최대화하는 것
다른 시각에서 바라보면
해당 state에서 action이 무엇이면 좋을 지를 정하는 용도.
만약 policy가 선택한 action이 적은 reward를 가져온다면
유사한 상황에 다른 선택을 하도록 policy가 바뀔 수 있다
value
그 상태의 시작점에서부터 일정 시간 동안
학습자가 기대할 수 있는 reward의 총합
expected accumulative future reward
value function은
특정 state s에서 시작하고
그 이후로 policy를 따랐을 때
예상되는 reward들의 총합이다.
이는 장기적인 관점에서 무엇이 좋은지를 알려준다.
state s에서 어떤 action을 취해서
다음 state s'로 넘어가는지
policy에서 확률에 기반하여 선택하기에
정확한 값이 아닌 예상값/기대값으로 표현한다
- discount factor : 총 reward를 최대화를 목표로 두면 목표지점에 다가가기보다는 한 자리에서 맴돌게 된다. 이를 방지하기 위해 단계가 진행될 수록 그 reward를 점차 작아지게 하도록 진행된 단계의 수만큼 discount factor (0<=𝜸<=1) 를 reward에 곱한다.
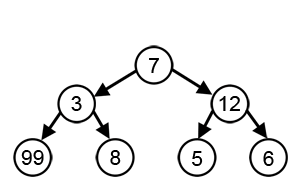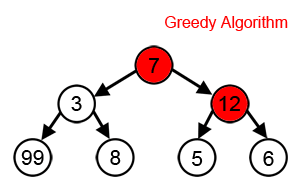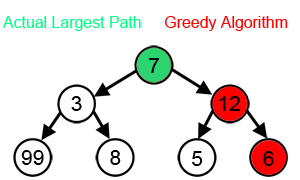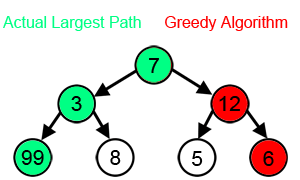
greedy action
컴퓨터 과학에서 'greedy (탐욕적)'이란,
장기적으로 더 좋은 대안을 선택할 수 있는 기회를 고려하지 않고
지엽적이거나 즉각적인 것만 고려하여 대안을 탐색하는
탐색 또는 결정 과정을 의미한다.
결과적으로, 그것은 오직 단기적인 결과만을 고려하여
action을 선택하는 policy를 말한다.
- 출처 : https://euresisjournal.org/what-is-the-difference-between-greedy-method-and-dynamic-programming
epsilon-greedy
'greedy action'이란
action의 가치(value)를 추정할 수 있다면
각 단계마다 추정 가치가 최대인 action을 하나 이상 결정하는 것.
- exploiting(활용) : action의 value에 대해 현재까지 갖고 있는 지식을 활용하는 것 == greedy action
- exploring(탐험) : greedy action이 아닌 다른 action을 선택하여 선택한 action의 추정 가치를 상승시키는 것
epsilon-greedy는 이 둘의 조합으로,
대부분의 시간 동안에는 greedy한 선택을 수행하고,
가끔씩 상대적 빈도수 epsilon을 작은 값으로 유지하면서
greedy한 선택이 아닌
모든 action을 대상으로 무작위 선택을 하는 것
Learning과 Planning
- Learning
- environment는 초기에 알려져 있지 않다
- agent는 그러한 environment와 상호작용한다
- Planning
- 그 environment의 model이 주어져있다. (또는 model을 학습했다)
- 이제 agent는 model 안에서 environment와 상호작용한다 (외부와의 상호작용 없이)
- next_state 경험 전에 가능성만 고려하여 action을 결정하는 방법
Model
environment가 다음에 어떻게 되는지, 무엇을 하는지 예측한다
현재 state와 그에 따른 action으로부터 next_state와 reward를 예측해준다.
next_state 경험 전에 가능성만 고려하여 action을 결정하는 방법을
planning(계획)이라고 한다.
- Model-based : model과 planning을 사용
- 환경이 어떻게 동작할지 기존 지식을 활용하거나 학습해서 사용
- 기존 지식을 활용하기에 적은 양의 데이터로 학습 가능
- 실제로 행동하기 전에 미리 변화를 예상해보고 최적의 행동을 계획하여 실행
- Model-free : 학습자의 시행착오로부터 model을 학습하고 동시에 사용하여 planning을 수행
- 특정 환경에 대한 model을 세우기 어려운 경우 사용
- 각 state의 state transition probability와 그에 따른 reward를 알 필요가 없음
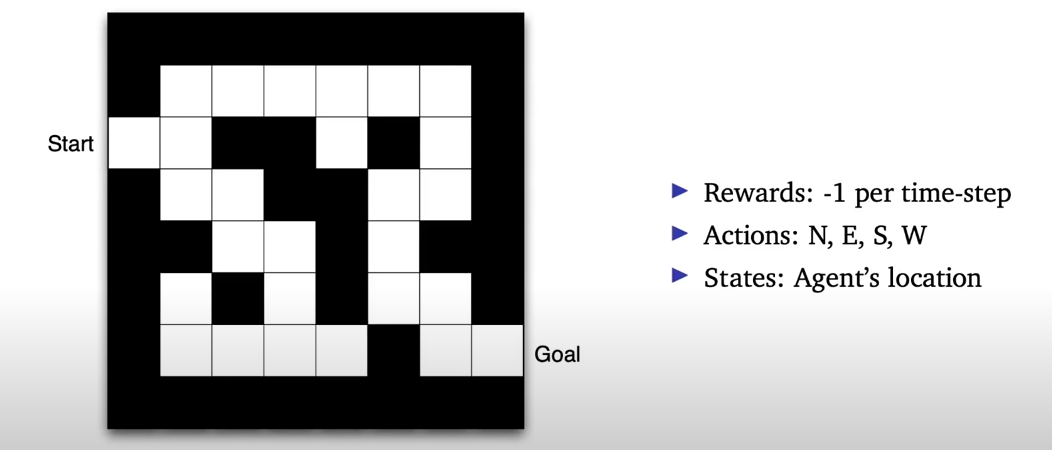
미로 예시
- reward: 한 발자국마다 -1
- action: 동,서,남,북
- state: grid 상에서 agent의 위치
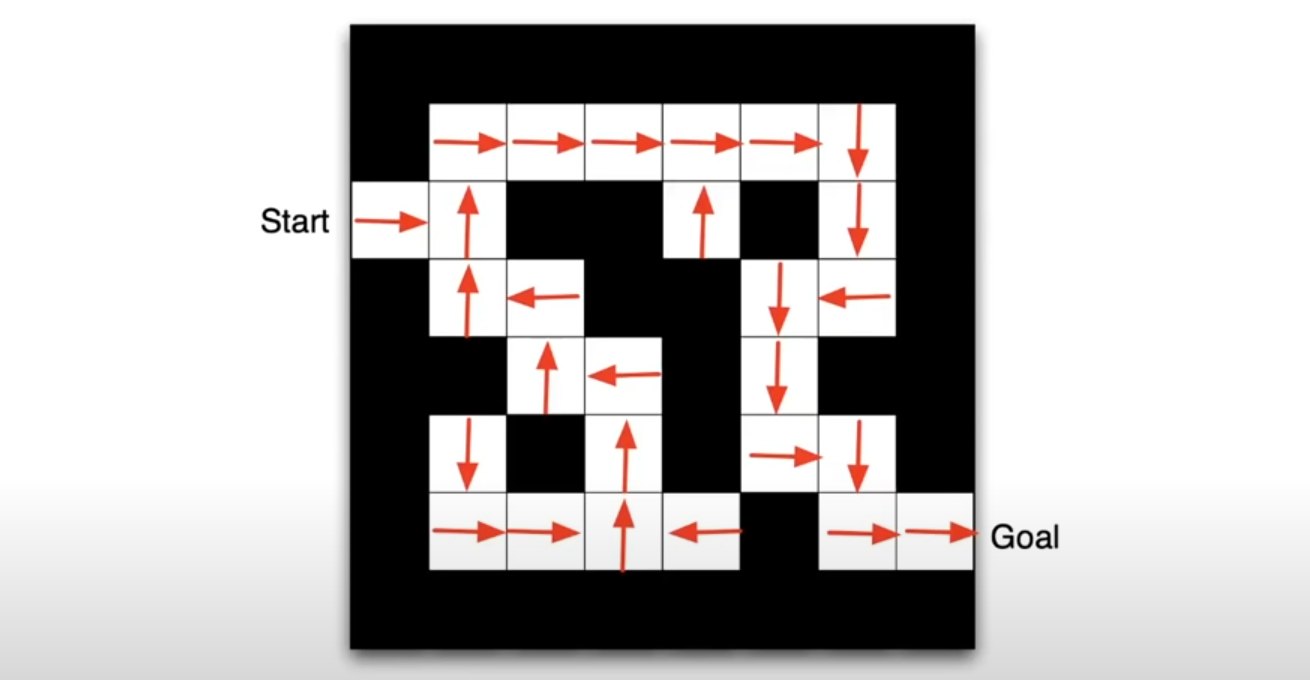
policy
빨간색 화살표는
각 state s에서의 policy를 의미
value
숫자들은
각 state s에서의 value를 의미

Model
grid는 다음에 나오는,
transition probability 를 의미
숫자들은
즉각적인 reward를 의미
(여기서는 모든 a와 s'에 대해 같은 reward를 취함)

기초 선형대수학
아래 링크에
행렬과 행렬 연산에 내용이 있으니 꼭 참고
너무 세세한 연산과 조건들까지는 중요하지 않음
예시만 참고해서 어떤 식으로 연산이 작동되고
행렬 간의 연산이 왜 선형이라고 불리는지 이해가 된다면 됐다
- http://db.kockoc.com/lec/Hard/g1.htm
- https://ko.wikipedia.org/wiki/%EC%A0%84%EC%B9%98%ED%96%89%EB%A0%AC
- https://thebook.io/080289/ch05/03/01-09/
